







开源语音实时交互新突破:LLaMA-Omni实现大语言模型无缝语音交互
原创 旺知识 旺知识 2024年09月22日 12:20 广东
像 GPT-4o 这样的模型通过语音实现了与大型语言模型(LLMs)的实时交互,与基于文本的传统交互相比,显著提升了用户体验。然而,目前在如何构建基于开源 LLMs 的语音交互模型方面仍缺乏探索。为了解决这个问题,我们提出了 LLaMA-Omni,这是一个新颖的模型架构,旨在与 LLMs 进行低延迟和高质量的语音交互。LLaMA-Omni 集成了一个预训练的语音编码器、一个语音适配器、一个 LLM 和一个流式语音解码器。它消除了语音转录的需要,并且能够直接从语音指令中同时生成文本和语音响应,延迟极低。我们基于最新的 Llama-3.1-8BInstruct 模型构建了我们的模型。为了使模型与语音交互场景保持一致,我们构建了一个名为 InstructS2S-200K 的数据集,其中包含 200K 条语音指令和相应的语音响应。实验结果表明,与以前的语音-语言模型相比,LLaMA-Omni 在内容和风格上都提供了更好的响应,响应延迟低至 226 毫秒。此外,训练 LLaMA-Omni 仅需要不到 3 天的时间,仅需 4 个 GPU,为未来基于最新 LLMs 的语音-语言模型的高效开发铺平了道路。
我们翻译解读最新论文:与大型语言模型无缝语音交互,文末有论文链接。

作者:张长旺,图源:旺知识
1 引言
以 ChatGPT(OpenAI, 2022)为代表的大型语言模型(LLMs)已成为功能强大的通用任务求解器,能够通过会话交互在日常生活中协助人们。然而,目前大多数 LLMs 仅支持基于文本的交互,这限制了它们在文本输入和输出不理想的场景中的应用。最近,GPT4o(OpenAI, 2024)的出现使得通过语音与 LLMs 交互成为可能,以极低的延迟响应用户的指令,并显著提升了用户体验。然而,开源社区在构建基于 LLMs 的此类语音交互模型方面仍缺乏探索。因此,如何实现与 LLMs 的低延迟和高质量的语音交互是一个迫切需要解决的挑战。

与 LLMs 实现语音交互的最简单方法是通过基于自动语音识别(ASR)和文本到语音(TTS)模型的级联系统,其中 ASR 模型将用户的语音指令转录成文本,TTS 模型将 LLM 的响应合成为语音。然而,由于级联系统顺序输出转录的文本、文本响应和语音响应,整个系统的延迟往往较高。相比之下,一些多模态语音-语言模型已经被提出(Zhang et al., 2023; Rubenstein et al., 2023),它们将语音离散化为标记,并扩展 LLM 的词汇表以支持语音输入和输出。理论上,这种语音-语言模型可以直接从语音指令生成语音响应,而不产生中间文本,从而实现极低的响应延迟。然而,在实践中,由于涉及的复杂映射,直接语音到语音的生成可能具有挑战性,因此通常生成中间文本以实现更高的生成质量(Zhang et al., 2023),尽管这牺牲了一些响应延迟。
在本文中,我们提出了一个新颖的模型架构 LLaMA-Omni,它实现了与 LLMs 的低延迟和高质量交互。LLaMA-Omni 由语音编码器、语音适配器、LLM 和流式语音解码器组成。用户的语音指令由语音编码器编码,然后由语音适配器处理,然后输入到 LLM 中。LLM 直接从语音指令解码文本响应,而不是先将语音转录成文本。语音解码器是一个非自回归(NAR)流式 Transformer(Ma et al., 2023),它以 LLM 的输出隐藏状态为输入,并使用连接时序分类(CTC; Graves et al., 2006a)预测与语音响应相对应的离散单元序列。在推理过程中,随着 LLM 自回归地生成文本响应,语音解码器同时生成相应的离散单元。为了更好地与语音交互场景的特点保持一致,我们通过重写现有文本指令数据和执行语音合成构建了一个名为 InstructS2S-200K 的数据集。实验结果表明,LLaMA-Omni 可以同时生成高质量的文本和语音响应,延迟低至 226 毫秒。此外,与以前的语音-语言模型如 SpeechGPT(Zhang et al., 2023)相比,LLaMA-Omni 显著减少了所需的训练数据和计算资源,使得基于最新 LLMs 的强大语音交互模型的高效开发成为可能。
2 模型:LLAMA-OMNI
在这一部分,我们介绍了 LLaMA-Omni 的模型架构。如图 2 所示,它由语音编码器、语音适配器、LLM 和语音解码器组成。我们将用户的语音指令、文本响应和语音响应分别表示为 XS、YT 和 YS。
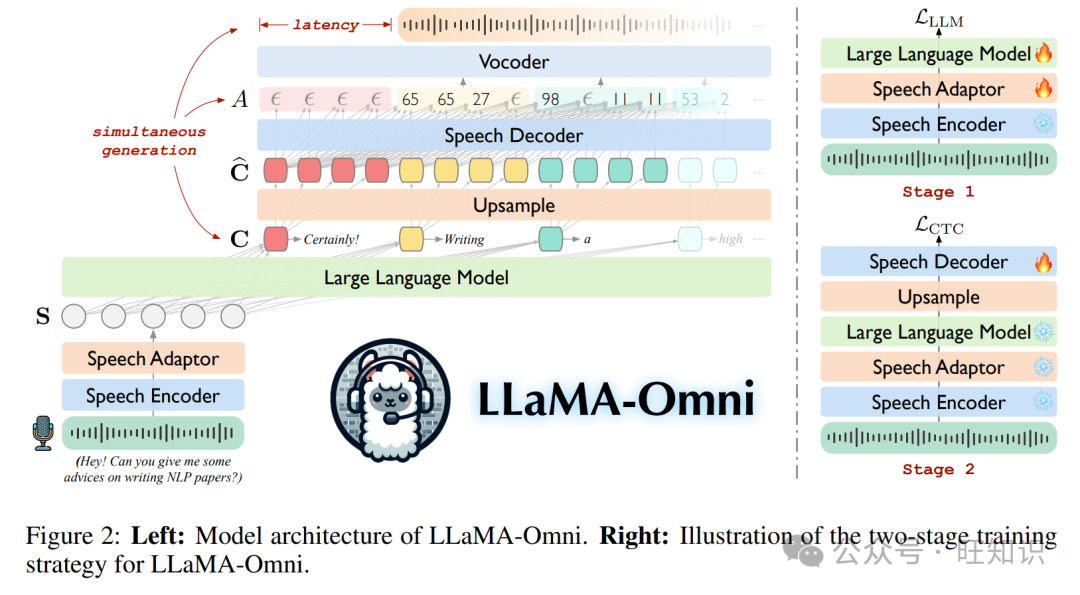
2.1 语音编码器
我们使用 Whisper-large-v32(Radford et al., 2023)的编码器作为语音编码器 E。Whisper 是一个在大量音频数据上训练的通用语音识别模型,其编码器能够从语音中提取有意义的表示。具体来说,对于用户的语音指令 XS,编码的语音表示由 H = E(XS) 给出,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











