






Torch.Tensor 三生三世
原创 TaylorGuo 月亮动物园 2025年05月18日 20:58 上海
大语言模型 | 编译器 | PyTorch
最近一直在研究 Triton 和 PyTorch 第三方新硬件接入的源代码, 为理顺代码逻辑, 逐模块复现, 吸收应用, 做一些实验, 有一些学习成本和工作量。当下热门的AI 编程工具, 虽没有预想的强大, 但提供了很多思路, 是有力的助手。恰逢最近与他人讨论 PyTorch Tensor 实现到新后端, 对其他厂商开源代码进行了分析, 以新后端上实现Tensor 的调用开始这个指南。
一、从 Torch Tensor 说起
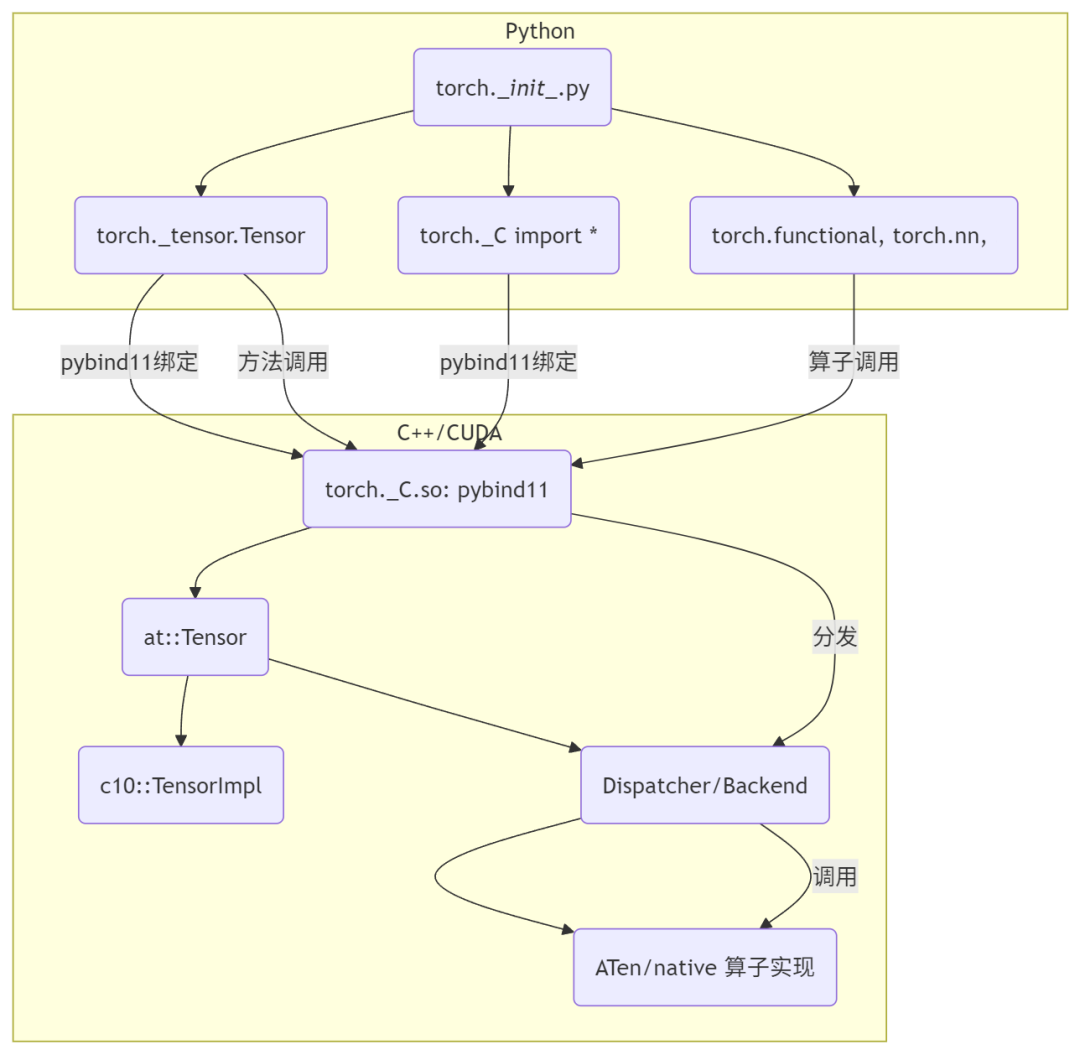
torch.__init__.py 是 PyTorch Python 主初始化文件。它发挥了以下作用:
-
导入并初始化 C++ 库 (torch._C), 实现 Python 与底层 C++/CUDA 后端的桥接。通过 from torch._C import *, 加载核心 C++ 实现 (_C 是编译得到的 .so/.pyd 动态库), 同时把其导出的类和函数 (如 Tensor、Storage、各种算子实现等) 注册到 Python 层的模块中。
-
定义并导出核心 Python API,如 Tensor、各种 Storage 类型、常用函数 (如 rand、matmul 等)。通过 from torch._tensor import Tensor,将 Python 侧的 Tensor 类(其实是 C++ Tensor 的子类/包装)导入,设置好各种 Storage 类型。通过 from torch.functional import *,把常用的函数导入到 torch 命名空间。
-
设备、类型、随机数等全局状态设置、读取。注册设备相关模块, 如 torch.cuda、torch.xpu,通过 get_device_module 等方法动态注册。
-
加载子模块 (如 torch.nn, torch.autograd, torch.cuda 等), 把它们注册到 torch 命名空间。
-
初始化扩展工具 (如共享内存、日志、后端插件等) 。
Tensor 关键调用链
-
Python 用户代码(如 torch.tensor([2, 3]))

-
Python 层 包装(torch.Tensor)
-
C++ 层 pybind11 绑定(torch._C.TensorBase)
-
C++ at::Tensor,底层数据和元信息由 c10::TensorImpl 管理
-
算子由 dispatcher / dispatch key 路由到后端实现(CPU / CUDA / XPU / MPS 等)
算子如何调用后端: 算子(如 torch.add)的 Python 实现会直接调用 C++ 层注册的同名函数。C++ 层内部有 dispatcher 机制(见 c10 / core / DispatchKey.h),根据张量的 device、dtype 等信息,动态分发到对应后端(如 CPU / CUDA)的具体实现。真正的后端实现代码,主要在 aten / src / ATen / native / 目录下的 C++ 文件中。
二、Tensor C++ 实现
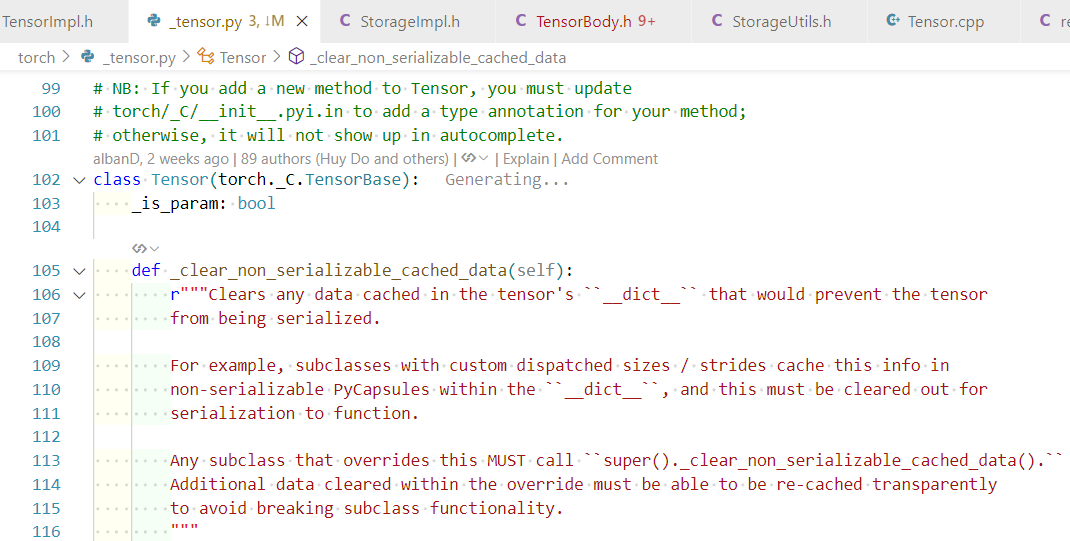
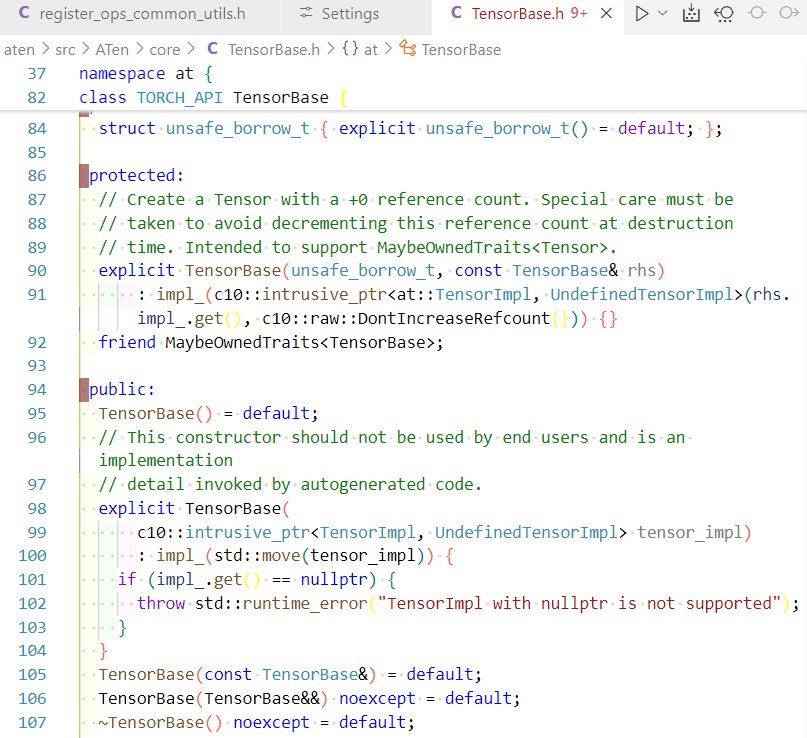
Python Torch.Tensor 实际上是 torch._C.TensorBase 的一个 Python 包装类(见 torch/_tensor.py),是用户可见的Tensor类。
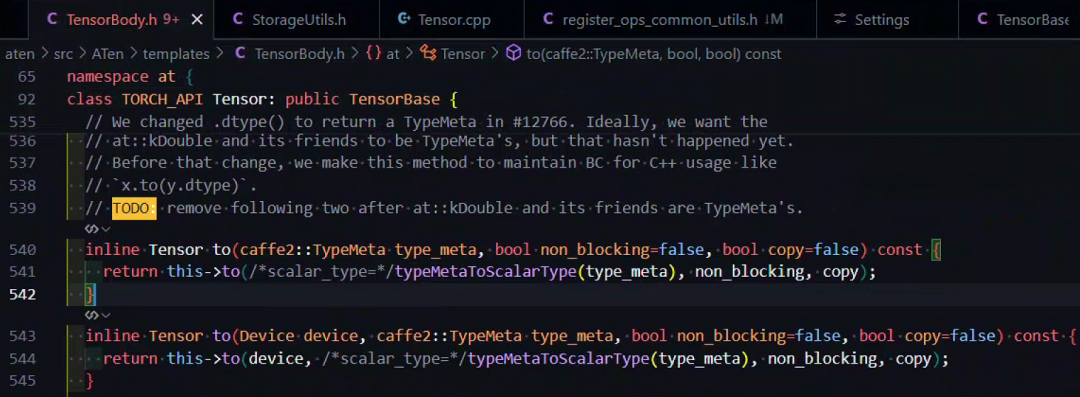
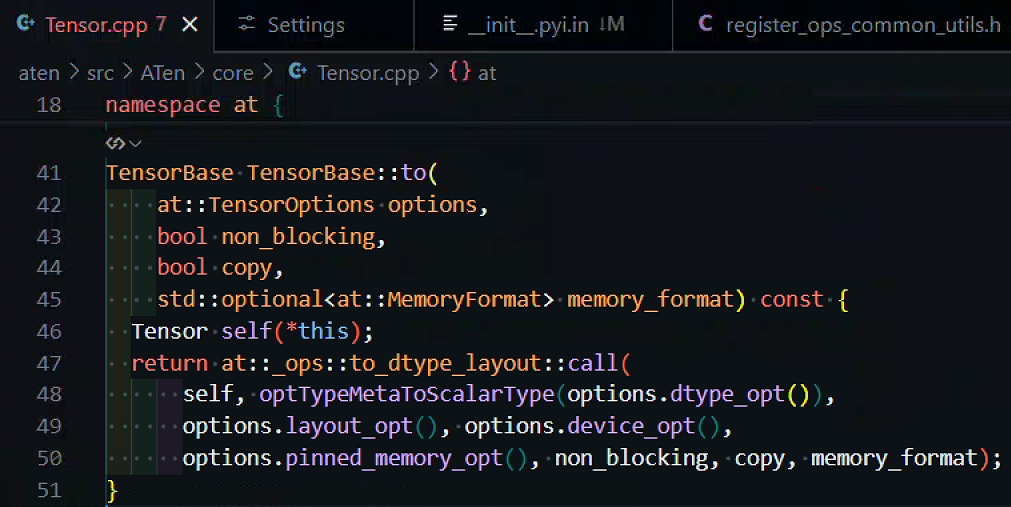
Tensor 很多方法, 最终会 通过 torch._C 转发到底层的 C++ 实现。torch._C 模块在 Python 层是不可见的源码文件, 它通过 C++/CUDA 代码编译出动态库(比如 torch / _C.so 或 torch / _C.pyd)。其核心类型是 TensorBase,底层实际数据结构是 at::Tensor,而 at::Tensor 又封装了 c10::TensorImpl 。
相关 C++ 头文件有:
-
aten/src/ATen / ATen.h: 使用了 ATen / Tensor.h, 而Tensor.h包含了 ATen / core / Tensor.h。
-
ATen/core/Tensor.h: 定义了 at::Tensor 类(又叫 TensorBase)。
-
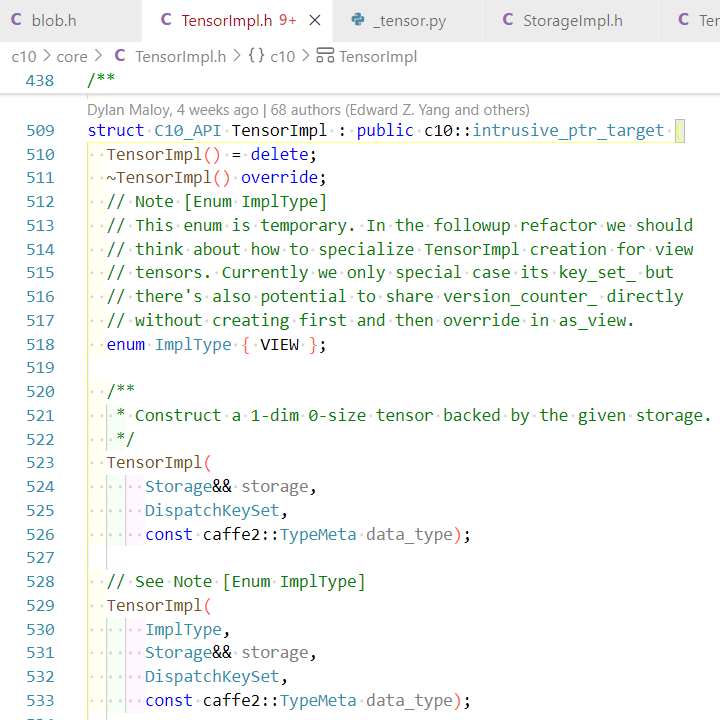
c10/core/TensorImpl.h: TensorImpl 是 PyTorch 张量的底层实现,负责存储数据指针、shape、dtype、device、strides 等元信息。Tensor 的构造、运算、属性访问等,都绑定到了 C++ 的 at::Tensor / TensorImpl。
-
大部分算子的实际实现逻辑在 aten / src / ATen / native / 下的 C++ 文件(其注册信息在 aten / src / ATen / native / native_functions.yaml)。
-
dispatcher 会根据 Tensor 的 device/dtype 信息,选择调用 to_cpu, to_cuda 等实际 kernel。以 CUDA 为例,最终会调用 aten/src/ATen/native/cuda/ 下的相关实现,并通过 CUDA runtime API 完成数据搬运和类型转换。
如果目标后端是 CUDA,ATen 的 CUDA kernel(如 aten / src / ATen / native / cuda / 下的实现)会被调用。这些 kernel 会进一步调用 CUDA Runtime(比如 cudaMemcpyAsync 等)完成实际的数据搬运或类型转换。
-
如果涉及 Autograd,相关的 Autograd Function(见 torch / autograd / function.py)会包裹底层的 ATen 调用,确保梯度跟踪。
-
JIT、FX 等机制也会在 Python / C++ 层之间插入,但不会改变 to->ATen->后端的主流程。
总结流程
-
用户调用 tensor.to('cuda')(Python 层)。
-
Python 层方法实际调用 C++ 的 Tensor.to(通过 pybind11)。
-
C++ 的 Tensor.to 跳转到 ATen 层的 to API。
-
Dispatcher 根据参数分发到对应后端(如 CUDA)的 kernel。
-
CUDA kernel 通过 CUDA Runtime 实现实际的数据搬运和转换。
三、新后端实现 Tensor 对接
第三方硬件的后端, 比如 Intel HPU 也通过无侵入PyTorch 源代码、扩展插件的方式, 实现了HPU 后端对PyTorch的支持。从 Python 用户层到最底层的实现机制,从 Python API 到 C++/底层硬件的整个调用链进行梳理。
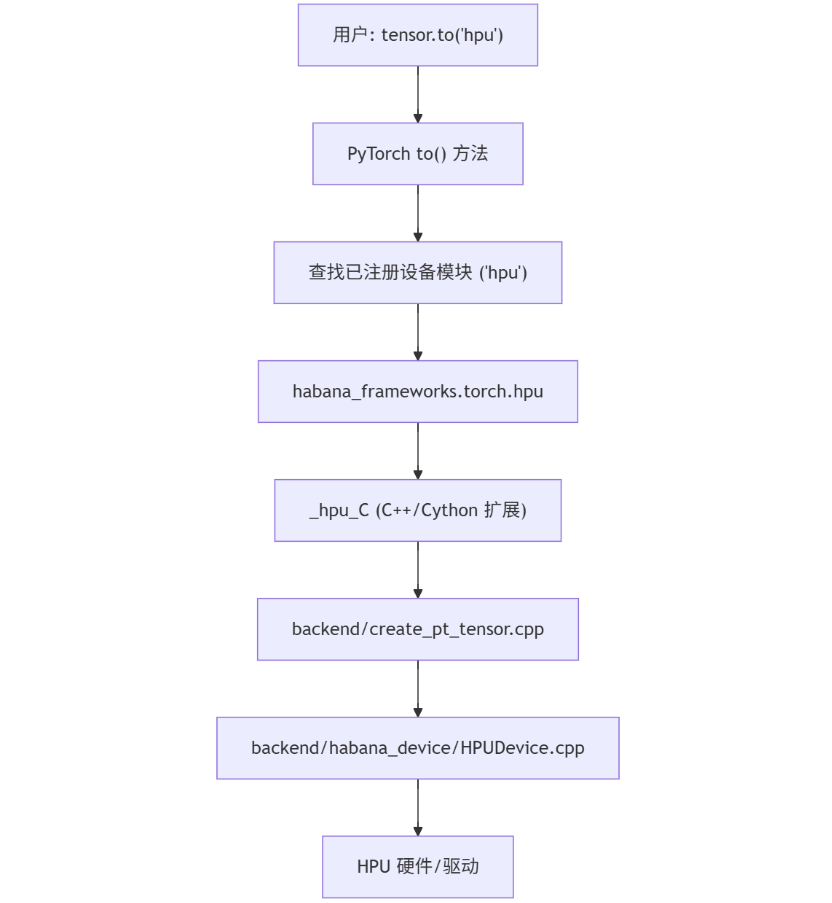
以下是实际代码的分层解读:
Python 用户代码调用
import osimport sysimport torchimport time# 导入 HPU 扩展包import habana_frameworks.torch.core as htcorefrom torch.utils.data import DataLoaderfrom torchvision import transforms, datasetsimport torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 256)self.fc2 = nn.Linear(256, 64)self.fc3 = nn.Linear(64, 10)def forward(self, x):out = x.view(-1,28*28)out = F.relu(self.fc1(out))out = F.relu(self.fc2(out))out = self.fc3(out)out = F.log_softmax(out, dim=1)return outmodel = Net()checkpoint = torch.load('mnist-epoch_20.pth')model.load_state_dict(checkpoint)model = model.eval()# to("hpu")model = model.to("hpu")transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])data_path = './data'test_kwargs = {'batch_size': 32}dataset1 = datasets.MNIST(data_path, train=False, download=True, transform=transform)test_loader = torch.utils.data.DataLoader(dataset1,**test_kwargs)correct = 0for batch_idx, (data, label) in enumerate(test_loader):# to("hpu")data = data.to("hpu")output = model(data)htcore.mark_step()correct += output.max(1)[1].eq(label).sum()print('Accuracy: {:.2f}%'.format(100. * correct / (len(test_loader) * 32)))
-
tensor.to("hpu") 或 model.to("hpu"),都是调用 PyTorch to() 方法,将张量或模型的参数/Buffer 转移到指定设备。
-
设备字符串 "hpu" 由 硬件后端桥接层注册为 PyTorch 设备类型。
设备注册
在 python_packages / habana_frameworks / torch / core /__init__.py 中对设备进行注册:
import torchfrom habana_frameworks.torch import hpu...torch._register_device_module("hpu", hpu)
这里注册了 "hpu" 设备,使得 PyTorch 在解析 .to("hpu") 时能够路由到对应的 HPU 实现。
初始化与设备管理
在 python_packages / habana_frameworks / torch / hpu / __init__.py 代码里,实现了完整的设备初始化、管理、切换逻辑。
def _lazy_init():..._hpu_C.init()...DefaultDeviceType.set_device_type("hpu")
-
hpu_C 是 C++/Cython 扩展模块,硬件后端实现, 负责实际的设备初始化、同步、数据传输等。
-
初始化会在第一次调用 Intel HPU 相关操作时自动触发。
-
这里还定义多种 HPU 张量类型别名, 如 FloatTensor, 所有张量都可以指定 device="hpu"。
设备 API
python_packages / habana_frameworks / torch / _hpu_C.py 动态导入了不同的底层绑定实现 (fork 或 upstream), 这些最终由 C++ 实现,暴露 init(), device_count(), get_device_name(), synchronize_device() 等与设备相关的接口。
与 PyTorch ATen 交互
-
HPU 设备注册在 PyTorch C++ ATen 层, 这样在 PyTorch 内部的张量分配、数据拷贝或转移时, 会自动调用对应的 HPU 实现。
-
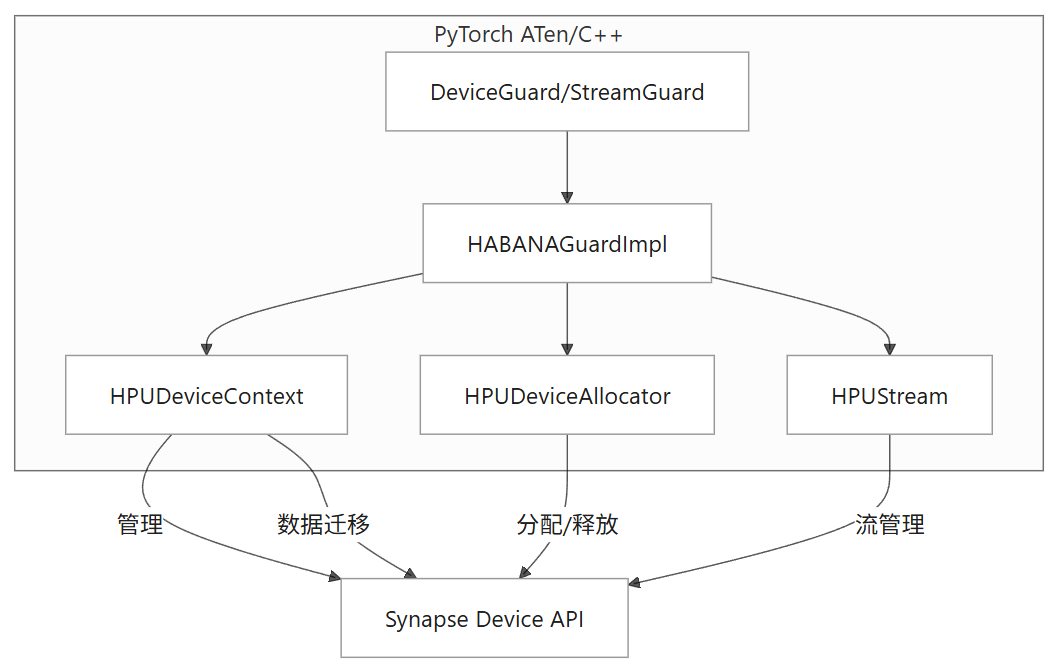
设备类型、Guard、Stream、Event 等都在后端 C++ 层实现。
在 C++ 层,见 backend / create_pt_tensor.cpp 和 backend / create_pt_tensor.h:
at::Tensor habana::createPTTensor(const at::Tensor& input, bool is_persistent);设备上下文与 Guard
在 backend / habana_device / HPUGuardImpl.h 里,定义了 HABANAGuardImpl,它实现了 PyTorch 的 DeviceGuardImplInterface,用于:
-
设备切换(setDevice/exchangeDevice)
-
获取当前设备、流
-
事件同步等
这保证了 PyTorch 的设备管理机制能正确作用于 HPU。
// backend/habana_device/HPUGuardImpl.hstruct HABANAGuardImpl final : public c10::impl::DeviceGuardImplInterface {static constexpr at::DeviceType static_devType = at::DeviceType::HPU;...at::DeviceType type() const override { return at::DeviceType::HPU; }...};
设备初始化与管理
backend / habana_device / HPUDevice.cpp 负责设备的实际初始化、线程池、资源管理等。比如:
-
HPUDeviceContextImpl::Init() 完成设备创建、线程池初始化等。
-
get_or_create_aten_device() 在 PyTorch 层面注册/获取 HPU 设备。
c10::Device HPUDeviceContext::get_or_create_aten_device() {if (!device_context.device_) {device_context.Init();...}return {at::kHPU, static_cast<at::DeviceIndex>(0)};}
张量分配
backend/create_pt_tensor.cpp 实现了 HPU 张量的创建逻辑:
-
通过 at::empty 等 ATen API 分配 HPU 张量(带 HPU 的 DispatchKey)
-
支持 persistent/non-persistent 分配策略
数据搬运与拷贝
-
当调用 .to("hpu") 时,PyTorch 会调用对应的 HPU 设备的数据拷贝实现(通过 ATen/C++ 层的注册)
-
具体的数据拷贝、同步等在 backend / habana_device / HPUDevice.cpp、HPUDeviceContextImpl 里实现,最终调用 Synapse API 与底层硬件通信。
copy_data_to_device(...) 和 copy_data_to_host(...) 分别实现主机与设备之间的数据传输。这些函数会调用 Synapse API 或 Habana 自己的设备驱动层。
Operator 路由
所有在 HPU 上的运算,都会路由到 HPU 的 kernel/operator 实现(见 backend/habana_operator.cpp),这些 operator 会根据输入/输出张量的 device 类型自动分发到 HPU 计算。
总结一下:
Intel Habana data.to("hpu") 的实现主要依赖于 Habana PyTorch Bridge 底层结构,通过 habana_frameworks.torch.hpu 模块和相关 C++ 代码来实现设备数据传输。
-
to("hpu") 的本质是 PyTorch 设备迁移机制,Habana 通过注册 "hpu" 设备类型和实现 ATen/C++ 层接口与 Guard,接管了所有与 HPU 相关的张量管理和数据迁移。
-
Python 层只是入口,实际的数据迁移、张量分配、operator 执行都在 C++/ATen 层和更底层的 Synapse API 完成。
-
设备初始化和资源管理由 HPUDeviceContextImpl 负责,张量的分配和拷贝通过 create_pt_tensor.cpp 等实现。
-
model.to("hpu") 会递归地把所有参数/Buffer 都迁移到 HPU,底层机制复用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











