






全网最速 DeepSeek-V3-0324 写代码实测!
karminski-牙医 NLP轻松谈 2025年03月25日 09:29 北京
给大家带来全网最速 DeepSeek-V3-0324 写代码实测!
直接说结论—— 超越 DeepSeek-R1!甚至超越 Claude-3.7! 难以想象这还不是一个 Thinking 模型!
DeepSeek-V3-0324 目前以 328.3 分在 KCORES 大模型竞技场排名第三,仅次于 claude-3.7-sonnet-thinking 和 claude-3.5 (没错 claude-3.5 在我们的测试下比 claude-3.7 要好一些)。
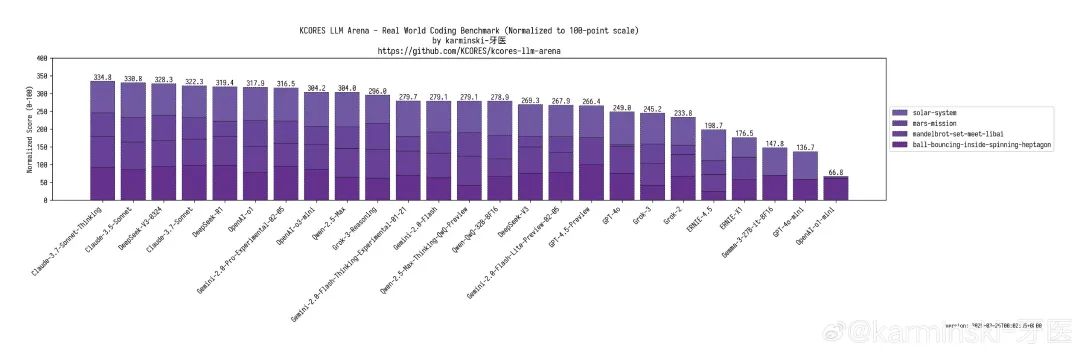
四项评测中:
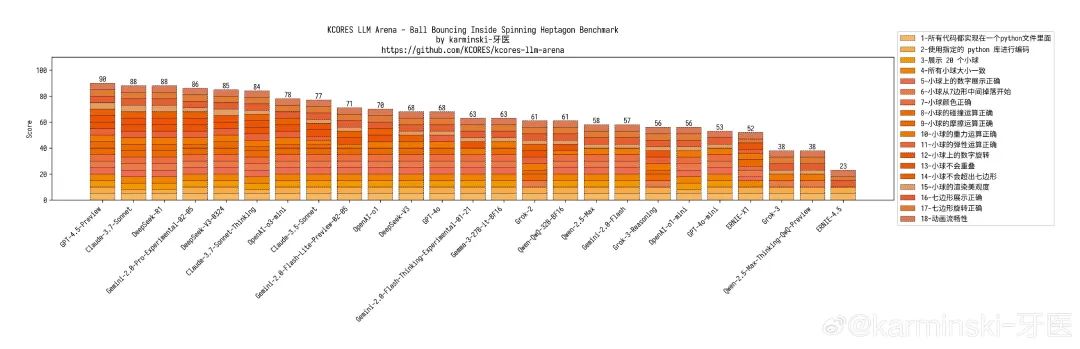
20 小球碰撞测试 ,肉眼可见的进步,之前 DeepSeek-V3 的小球挤成一团,现在物理运动模拟得非常好,仅因掉出了7边形扣了5分,项目排名第5
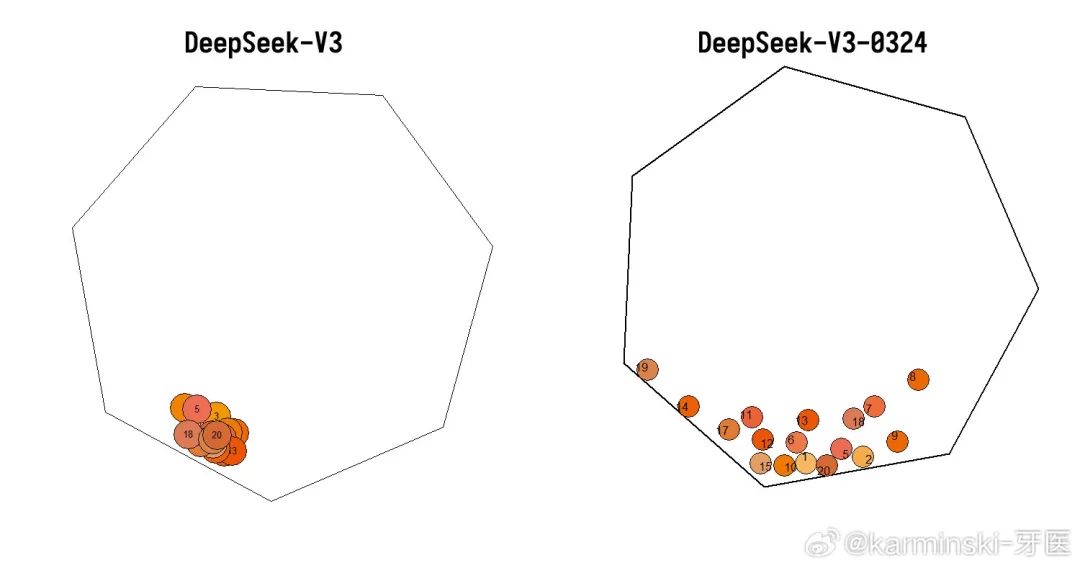
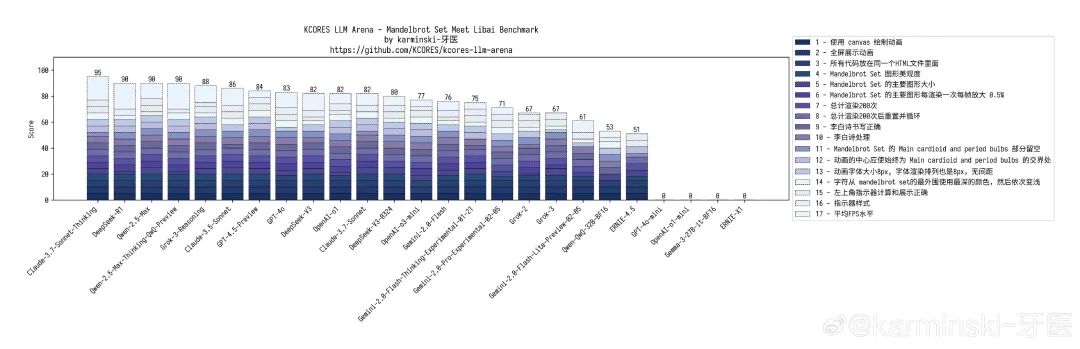
mandelbrot-set-meet-libai 测试 ,没有过多变化,分数较DeepSeek-V3 低了2分,主要还是将渲染方向搞反了以至于拖累了渲染性能,但是完成度可以看到比之前高很多。项目排名第12

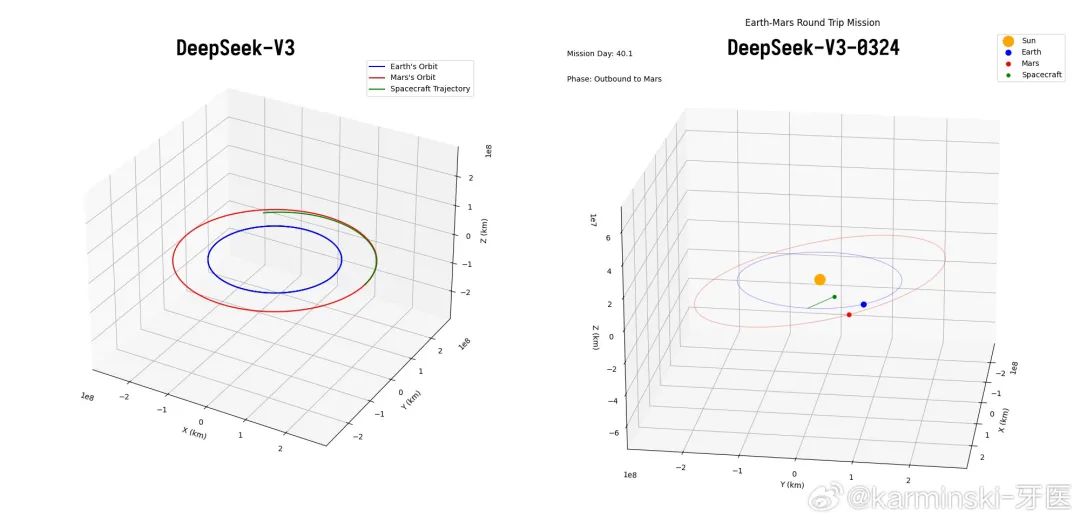
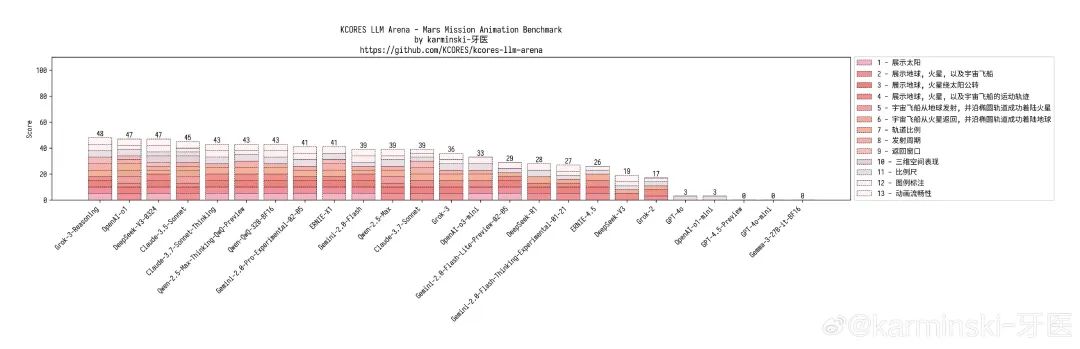
火星任务测试,巨大的提升,这次星球,图例均渲染正确,甚至发射和返回窗口计算也有很大进步!项目排名并列第2
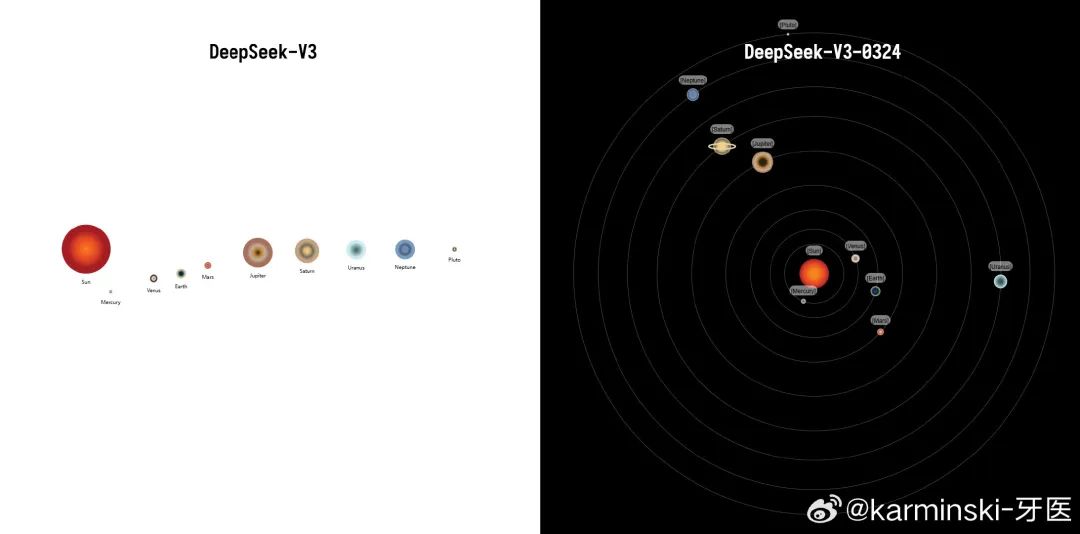
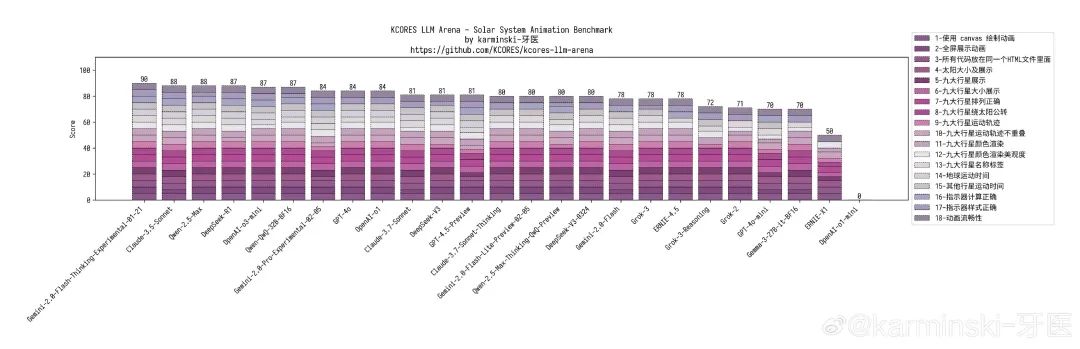
九大行星模拟测试,这个是史诗级提升,这是测试的25个模型中,唯一一个画了土星环的大模型!(画土星环就如同画时钟要写3,6,9,12. 画苹果要有个梗一样)项目排名并列第13,主要还是地球轨道周期没写对
总体而言,DeepSeek-V3-0324 能力十分可怕,甚至这还都不是 DeepSeek-V4,更不是 DeepSeek-R2 !我现在十分期待 DeepSeek-R2 的发布了!
评测是开源的哦,地址:github.com/KCORES/kcores-LLM-Arena



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











