






假装Reasoning也能提准确率?LLM的极简推理法,Token减半,性能翻倍
原创 编辑部 深度学习自然语言处理 2025年04月15日 13:23 江苏
比如当你在做数学题时,老师突然说:"别写草稿了,直接写答案!"这听起来像天方夜谭?但LLM领域的最新研究证明:大语言模型跳过显式思考步骤,反而能更快更准地解决问题!

论文:Reasoning Models Can Be Effective Without Thinking
链接:https://arxiv.org/pdf/2504.09858
论文通过"伪造思考框"的巧妙设计(如下图),让模型直接输出解题步骤。这种名为NoThinking的方法,在数学证明、编程等7大挑战性任务中,以2-5倍的token效率完胜传统方法。
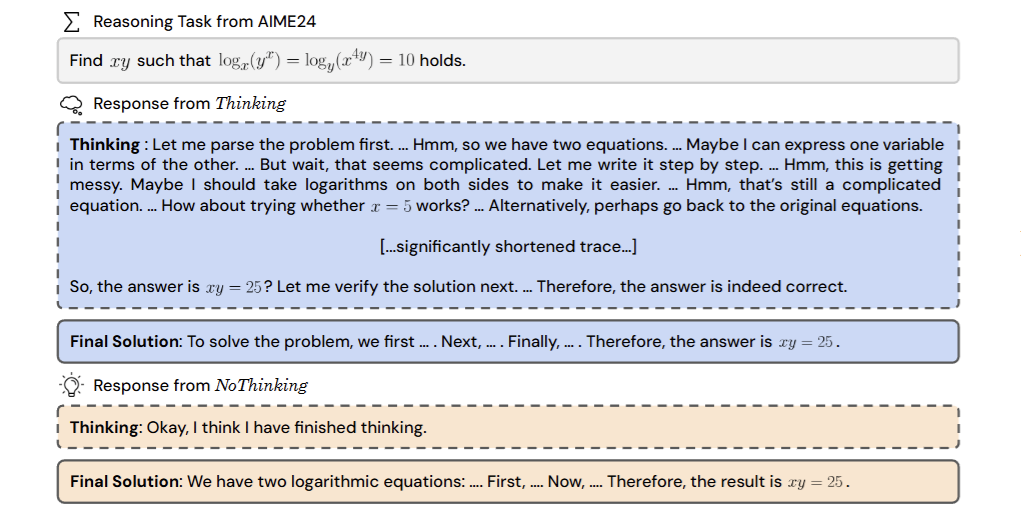
传统方法VS新方法
传统AI推理就像严谨的学霸:
问题 → 详细推导(思考) → 最终答案
而NoThinking模式更像是直觉型天才:
问题 → [假装思考完毕] → 直接输出答案
关键突破在于:高质量答案可能早已编码在模型参数中,冗长的中间推导反而可能引入错误。就像有些数学天才不需要打草稿就能心算答案。
实验验证
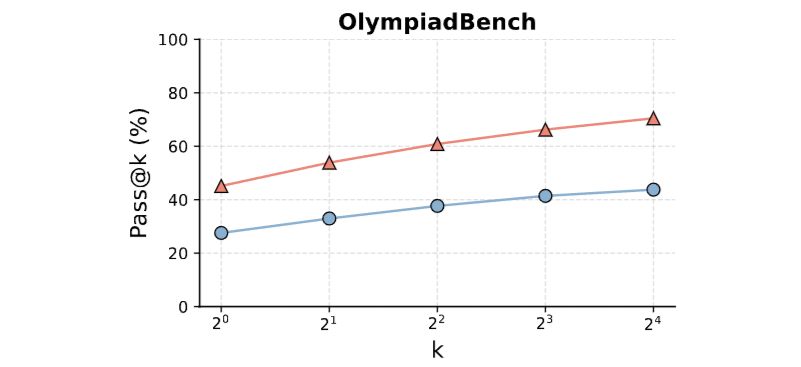
研究团队在三大类任务中展开对决:
-
数学竞赛题(如AIME/AMC)
-
定理证明(MiniF2F/ProofNet)
-
编程挑战(LiveCodeBench)
在700 token的低配场景下,NoThinking以51.3% vs 28.9%的准确率碾压传统方法。更惊人的是,随着尝试次数增加,优势持续扩大——好比考试时允许试错次数越多,学霸优势越明显。
并行扩展
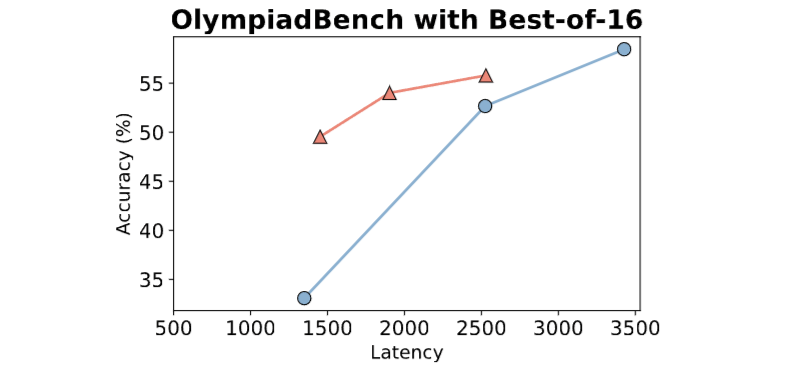
NoThinking的杀手锏在于批量生成+智能筛选:
-
同时生成N个答案(如开32个聊天窗口)
-
用验证器或置信度筛选最优解
这带来两大革命性提升:
-
速度提升9倍:并行计算大幅缩短等待时间
-
准确率跃升:类似"三个臭皮匠顶个诸葛亮"
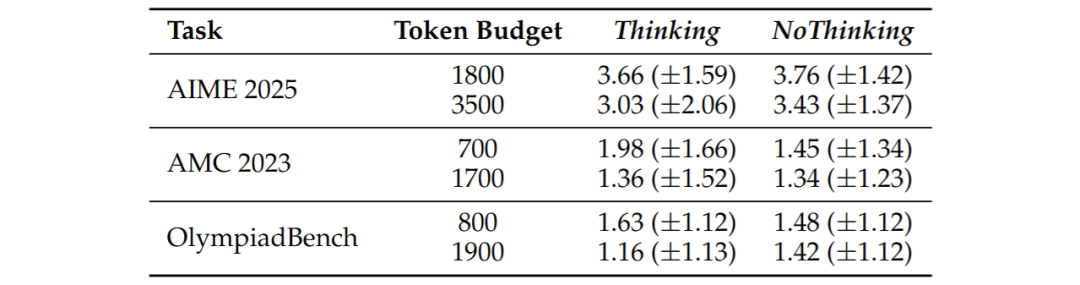
如表所示,在定理证明任务中,该方法用1/4的计算量就达到相同效果。这对需要实时响应的应用场景(如智能客服)意义重大。
启示
这项研究正在引发LLM界的"极简革命":
-
训练成本降低:无需强化学习训练思考链
-
推理效率跃升:低配设备也能跑高质量模型
-
应用场景扩展:实时推理系统迎来新可能
就像手机从功能机到智能机的进化,AI推理正在卸下冗余的"思考包袱",开启轻量化新时代。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











