







今天的 AI 创业,正在重复《苦涩的教训》
Founder Park Founder Park 2025年03月26日 20:15 北京
「RL 之父」Rich Sutton 在 2019 年发表的经典短文 The Bitter Lesson《苦涩的教训》广为人知,并且时不时被人提起。
「70 年的 AI 研究历史告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。」
如今,似乎可以重新再聊下这个话题。
比如前两天我们发的 Agent 文章里的观点:未来 AI 智能体的发展方向还得是模型本身,而不是工作流(Work Flow)。
以及最近 Gemini 和 4o 更新的图片功能,可能直接取代了很多图片工作流——用自然语言对话完成现在复杂的 SD 图像生成工作流。
模型的通用能力,正在取代现在那些复杂的 Workflow。
今天编译的这篇文章,是作者 Lukas Petersson 听完 YC 100 多个项目路演后写下了一个有趣的观察:《苦涩的教训》中所写的 AI 研究历史似乎正在 AI 创业界重演。
作者介绍:Lukas Petersson,Andon Labs 的 CEO 兼联合创始人,专注 AI 安全评估和大语言模型研究。此前,他曾在 Google 实习,曾在 Disney Research 开发病毒式机器人,还曾参与探空火箭发射项目,担任项目主要负责人。
01
历史重演:
AI 创业在重复这个教训
太长不看版:
-
历史上,通用方法始终在 AI 领域占主导。
-
如今,AI 应用领域的创始人们正在重复 AI 研究人员过去犯过的错误。
-
更强大的 AI 模型将催生更多通用 AI 应用,同时也会削弱 AI 模型「套壳」软件的附加价值。
AI 技术的飞速发展带来了一波又一波新产品。在 YC 校友 Demo Day 上,我见证了 100 多个创业项目的路演。这些项目都有一个共同点:它们瞄准的都是简单问题,加了各种限制的 AI 就能解决。
但 AI 真正的价值在于它能灵活处理各类问题。给 AI 更多自由度通常能带来更好的效果,但现阶段的 AI 模型还不够稳定可靠,所以还无法大规模开发这样的产品。
这种情况在 AI 发展史上反复出现过,每次技术突破的路径都惊人地相似。如果创业者们不了解这段历史教训,恐怕要为这些经验「交些学费」。
2019 年,AI 研究泰斗 Richard Sutton 在他那篇著名的《苦涩的教训》开篇提到:
「70 年的 AI 研究历史告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。」
那些精心设计的「专家系统」,最终都被纯靠算力支撑的系统打得落花流水。我们在语音识别、计算机象棋和计算机视觉中都看到了这种模式。这篇文章标题里的「苦涩」二字,正是来自这个在 AI 圈一演再演的剧情——从语音识别到计算机象棋,再到计算机视觉,无一例外。
如果 Sutton 今天重写《苦涩的教训》,他一定会把最近大火的生成式 AI 也加入这份「打脸清单」,提醒我们:这条铁律还没失效。
同在 AI 领域,我们似乎还没有真正吸取教训,因为我们仍在重复同样的错误...... 我们必须接受这个苦涩的教训:在 AI 系统中,强行植入我们认为的思维方式,从长远来看是行不通的。
这个「苦涩的教训」源于以下观察:
1. AI 研究者总想把人类的知识经验塞进 AI
2. 这招短期确实管用,还能让研究者有成就感
3. 但迟早会遇到瓶颈,甚至阻碍 AI 的进步
4. 真正的突破往往出人意料——就是简单地加大算力
站在 AI 研究者的角度,我们需要在总结教训的过程中明确了什么是「更好」的。对于 AI 任务,这很好量化——下象棋就看赢棋概率,语音识别就看准确率。对于本文讨论的 AI 应用产品,「更好」不仅要看技术表现,还要考虑产品性能和市场认可度。
从产品性能维度来看,即产品能在多大程度上取代人类的工作,性能越强,就能处理越复杂的任务,创造的价值自然也就越大。
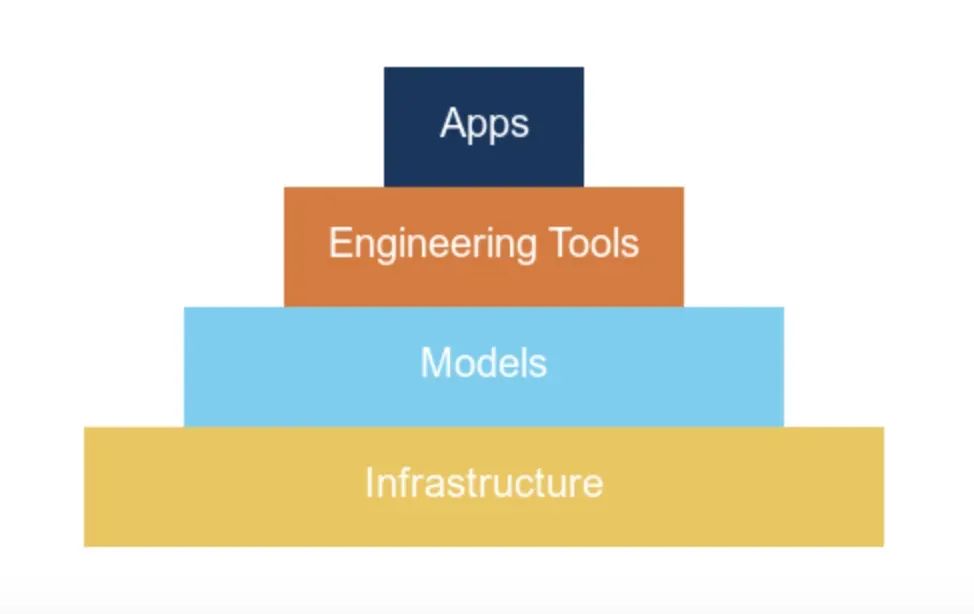
图 1. 展示了不同类型的 AI 产品,本文主要讨论应用层
AI 产品通常是给 AI 模型加一层软件包装。因此,要提升产品性能,有两条路径:
1. 工程升级:在软件层面利用领域知识设置约束规则
2. 模型升级:等待 AI 实验室发布更强大的模型
这两条路看似都可行,但在此有个重要洞察:模型能力越强,工程优化的边际效益就越低。
现阶段,软件端的设计确实能提升产品表现,但这只是因为当前模型还不够完善。随着模型变得更可靠,只需要将模型接入软件就能解决大多数问题了——不需要复杂的的工程。
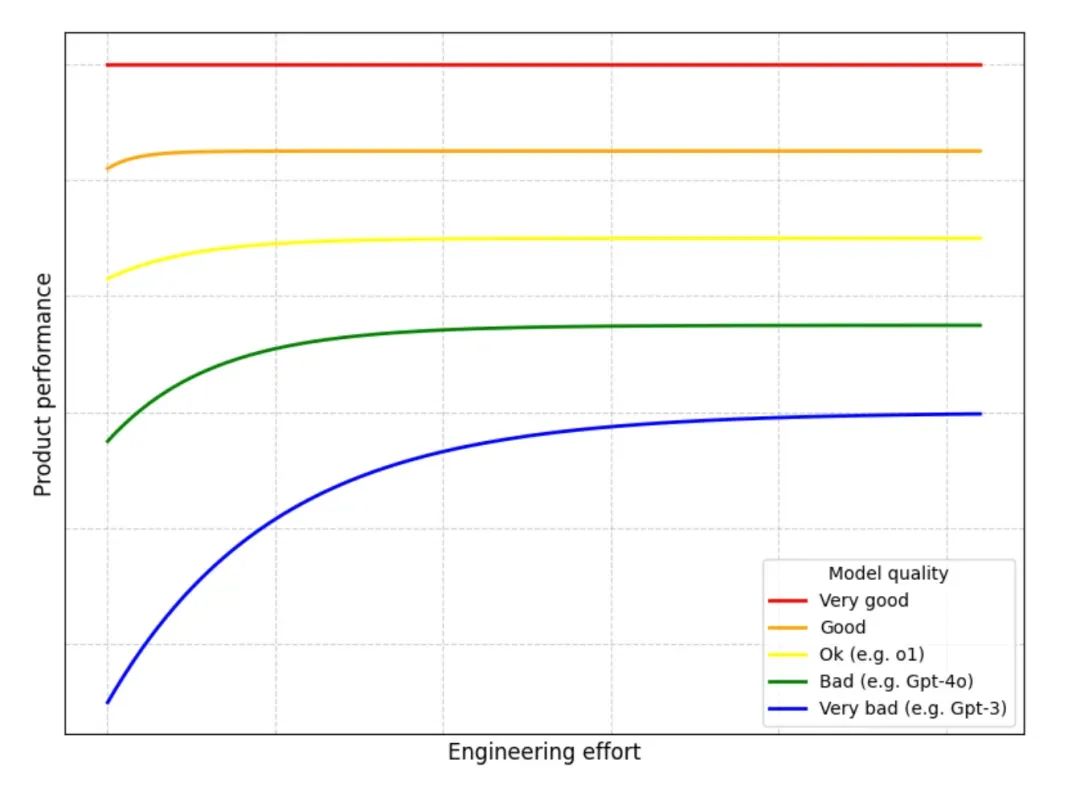
图 2. 投入工程的价值会随着投入增加和更强大模型的出现而递减
上图展示了一个趋势:随着 AI 模型的进步,优化工程带来的价值将逐渐减少。虽然当前的模型还有明显不足,企业仍能通过工程投入获得可观回报。
这一点在 YC 校友 Demo Day 上表现得很明显。创业公司主要分为两类:第一类是已经实现规模化的产品,专注解决简单问题,但数量还不多;第二类则瞄准了相对复杂的问题。后者目前发展势头不错,因为他们的概念验证证明:只要在工程上下足功夫,就能达到预期目标。
但这些公司面临一个关键问题:下一个模型发布会不会让所有工程上的都成为无用功,摧毁他们的竞争优势?OpenAI 的 o1 模型发布就很好地说明了这个风险。
我和很多 AI 应用层的创业者聊过,他们都很担心,因为他们投入了大量精力来完善提示词。有了 o1 后,提示词工程的重要性就大大降低了。
从本质上讲,这种工程的目的是为了让 AI 少犯错误。通过观察众多产品,可以概括为两类约束:
-
专业性:衡量产品的聚焦程度。垂直型产品专注于解决特定领域的问题,配备了专门的软件包装;而水平型产品则更通用,能处理多种不同类型的任务。
-
自主性:衡量 AI 的独立决策能力。在此借鉴一下 Anthropic 的分类:
-
工作流:AI 按预设路径运行,使用固定的工具和流程
-
智能体:AI 可以自主选择工具和方法,灵活决策如何完成任务
-
这就规定了一个 AI 产品的分类框架:
| 垂类 |
通用 |
|
| 工作流 |
Harvey |
ChatGPT |
| 智能体 |
Devin |
Claude Computer-Use |
表 1. 对知名 AI 产品的分类。需要注意的是,ChatGPT 可能每次对话都会遵循预先设定的代码路径,因此更像工作流而非智能体
让我们以商业分析师制作路演 PPT 为例,看看每类产品如何实现这个任务:
-
垂类工作流:它按固定步骤执行任务,比如,先用 RAG 查询公司数据库,小型 LLM 做总结,大型 LLM 提取关键数据并计算,检查数据合理性,最后生成 PPT。每次都严格遵循这个流程。
-
垂类智能体:LLM 能自主决策,循环工作,用上一步的结果指导下一步行动,虽然可用工具相同,但由 AI 自己决定何时使用。直到达到质量标准才停止。
-
通用工作流:像 ChatGPT 这样的通用工具只能完成部分任务,既不够专业也不够自主,无法完整处理整个工作流。
-
通用智能体:例如 Claude computer-use,能像人一样操作常规办公软件。分析师只需用自然语言下达指令,它就能根据实际情况灵活调整工作方法。
Demo Day 上几乎所有产品都属于垂直工作流。这很好理解——当前的 AI 模型还不够成熟,只能用这种方式才能达到可用水平。结果就是,即使是过于复杂的问题,创业者
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











