







colmap官方文档:https://colmap.github.io/
colmap官方文档installation部分翻译
https://blog.csdn.net/canon1994/article/details/135474713
【COLMAP官方文档翻译】Tutorial
https://zhuanlan.zhihu.com/p/581870553?utm_id=0
可以看出,colmap也是走的先估计深度图,再对深度图做融合的路线,所以最后一步是点击fusion,对深度图做融合。
https://mp.weixin.qq.com/s/EoFlfXJSEeRdduNDi86CTw
https://blog.csdn.net/X_kh_2001/article/details/82591978
从这看,colmap好像也有二进制版的,直接下载使用,不用编译,而且是在windows上。下面操作主要参考这篇博客。
https://blog.csdn.net/weixin_46229691/article/details/121339352
可以选择下载预编译的二进制文件或手动构建源代码。可从https://demuc.de/colmap/ 下载适用于 Windows 和 Mac 等平台的可执行文件以及其他资源。适用于 Linux/Unix/BSD 的可执行文件可在https://repology.org/metapackage/colmap/versions 上找到。请注意,默认存储库中的 Linux/Unix/BSD 的 COLMAP 软件包不带有 CUDA 支持,需要手动编译,但在这些平台上相对较容易。(摘自colmap官方文档installation部分翻译)
COLMAP 可以通过命令行或图形用户界面作为独立应用程序使用。此外,COLMAP 还构建为可重用的库,即您可以将 COLMAP 包含并链接到您自己的源代码中。(摘自colmap官方文档installation部分翻译)
关于字典树匹配,看下下面这段,下面这段也是从colmap的文档翻译过来的。
https://blog.csdn.net/m0_47488011/article/details/126851868
特征点匹配(Match features)的匹配模式的选择:
穷举匹配(Exhaustive Matching):当你的数据集比较小的时候(小于100张),选择这种模式。这种模式匹配速度足够快并且是最好的效果。每张图片都与其他的所有图片进行匹配。最后生成的块大小取决于你载入内存中的图片的数量。
顺序匹配(Sequential Matching):当你拍照的时候是以连续的方式(比如视频)采集图像的话,这种方式是有用的。连续帧具有视觉重叠。每一帧的图像不必和其他所有图像都进行匹配。只有连续帧匹配就OK了。该模式也有内置的循环检测,第N个图像与其视觉上最为相似的图片匹配。但需要事先训练字典树。https://demuc.de/colmap/ 在这里可以下载。此种方法非常适合在视频序列中大量采用的情况,相比于全局匹配模式大大降低了matching时间。
字典树匹配(Vocabulary Tree Matching):在这种匹配模式下,每张图片都与与他视觉上最相近的经过按空间顺序重新排序的邻居匹配。也需要实现训练好字典树,网页地址同上。
空间匹配(Spatial Matching):这种模式下每个图像均与其空间最近邻居进行匹配。可以在数据库中手动设置空间位置。默认情况下colmap还会从EXIF中获取GPS的相关信息并用来寻找空间上最相近的邻居。如果有准确的先验空间位置信息的话,这种是推荐的匹配模式。
传递匹配(Transitive Matching):这种匹配模式使用已经存在的特征匹配的传递关系来完成更完整的匹配图。例如如果图像A匹配B而B也匹配C,那么colmap将尝试直接匹配A到C。
自定义匹配(Custom Matching):这种模式下允许指定的单个图片去匹配其他图片或者导入指定的已匹配的信息。
我发现自己操作了下colmap之后再看这个课程目录就感觉熟悉清晰了很多,现在真正清楚为什么要讲那些相机模型和匹配策略了,因为都是colmap里的配置选项。

colmap下载准备
我下了一个 COLMAP-3.9.1-windows-no-cuda.zip ,在https://github.com/colmap/colmap/releases ,因为暂时不想弄cuda,所以下的no cuda版本的。
压缩包文件解压之后,第一层目录内容如下:
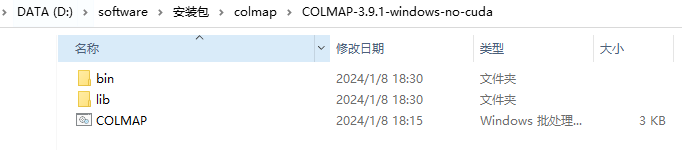
我鼠标双击上面目录里的COLMAP.bat之后,colmap软件有打开,没有报错
然后按照上面博客所说,在 https://demuc.de/colmap/#download 这里下载词汇树
然后我在 https://demuc.de/colmap/datasets/ 这里选了一个数据集下载下来
下载的south-building数据集我解压在一个英文路径下
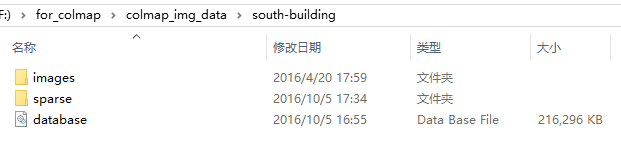
文件夹里的内容分别如下
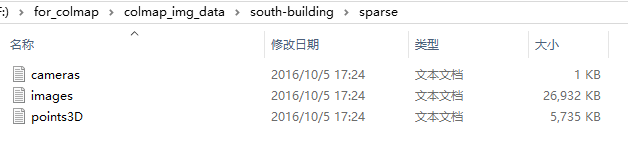
colmap稀疏重建
然后开始
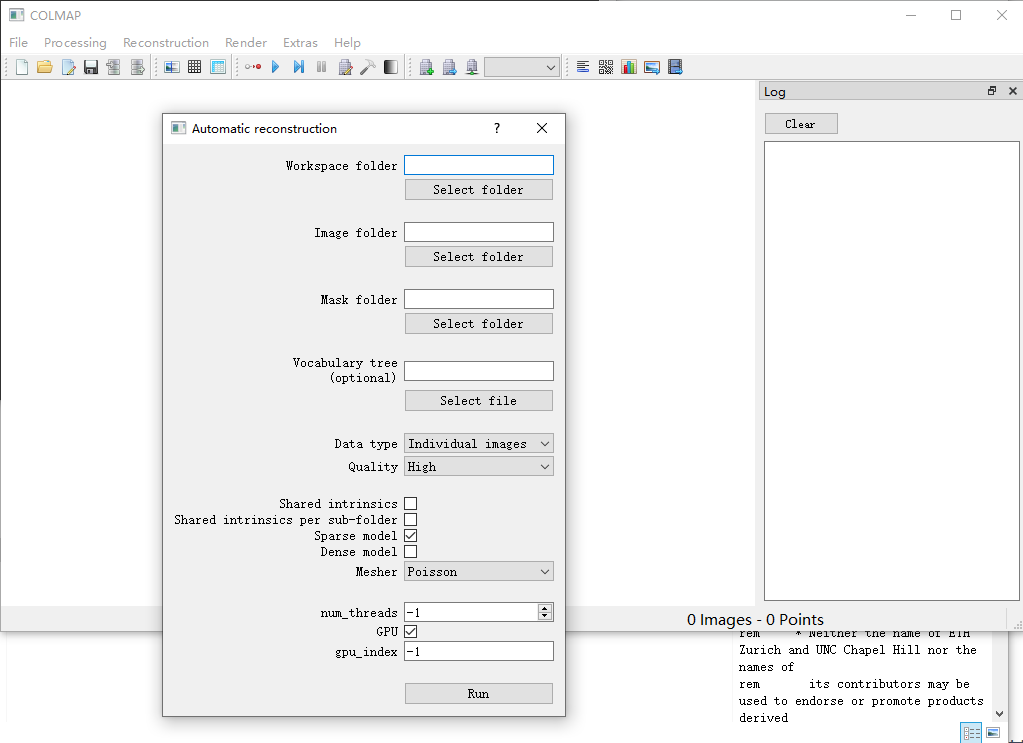
参考下面这个来选,但是我比这里多了个选mesh文件夹。
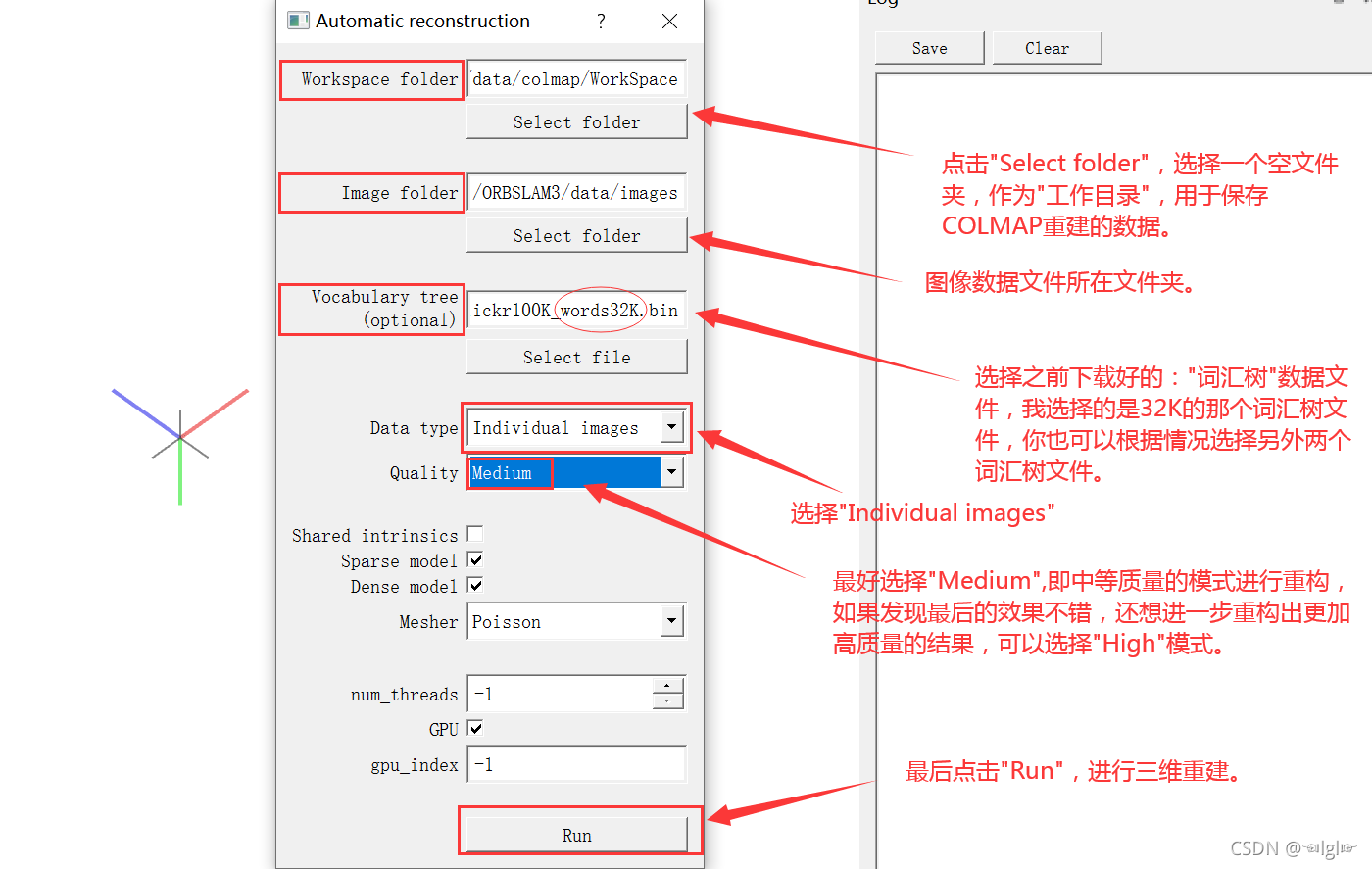
选完点击run
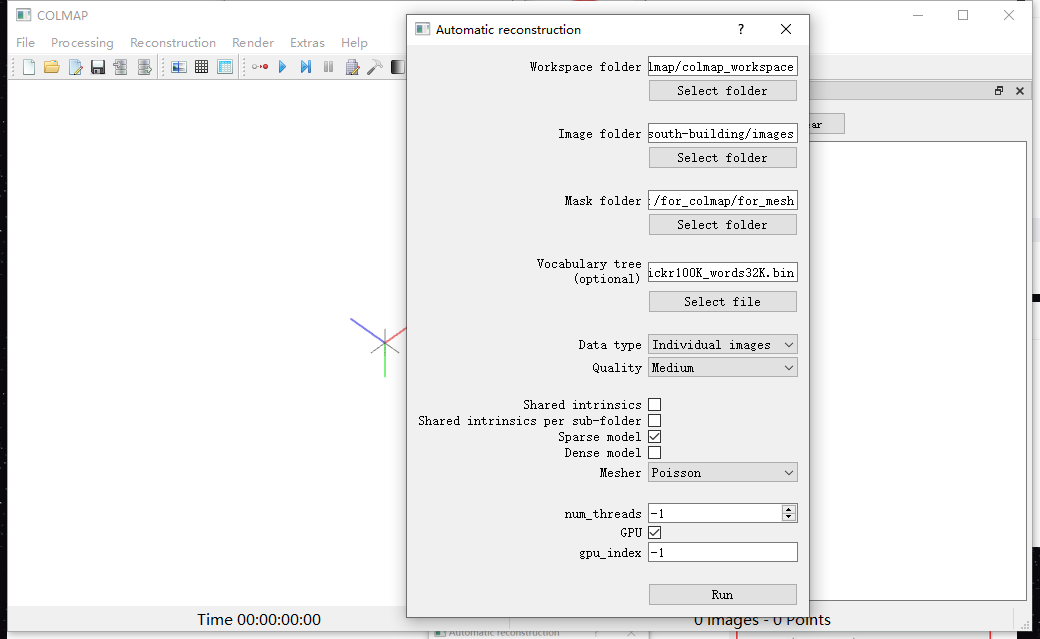
然后据说是漫长的等待,我电脑就在那放着了。
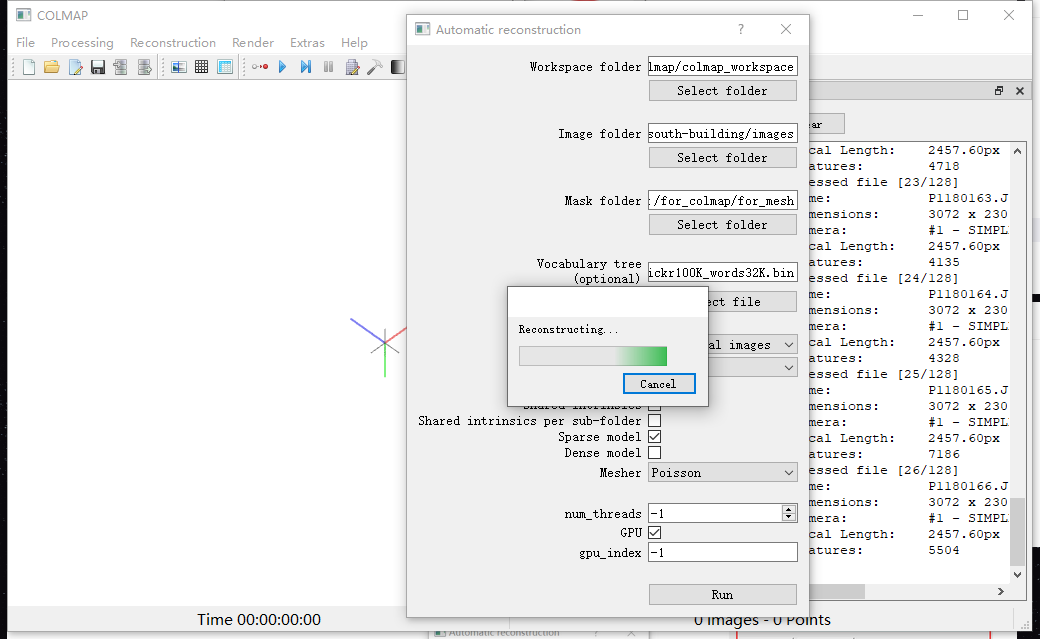
终端也有打印显示
我过一小时再来看时,已经完成,点击OK即可。
放大后如下图所示
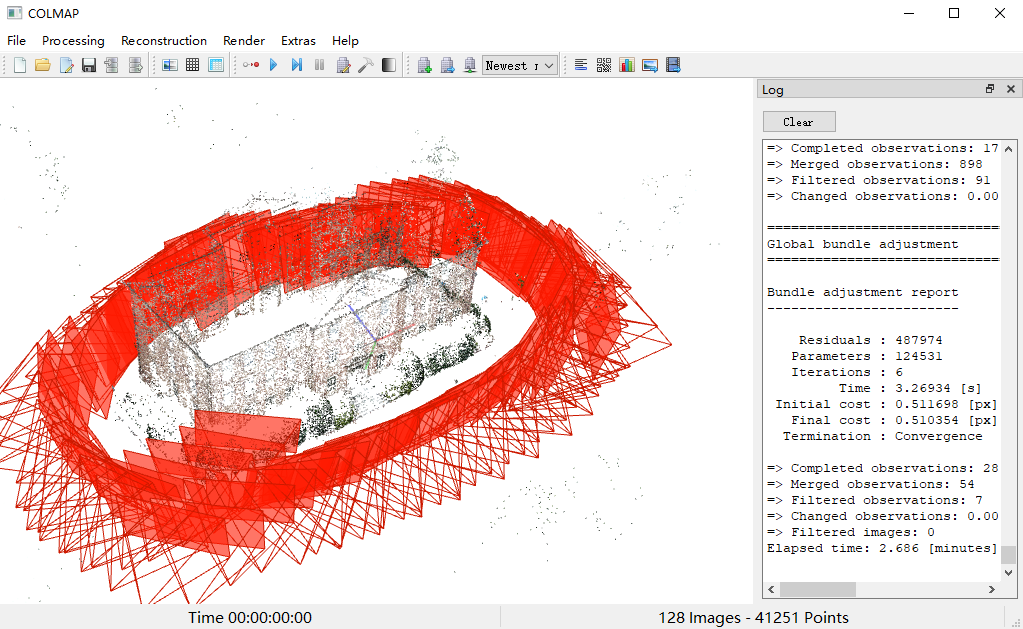
但是好像没有稠密重建的结果啊,mesh文件夹下是空的。
此时的工作空间目录下是这样的
colmap稠密重建
我看了下https://zhuanlan.zhihu.com/p/617362102?utm_id=0 ,我刚才的操作Automatic reconstruction只是稀疏重建,稠密重建还需要继续点Dense reconstruction。
稠密重建点击选择顺序是这样的
【Reconstruction】–> 【Dense reconstruction】
Workspace工作空间,【Select】选择项目目录
【Undistortion】–> 【Stereo】稀疏重建 --> 【Fusion】所有点云融合
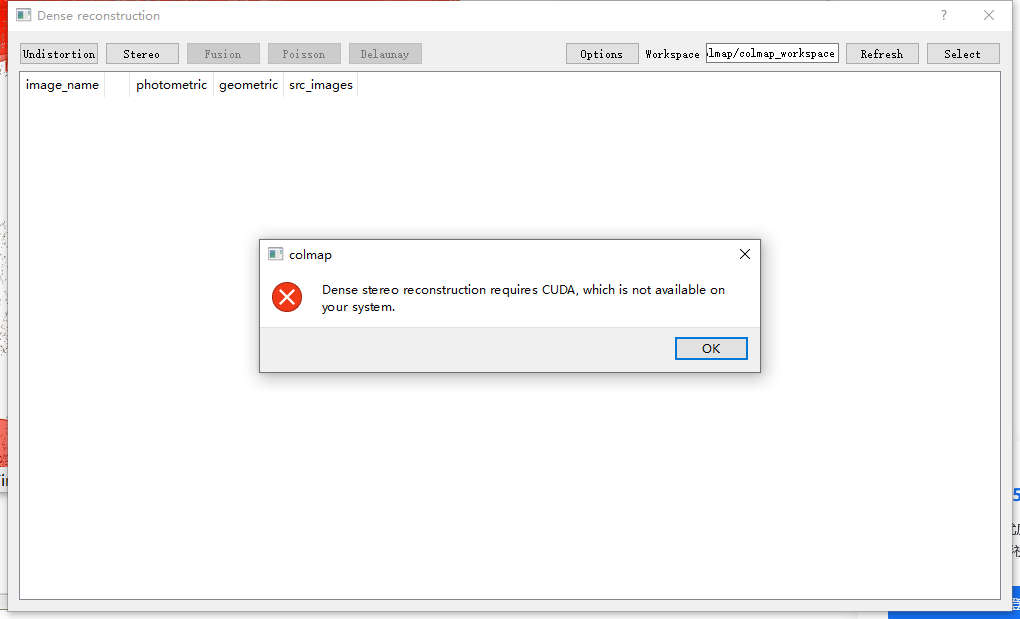
最后说需要CUDA才行,看来装没CUDA版本的colmap还没法稠密重建。
我可以试着下个CUDA版本的colmap,就是不知道我的1060显卡是否带得动。
有几种方法可以查看windows是否安装了CUDA:
- 通过查看NVIDIA显卡驱动程序是否安装了CUDA。在Windows系统中,您可以依次点击“开始”菜单 -> “控制面板” -> “程序” -> “卸载程序”,然后找到NVIDIA驱动程序并检查其版本。如果CUDA被安装,通常可以在驱动程序的版本号中找到相应的标识。
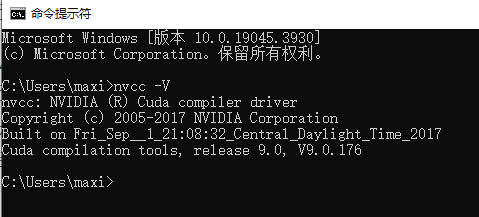
- 打开命令提示符窗口。在Windows系统中,您可以按下Win键 + R键,然后输入“cmd”并按下回车键。在命令提示符窗口中,输入“nvcc -V”并按下回车键。如果您的电脑安装了CUDA,它将显示CUDA的版本信息。
我看了下我的windows
我在 https://github.com/colmap/colmap/releases 下了一个 COLMAP-3.9.1-windows-cuda.zip
下下来后解压,并双击bat文件,可以正常打开

不过我配置完Automatic reconstruction后,点击run运行colmap就立马闪退了。
我百度了下colmap闪退,这里说https://blog.csdn.net/m0_37605642/article/details/115915248
COLMAP突然闪退(程序终止)
问题原因:CUDA显存不足
解决方法:减少图片数量,或者降低图片像素(缩小图片尺寸).
看来确实我1060的显卡不行。
colmap导出系数重建结果
话说前面SFM过程标定出的相机内外参和每帧的位姿如何查看。
在进行稀疏重建之后,model 默认会被导出到 bin 文件中,因为这样比较紧凑,节省空间,可以使用 COLMAP 的模型转换功能将其转换成 txt 文件。 https://www.jianshu.com/p/95cf3a63b6bb
默认情况下,COLMAP使用二进制文件格式(bin,机器可读,速度速)来存储稀疏模型。此外,COLMAP也可以将稀疏模型存储为文本文件(txt,人类可读,速度慢)。在这两种情况下,模型导出的信息被分为关于相机、图像和点云的三个文件。任何包含这三个文件的目录都构成了一个稀疏模型。二进制文件的扩展名是.bin,文本文件的扩展名是.txt。注意,当从包含二进制文件和文本文件的目录加载模型时,COLMAP更倾向于二进制格式。 https://blog.csdn.net/qq_43307074/article/details/127964162
是不是就是这三个Bin文件,分别对应相机内参,图像帧位姿和特征点的位置?我感觉看文件大小也是匹配的。
https://blog.csdn.net/qq_43307074/article/details/127964162
把bin文件导出为txt文件,要在GUI导出文本格式,使用File > Export model as text导出模型。三个文本文件:camera .txt、images.txt和points3D.txt。
camera.txt
这个文件包含了数据集中所有重建相机的内参,每个相机占一行,例如:
# Camera list with one line of data per camera:
# 一行一个相机参数列表
# CAMERA_ID, MODEL, WIDTH, HEIGHT, PARAMS[]
# 相机ID, 相机, 宽, 高, 参数[]
# Number of cameras: 3
1 SIMPLE_PINHOLE 3072 2304 2559.81 1536 1152
2 PINHOLE 3072 2304 2560.56 2560.56 1536 1152
3 SIMPLE_RADIAL 3072 2304 2559.69 1536 1152 -0.0218531
上述数据中,数据集包含 3 个相机,这些相机使用具有相同传感器尺寸(宽度:3072,高度:2304)的不同失真模型。 参数的长度是可变的,取决于相机型号。 对于第一个相机,有 3 个参数,单个焦距为2559.81像素,主点(即 cx,cy)位于像素位置(1536、1152)。相机的内参可以被多个图像共享,这些图像使用唯一标识符 CAMERA_ID 来指代相机。
images.txt
该文件包含数据集中所有重建图像的位姿和关键点,每个图像占两行,例如:
# Image list with two lines of data per image:
# 每张图像数据占两行
# IMAGE_ID, QW, QX, QY, QZ, TX, TY, TZ, CAMERA_ID, NAME
# 图像ID, QW, QX, QY, QZ, TX, TY, TZ, 相机ID, NAME
# POINTS2D[] as (X, Y, POINT3D_ID)
# 2D点坐标和对应3D点ID, 若没有对应的3D点则ID标记为-1
# Number of images: 2, mean observations per image: 2
1 0.851773 0.0165051 0.503764 -0.142941 -0.737434 1.02973 3.74354 1 P1180141.JPG
2362.39 248.498 58396 1784.7 268.254 59027 1784.7 268.254 -1
2 0.851773 0.0165051 0.503764 -0.142941 -0.737434 1.02973 3.74354 1 P1180142.JPG
1190.83 663.957 23056 1258.77 640.354 59070
这里,前两行定义了第一张图片的信息,以此类推。使用四元数 (QW, QX, QY, QZ) 和平移向量 (TX, TY, TZ) 将图像的重建位姿指定为从世界到图像的相机坐标系的投影。四元数是使用 Hamilton 约定定义的,例如,Eigen 库也使用该约定。投影/相机中心的坐标由 -R^t * T 给出,其中 R^t 是由四元数组成的 3x3 旋转矩阵的逆/转置,T 是平移向量。从图像上看,图像的局部相机坐标系定义为 X 轴指向右侧,Y 轴指向底部,Z 轴指向前方。
上面示例中的两个图像都使用相同的相机模型并共享内参 (CAMERA_ID = 1)。映像名称与项目的选定基础映像文件夹相关。第一个图像有 3 个关键点,第二个图像有 2 个关键点,而关键点的位置由像素坐标指定。两幅图像都观察到 2 个 3D 点,并注意第一张图像的最后一个关键点在重建中没有观察到 3D 点,因此 3D 点标识符为 -1。
发现导出的 txt 和示例不一样,找不到第二张图片的信息,苦恼很久,才醒悟是关键点信息太多了,解决办法如下: https://blog.csdn.net/qq_43307074/article/details/128029245?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128029245%22%2C%22source%22%3A%22qq_43307074%22%7D
自己实际用images.txt里面的相机帧位姿时发现需要注意其坐标系,具体如下面所说:
https://blog.csdn.net/weixin_44120025/article/details/124604229
colmap输出的images文件中的四元数Q和平移向量T,是其定义的相机坐标系下的R和t。但是,如果我们要将这些相机放在一起进行可视化的话,那么我们需要首先将其变换到世界坐标系下(这样才能统一)

https://blog.csdn.net/weixin_44671418/article/details/124835964

上面博客写的后来发现也就是3D视觉工坊的那个讲colmap三维重建课程第一节里讲到的。

points3D.txt
该文件包含数据集中所有重建的3D点的信息,每个点占一行,例如:
# 3D point list with one line of data per point:
# 每个点占一行
# POINT3D_ID, X, Y, Z, R, G, B, ERROR, TRACK[] as (IMAGE_ID, POINT2D_IDX)
# POINT3D_ID:三维点的id (二维点可以根据此id找到图片对应的三维点)
# X, Y, Z:三维点坐标
# R, G, B:三维点颜色信息
# ERROR:投影误差(基于像素)
# Number of points: 3, mean track length: 3.3334
63390 1.67241 0.292931 0.609726 115 121 122 1.33927 16 6542 15 7345 6 6714 14 7227
63376 2.01848 0.108877 -0.0260841 102 209 250 1.73449 16 6519 15 7322 14 7212 8 3991
63371 1.71102 0.28566 0.53475 245 251 249 0.612829 118 4140 117 4473
这里有三个重建的 3D 点,其中TRACK[] as (IMAGE_ID, POINT2D_IDX):对应images.txt里的图像id,POINT2D_IDX 定义了 images.txt 文件中关键点的从零开始的索引。比如说上面:16 6542,意思是images.txt中图片ID为16的里面的第6542个点,这个点是该图的特征点,也映射到这个三维点。误差以重投影误差的像素为单位,仅在全局BA后更新。


















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











