






南大院士谭铁牛 | 首个多模态统一大模型综合评测基准MME-Unify问世。
原创 AcademicDaily AcademicDaily 2025年04月08日 12:00 北京
当GPT-4o可以实时解读视频画面,当Gemini 2.0 Flash能瞬间生成高清图像,我们是否真正了解这些多模态大模型的极限?
现有评测体系在理解、生成、混合推理等能力的交叉验证上存在明显断层。
直到今天,中国科学院、北大、南大等机构联合推出MME-Unify,首次建立统一评测标准!
🔥 核心发现速览:
✅ GPT-4o理解任务封王(87.6分),但生成质量竟不敌Gemini 2.0 Flash。
✅ 国产模型MIO-Instruct视频生成惊艳,逼真度超专业视频模型。
✅ 所有模型在"几何题画辅助线"任务全军覆没,混合推理成最大短板。
✅ 开源模型DeepSeek-Janus-Pro生成质量仅5.88分,暴露技术代差。

【论文链接】https://arxiv.org/pdf/2504.03641
源码见文末
1
摘要
统一多模态大语言模型(UMLLMs)因其能够无缝集成生成和理解任务而备受关注。
然而,现有研究缺乏统一的评估标准,往往依赖孤立的基准测试来评估这些能力。
此外,当前的工作通过案例研究突出了“混合模态生成能力”的潜力,例如在图像中生成辅助线以解决几何问题,或在生成相应图像之前对问题进行推理。
尽管如此,目前尚无标准化的基准测试来评估模型在这些统一任务上的表现。
为了填补这一空白,提出MME-Unify,也称为MME-U,这是首个旨在评估多模态理解、生成和混合模态生成能力的基准测试。
对于理解和生成任务,从12个数据集中精心挑选了各种任务,统一了它们的格式和指标,以开发标准化的评估框架。
对于统一任务,设计了五个子任务,以严格评估模型的理解和生成能力如何相互增强。
对包括Janus-Pro、EMU3和Gemini2-Flash在内的12个U-MLLM的评估表明,这些模型仍有显著的改进空间,特别是在指令遵循和图像生成质量等方面。
2
背景
U-MLLMs在处理混合模态输入和输出方面表现出色,能应对更广泛的复杂任务。
像GPT-4o和Gemini2.0Flash等闭源U-MLLMs展现出强大的生成能力,在指令理解和图像创作方面令人印象深刻。
但这种多功能性也给全面评估其能力带来挑战,主要存在两个关键问题:一是缺乏统一的评估标准,现有研究常依赖孤立基准测试。
二是虽有研究通过案例展示了“混合模态生成能力”的潜力,但尚无标准化基准测试来评估模型在统一任务上的表现。
3
贡献
-
提出MME-Unify(MME-U),这是首个用于评估多模态理解、生成以及混合模态生成能力的基准测试。
-
从12个数据集中整理出多样化任务,统一格式和指标,构建了标准化评估框架。
-
设计五个子任务,严格评估模型理解和生成能力的相互增强作用,通过对12个U-MLLMs的评估,发现模型在指令遵循和图像生成质量等方面有改进空间。
4
技术方案
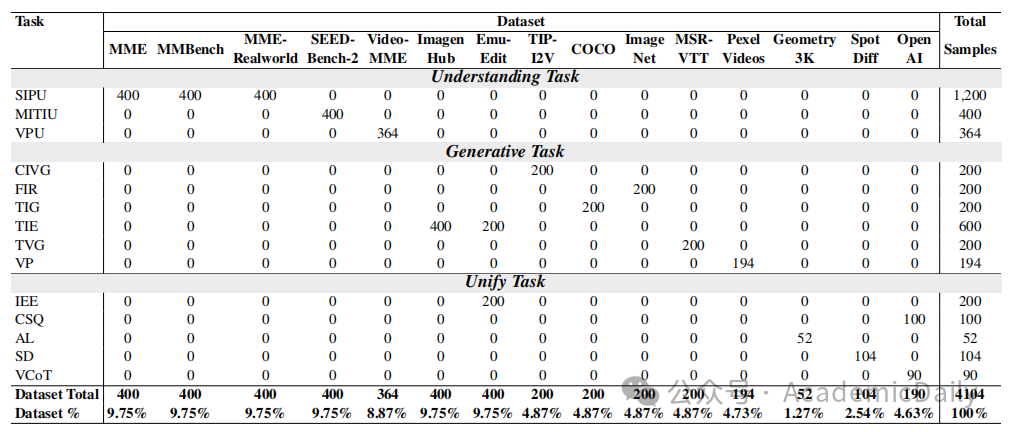
数据任务整合:从 12 个数据集中精心挑选任务,涵盖多模态理解、生成及统一任务,具体任务和数据集采样统计见上表。

评估指标设计
理解得分:理解任务包含三个子任务T={SIPU, MITIU, VPU},通过计算每个子任务的准确率,再取算术平均值得到理解得分,见图 6 理解任务的数据样本示例。
生成得分:生成任务包含六个子任务T={CIVG, TVG, VP, FIR, TIE, TIG},对各子任务采用不同指标计算得分。
如 CIVG 和 TVG 子任务得分是 FVD、FID 和 CLIPSIM 归一化得分的平均值,整体生成得分是六个子任务得分的算术平均值,见图 7 生成任务的数据样本示例。

统一得分:统一任务包含五个子任务T={IEE, CSQ, AL, SD, VCoT},对于 IEE、CSQ、AL、SD 子任务,通过计算文本和图像回答的准确率来得到整体准确率;
对于 VCoT 子任务,根据模型在迷宫导航任务中动作、坐标和图像预测的准确率计算整体指标,统一得分是所有子任务准确率的算术平均值。
MME-U 得分:MME-U 得分是理解得分、生成得分和统一得分的算术平均值。
5
实验结果

生成能力方面:多数U-MLLMs在生成能力上存在不足。
在细粒度图像重建任务中,GILL、SEED-LLaMA和MIO-Instruct能较好捕捉结构细节,但MiniGPT-5和Anole表现不佳(见图18)。

在文本引导图像编辑任务中,SEED-LLaMA和MIO-Instruct生成图像与源图像较相似,但执行编辑指令有欠缺,Gemini2.0-flash-exp表现较好(见图19)。

在条件图像到视频生成和文本到视频生成任务中,U-MLLMs在生成连贯视频序列上存在困难(见图20、图21)。

统一任务方面:多数U-MLLMs难以生成符合指令或参考图像的图像,且指令理解存在缺陷。
如在图像编辑与解释任务中,MiniGPT-5生成图像与源图像无关。
在常识问答和SpotDiff任务中,MiniGPT-5和SEED-LLaMA生成图像与选项不相关。

在辅助线任务中,Anole无法正确绘制辅助线,GILL和MiniGPT-5生成内容与原图像脱节(见图22)。
【源码链接】
https://github.com/MME-Benchmarks/MME-Unify

END
朋友们!
搞学术、做研究,信息跟不上可太愁人啦!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











