






苹果王牌!FastVLM:iPhone直接跑,速度快85倍!
原创 弑之仟士 创意Ai实验室 2025年05月19日 08:16 四川
近期,苹果低调开源了 FastVLM(Fast Vision-Language Model),一个专为移动设备优化的视觉语言模型(VLM),能在 iPhone、iPad 和 Mac 上直接运行,号称首 token 输出速度比竞品快 85 倍!这波操作不仅展现了苹果在 AI 领域的技术肌肉,还通过开源代码和模型权重,向开发者敞开大门。FastVLM 主打高效、低内存占用和隐私保护,堪称移动端多模态 AI 的新标杆。下面聊聊它的核心亮点、怎么用,以及对用户和行业的意义!
核心亮点:速度快到飞,隐私有保障
根据苹果机器学习研究团队论文(CVPR 2025 接受,arXiv:2412.13303)和 GitHub 仓库(apple/ml-fastvlm),FastVLM 通过全新设计的 FastViTHD 混合视觉编码器,解决了传统 VLM 在高分辨率图像处理上的两大痛点:编码延迟高和视觉 token 过多。它的亮点包括:
- 超快速度
FastVLM-0.5B 模型在 LLaVA-1.5 设置下,首 token 输出时间(TTFT)比 LLaVA-OneVision-0.5B 快 85 倍,比 Cambrian-1-8B(基于 Qwen2-7B)快 7.9 倍。在 1152x1152 高分辨率图像上,整体性能媲美竞品,但视觉编码器体积小 3.4 倍。
- 高效设计
-
- 动态分辨率调整
通过多尺度特征融合,智能识别图像关键区域,减少冗余计算,ImageNet-1K 上降低 47% 计算量。
- 层级 token 压缩
视觉 token 从 1536 个压缩到 576 个(减少 62.5%),大幅降低语言模型负担。
- 硬件优化
针对苹果 A18 芯片和 M2/M4 处理器,优化矩阵运算,支持 CoreML 集成,iPad Pro M2 上实现 60 FPS 连续对话。
- 动态分辨率调整
- 低内存占用
动态 INT8 量化减少 40% 内存使用,保持 98% 精度。0.5B 模型 App 仅占 1.8GB,运行流畅不卡顿。
- 隐私优先
完全本地运行,无需云端上传数据,完美契合苹果的隐私保护理念,适合敏感场景如医疗影像分析。
- 多模态能力
-
-
图像描述:生成生动准确的文本描述。
-
视觉问答(VQA):快速回答图像相关问题,如“图表数据代表什么?”。
-
对象识别:精准识别复杂图像中的物体、文本或数据。
-
实时应用:支持 AR、图像编辑、辅助技术和生产线质检等。
-
实际案例:FastVLM 在肺结节检测中达到 93.7% 准确率,提升 40% 诊断效率;在手机生产线质检中,缺陷误报率从 2.1% 降至 0.7%。
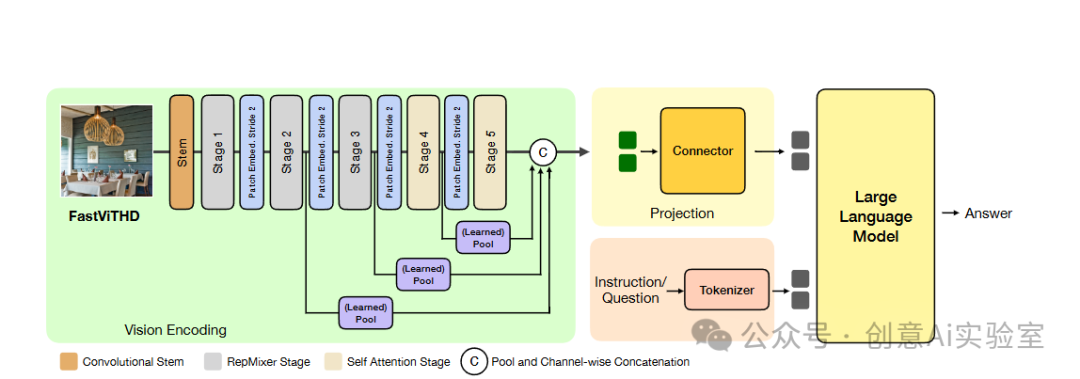
背后的技术:FastViTHD 编码器是关键
FastVLM 的核心在于 FastViTHD 编码器,相较传统视觉变换器(ViT),它通过以下创新实现高效处理:
- 空间重要性预测网络
用轻量卷积层(仅增加 0.3% 参数)计算特征图信息熵,动态分配计算资源,减少冗余。
- 渐进投影训练
分三阶段优化视觉-语言对齐:
-
冻结预训练:用 200 万图文对建立基础映射。
-
低秩适配(LoRA):微调投影矩阵。
-
全参数调优:用高质量指令数据集优化。
-
- 量化优化
FP16 用于 0.5B 模型,INT8/INT4 用于 1.5B/7B 模型,平衡性能和资源占用。
结果是,FastVLM-0.5B 在 SeedBench 和 MMMU 等基准测试中性能媲美 LLaVA-OneVision,却用更少的资源;7B 模型基于 Qwen2-7B,在 COCO Caption 上达到 82.1% 准确率。
背后的技术:FastViTHD 编码器是关键
FastVLM 以 85 倍速 的惊人性能和本地运行的隐私优势,为 iPhone 用户和开发者打开了多模态 AI 的新世界。无论是想让手机秒懂图表,还是开发下一代 AR 应用,FastVLM 都提供了高效、开源的解决方案。唯一的遗憾是 ANE 支持还没跟上,期待苹果后续优化。你觉得 FastVLM 会成为移动 AI 的标杆,还是只是苹果生态的“独角戏”?快留言聊聊,想试 demo 的朋友也来分享下体验!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











