







DeepSeek R1之后的推理大模型后训练增强技术解析
作者:Sebastian Raschka|翻译:致Great@知乎
原文:https://magazine.sebastianraschka.com/p/state-of-llm-reasoning-and-inference-scaling
提升大型语言模型(LLM)的推理能力无疑是 2热的话题之一,而且理由很充分。更强的推理能力意味着 LLM 可以处理更复杂的问题,让它在各种任务上表现得更出色,更贴近用户的实际需求。
最近几周,研究人员提出了不少提升推理能力的新策略,比如增加推理时的计算量、强化学习、监督微调以及知识蒸馏等。而且,很多方法都会结合这些技术,以达到更好的优化效果。
本文将聚焦于 LLM 推理优化的最新研究进展,特别是自 DeepSeek R1 发布以来,关于推理时计算量扩展的相关方法和应用。
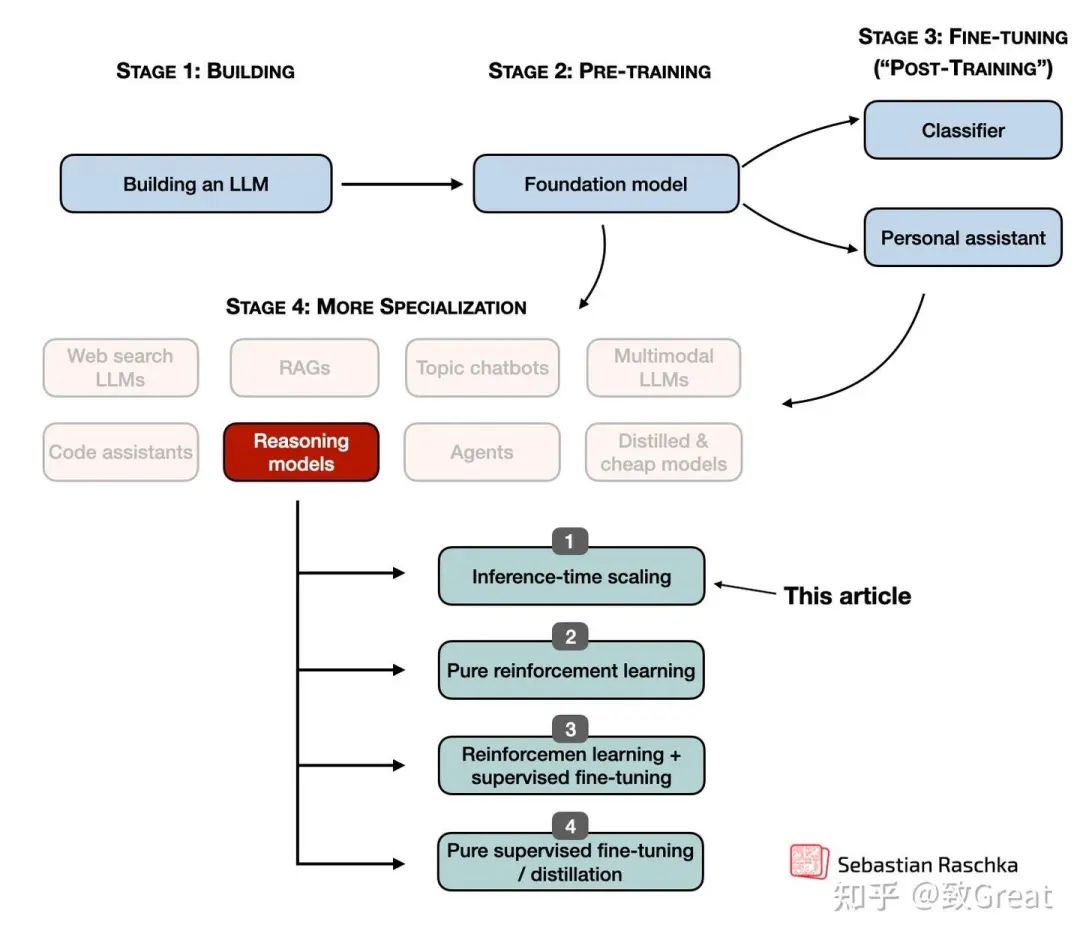
在 LLM 中实现和改进推理:四个主要类别
大多数读者对 LLM 推理模型可能已经比较熟悉,这里简单介绍一下它的定义。基于 LLM 的推理模型,主要是通过生成中间步骤或结构化的“思考”过程,来解决多步骤问题。不同于只给出最终答案的传统问答式 LLM,推理模型会在推理过程中展现其思考路径,或者在内部完成推理。这种方式让它在处理谜题、编程挑战、数学问题等复杂任务时,表现得更加出色。

一般来说,改进推理有两种主要策略:(1)增加 训练 计算量,或(2)增加 推理 计算量,也称为 推理时扩展 或 测试时扩展 。
推理计算量是指在训练后,为响应用户查询而生成模型输出所需的处理能力。
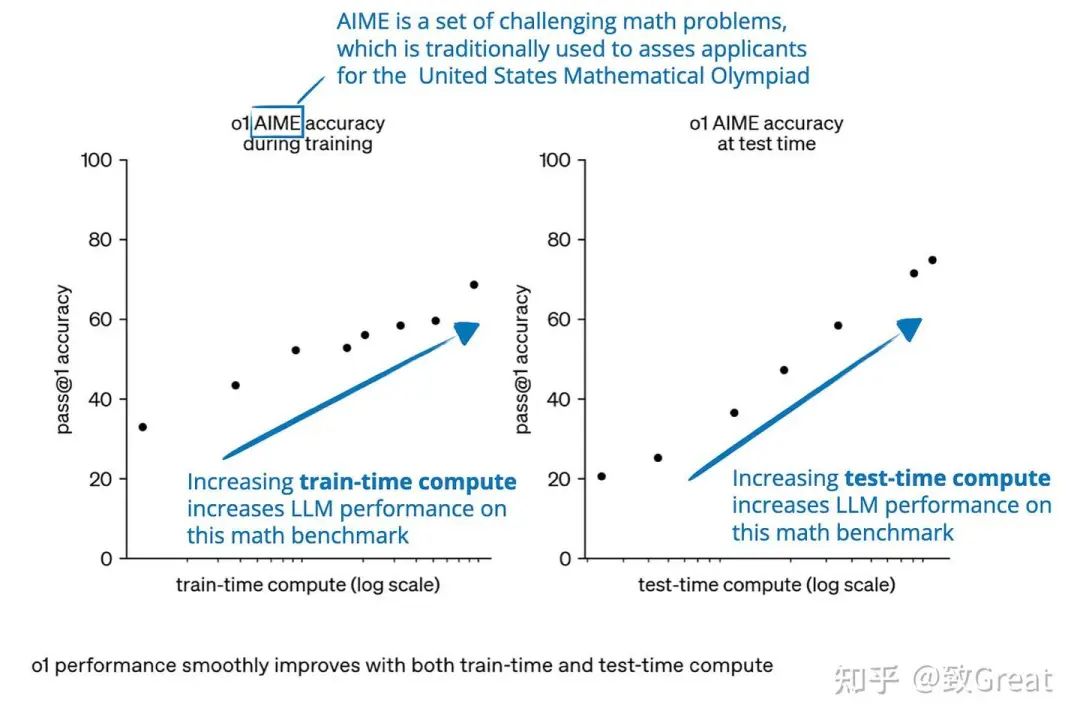
请注意,上面显示的图表看起来好像我们通过训练时计算量或测试时计算量来改进推理。然而,LLM 通常旨在通过结合大量的训练时计算量(广泛的训练或微调,通常使用强化学习或专门数据)和增加的测试时计算量(允许模型在推理期间“思考更长时间”或执行额外计算)来改进推理。
要了解推理模型是如何被开发和优化的,分别拆解不同的技术仍然是一个高效的思路。在此前的文章 理解推理 LLM[1] 中,对推理 LLM 进行了更细致的分类,并将其归纳为四个主要类别,如下图所示。

上图中的方法 2-4 通常会让 LLM 生成更长的回答,因为这些方法在输出中加入了中间步骤和解释。而由于推理成本通常与响应长度成正比(比如,响应长度翻倍,计算量也会相应增加一倍),这些训练策略本质上与推理扩展密切相关。不过,在这一部分关于推理时计算量扩展的讨论中,重点将放在那些可以直接控制生成 token 数量的技术,比如额外的采样策略、自我纠正机制等。
本文主要关注 2025 年 1 月 22 日 DeepSeek R1 发布之后,围绕推理时计算量扩展的最新研究和模型进展。(原本计划涵盖所有类别的方法,但篇幅过长,因此决定将训练时计算量相关的方法留到后续的专门文章中。)
在我们研究推理时计算量扩展方法以及推理模型的不同进展领域(重点是推理时计算量扩展类别)之前,让我至少简要概述一下所有不同的类别。
1. 推理时计算量扩展
这一类方法主要聚焦于在推理阶段提升模型的推理能力,而无需重新训练或修改底层模型的权重。核心思路是在计算资源的投入和模型性能提升之间找到平衡,通过思维链推理(Chain-of-Thought Reasoning)以及各种采样策略等技术,让即使是固定的模型也能更强大。
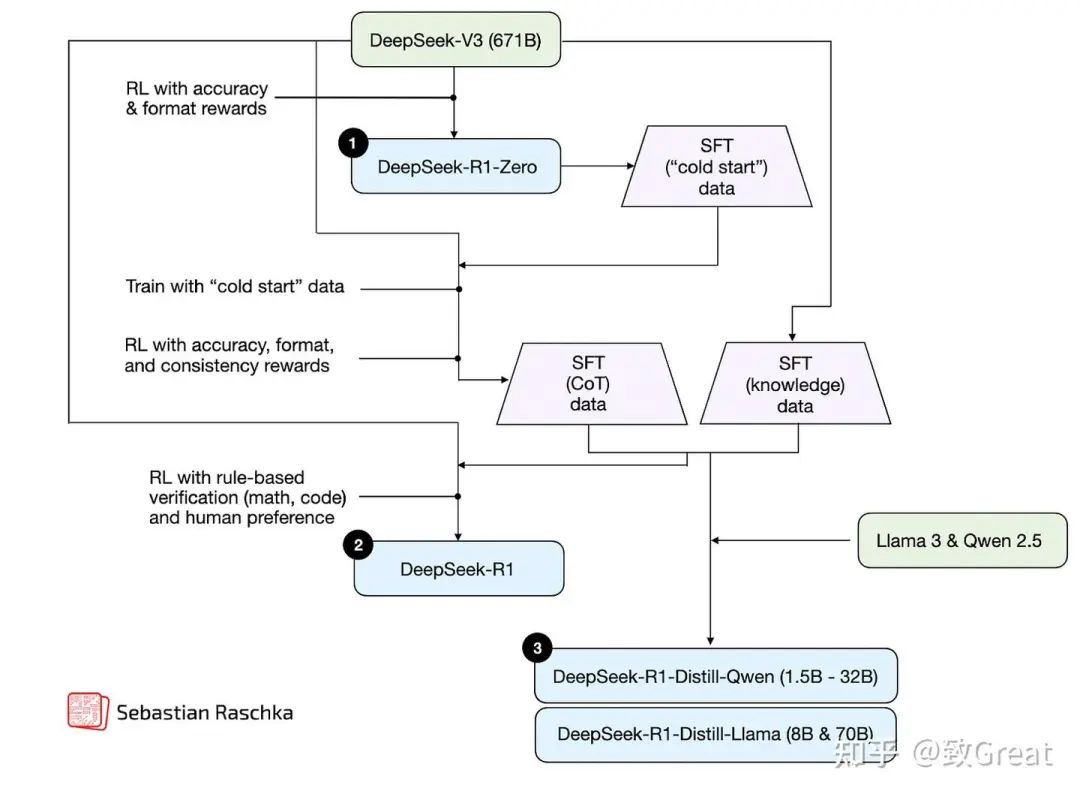
尽管推理时计算量扩展被单独归类,以便更专注于这类技术的应用,但实际上,它可以适用于任何 LLM。例如,OpenAI 在训练 o1 模型时采用了强化学习,同时也运用了推理时计算量扩展的方法。而值得注意的是,DeepSeek R1 论文中明确提到,该模型并未使用推理时扩展技术,但他们也承认,这类技术可以轻松集成到 R1 的部署或应用中。这一点在之前的文章 理解推理 LLM[2] 也有详细讨论。
2. 纯强化学习
此方法仅专注于强化学习 (RL) 来开发或改进推理能力。它通常涉及使用来自数学或编码领域的、可验证的奖励信号来训练模型。虽然强化学习允许模型发展更具战略性的思维和自我改进能力,但它也面临着诸如奖励黑客攻击、不稳定性和高计算成本等挑战。
3. 强化学习和监督微调
这种混合方法将强化学习 (RL) 与监督微调 (SFT) 相结合,以实现比纯强化学习更稳定和更通用的改进。通常,首先使用 SFT 在高质量的指令数据上训练模型,然后使用 RL 进一步改进以优化特定行为。
4. 监督微调和模型蒸馏
此方法通过在高质量的标记数据集 (SFT) 上进行指令微调来提高模型的推理能力。如果此高质量数据集由更大的 LLM 生成,则此方法也称为 LLM 环境中的“知识蒸馏”或简称为“蒸馏”。但是,请注意,这与深度学习中的传统知识蒸馏略有不同,后者通常涉及不仅使用较大教师模型的输出(标签),还使用 logits 来训练较小的模型。
推理时计算量扩展方法
上一节已经对推理时计算量扩展做了简要总结,在深入探讨该领域的最新研究之前,先更详细地介绍一下这一概念。
推理时扩展的核心思路是在推理过程中增加计算资源(即“计算量”),从而提升 LLM 的推理能力。为什么这能有效?可以用一个简单的类比来解释:人类在思考时间更充裕时,往往能给出更精准的答案,同样地,LLM 也可以通过一些技术,在生成过程中进行更多“思考”,从而优化推理效果。
其中一种方法是提示工程,比如思维链(Chain-of-Thought, CoT) 提示。在提示中加入类似“逐步思考”的短语,可以引导模型生成中间推理步骤,从而提高复杂问题的准确性。不过,这种方法对于简单的日常查询来说并不必要,而且由于 CoT 提示会让模型生成更多 token,实际上也会提高推理成本。

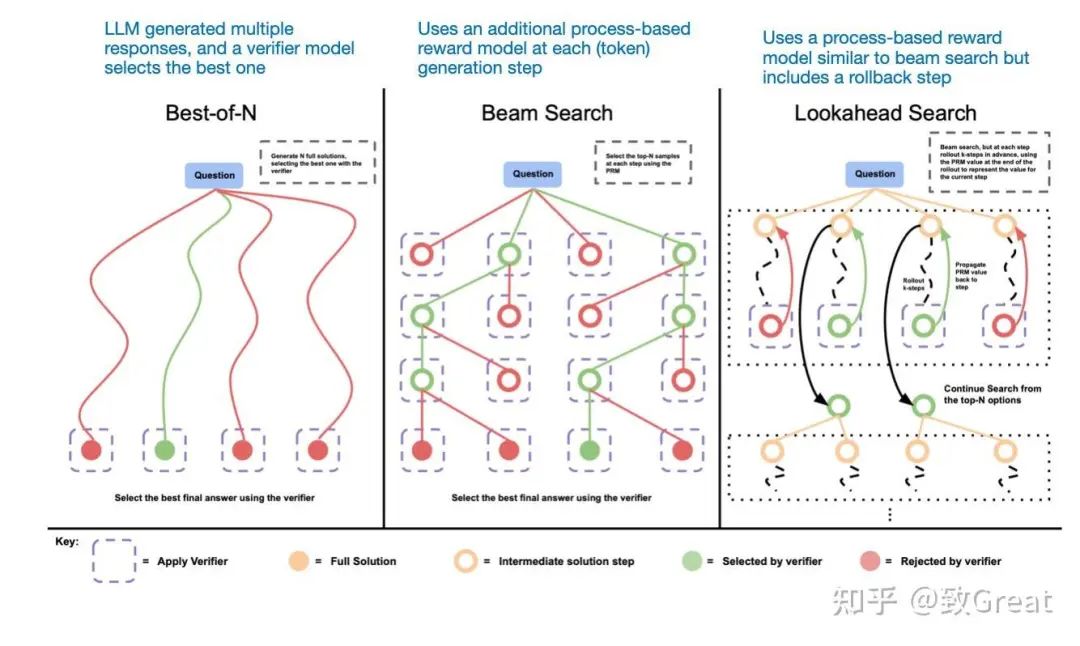
另一种方法涉及投票和搜索策略,例如多数投票或束搜索,这些方法通过选择最佳输出来改进响应。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











