






LIMO颠覆认知:无需10万级数据,数学推理竟可用极少样本激发!
原创 无影寺 AI帝国 2025年02月08日 09:16 广东

现有认知被挑战:复杂推理真的需要海量数据吗?
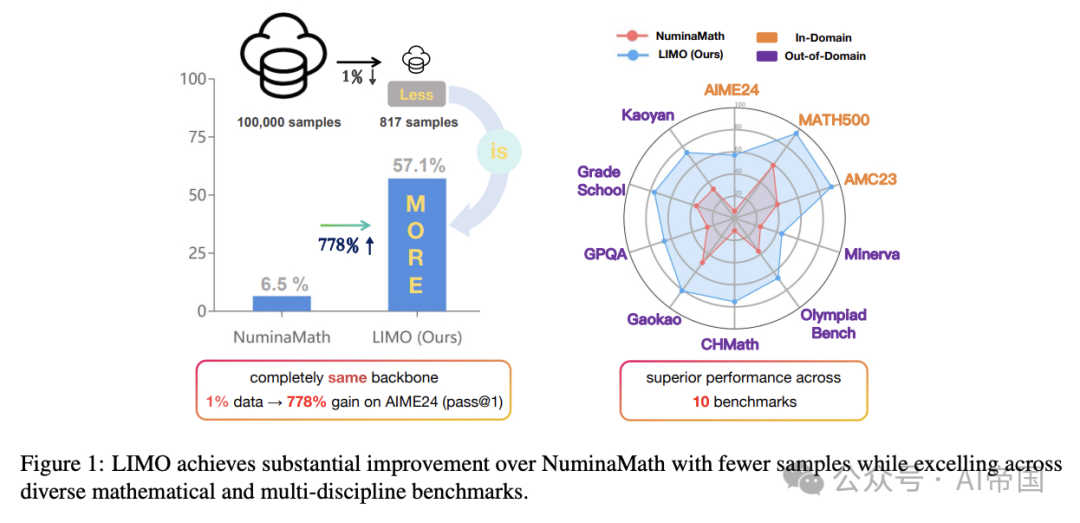
在人工智能领域,数学推理一直被认为是最难掌握的能力之一。传统观点认为,要让大模型学会复杂推理,必须使用数十万甚至上百万的训练样本,否则只能停留在“记忆”而非“推理”层面。然而,LIMO 研究团队发现,这一观点可能并不正确。他们的实验表明,仅用 817 条精心挑选的样本,就能让大模型在数学推理任务上达到前所未有的高性能,甚至超越使用 100 倍数据训练的模型。
LIMO方法揭秘:为何“少即是多”?
LIMO 团队提出了“Less-Is-More Reasoning (LIMO) 假设”,即:
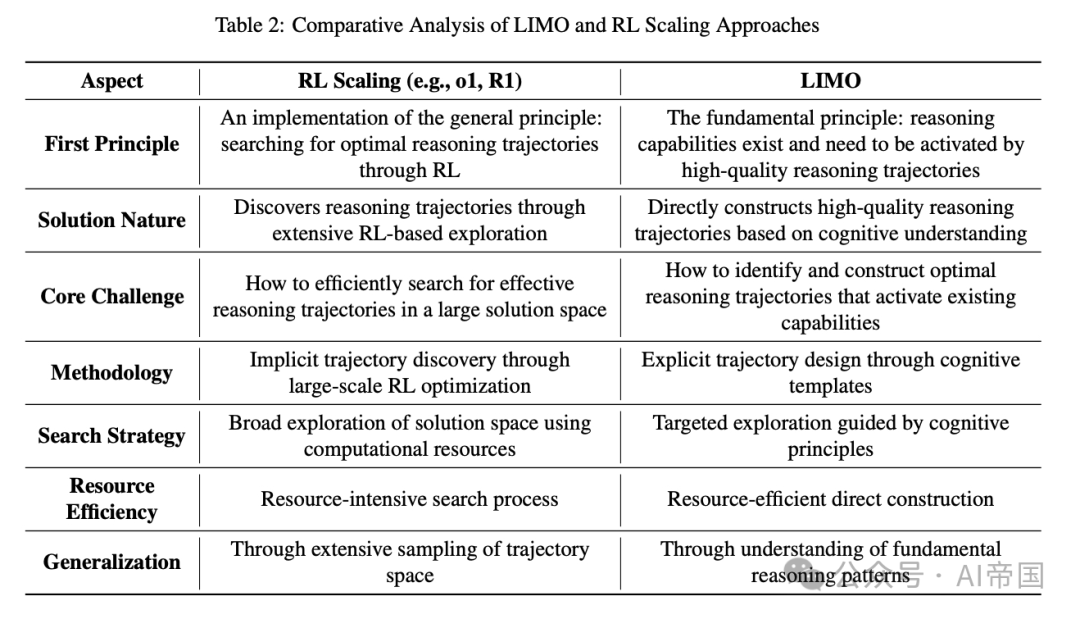
1、现代大模型在预训练阶段已编码大量数学知识,因此核心问题不再是如何让模型学习新知识,而是如何激发它已有的知识。
2、高质量的训练样本远比数据量更重要,少量但精准的示例可以作为“认知模板”,引导模型更有效地利用已有知识进行推理。
基于这一假设,LIMO 研究团队设计了一套仅包含 817 个数学推理示例的训练集,但每个示例都经过精细挑选,强调逻辑推理链的构建,使模型在有限数据下也能形成稳健的推理能力。
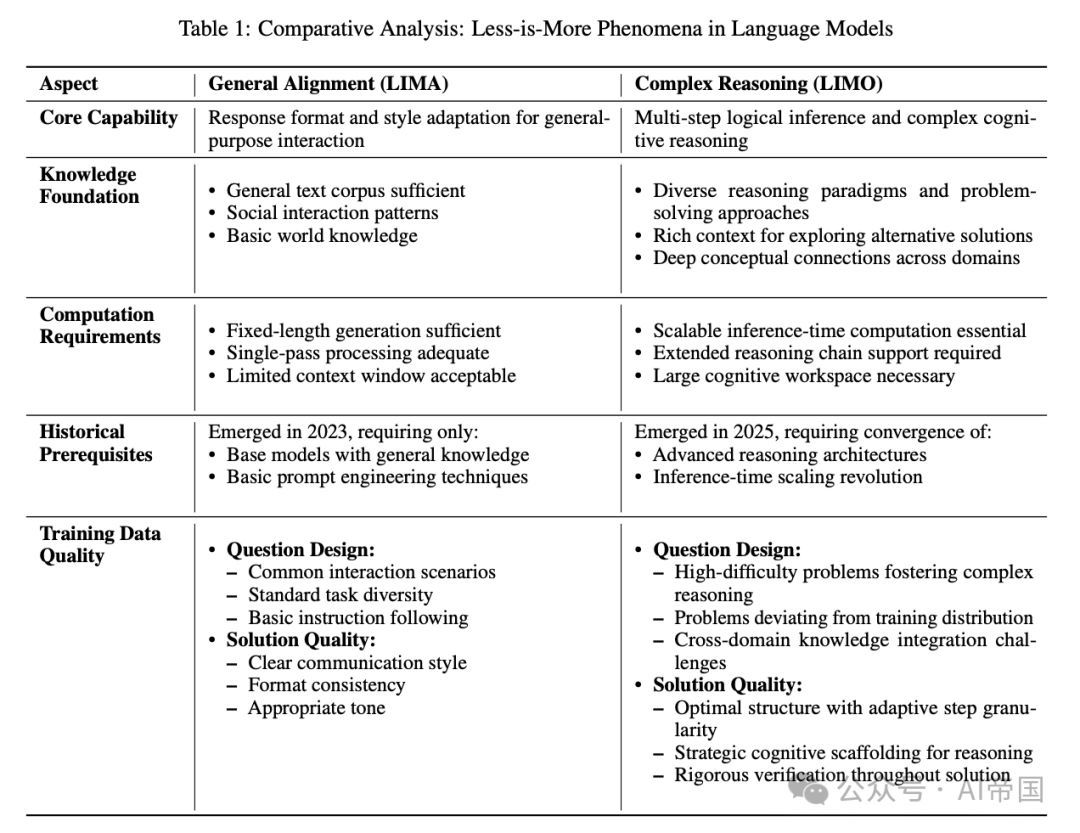
实验结果:极少数据如何击败大规模训练?
LIMO 模型在多个数学推理基准上取得了惊人的成绩:
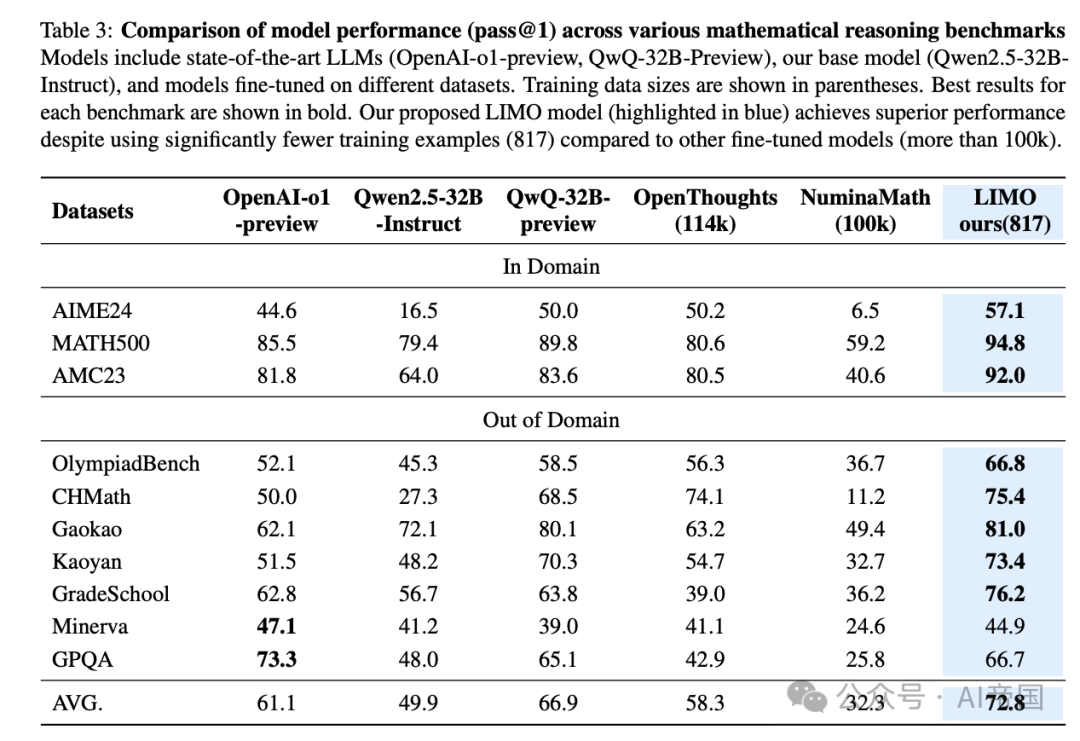
•AIME 高级数学竞赛:57.1% 准确率,相比之前最强 SFT(监督微调)模型仅 6.5% 的成绩,提升近 50 个百分点!
•MATH 数据集:94.8% 准确率,相比之前最优模型的 59.2% 大幅提升。
•10 个跨领域推理任务的平均提升 40.5%,甚至超过使用 100 倍数据训练的模型!
更令人惊讶的是,LIMO 展现出了极强的泛化能力,不仅能在训练数据上表现出色,在完全未见过的新题目上依然能够取得优秀成绩。这直接挑战了“监督微调只会导致记忆,而不是推理”的传统观点。

LIMO的启示:推理能力的未来如何发展?
LIMO 研究证明,大模型的推理能力并不受限于训练数据的规模,而是取决于训练样本的质量和模型在推理时的计算资源。这为 AI 研究者提供了新的思路:
•未来训练 AI 或许不需要无止境地扩展数据规模,而是专注于如何高效设计训练示例,激发模型已有的知识。
•AI 可能比我们想象中更容易具备复杂推理能力,只要找到合适的方式引导它们“思考”。
LIMO 研究已经开源(GitHub 传送门),有兴趣的研究者可以亲自体验这一“少即是多”的突破性成果。你认为未来 AI 的推理能力会如何发展?欢迎留言讨论!
论文标题:LIMO: Less is More for Reasoning
论文链接:https://arxiv.org/abs/2502.03387



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











