






MAE (Masked AutoEncoder):更快!更强!还更简单
原创 OddFan 泛函的范 2024年07月06日 17:23 广东
本文介绍下 Kaiming He 团队在2021年发表的《Masked Autoencoders Are Scalable Vision Learners》。

在 NLP 领域,基于 Masked Autoencoder 的 Self-Supervised Pretraining 方法(如 BERT)取得巨大的成功。相对应的在 CV 领域,比 Masked Autoencoder 更通用的 Denoised Autoencoder 发展却没有那么惊艳。针对这种反差,作者从下面三个方面进行了解释:
-
主流框架不同:在 ViT(2020.10提出) 成为主流之前,CNN 在 CV 领域占主导地位。卷积通常在局部窗口上操作,并不能直接将 "指示符"(如 Mask Tokens 和 Positional Embedding)整合到卷积网络中。而 Transformer 框架是 NLP 领域的为主流,专为 Token 和 positional embedding 而生。好在这个问题在 ViT 出现之后就不是问题了。
-
语言和图像的信息密度不同:语言是人类创造的,具有高度语义和信息密集。而图像则是自然产生的信息,在空间上是高度冗余的。因此,让模型预测被 Mask 掉的信息时,语言很难通过其周围的信息讲它推测出来,而图像则很容易通过周围内容来还原该内容。因此,针对图像,需要 Mask 掉更多的部分,才能使任务更具挑战性,从而促使模型学到更好的抽象特征表示。
-
Decoder 的角色不同:在 CV 中,Decoder 重构的是图像像素,是低阶语义信息(比传统识别任务信息层级更低)。而在 NLP 中,Decoder 重构的是单词(或 Token),是高阶语义信息。因此,在 NLP 中,Decoder 可以很简单(如 MLP)。而对 CV 来说,Decoder 的设计对所学到的潜在表示的语义级别具有关键作用。
基于上面三个方面的分析,作者提出了 CV 中的 MAE(Masked AutoEncoder)通过随机 Mask 掉图片中一定比例 Patch,然后重构这些 Patch 的像素值,来学习图像的抽象表示。如下图所示:

作者使用普通的 ViT-Huge 模型在 ImageNet-1K(IN1K)的训练集上进行 Self-Supervised Pretraining,得到了比当时所有已知方法都要好的效果,Top-1 Accuracy 达到了 87.8%。
一、Vision Transformer(ViT)
由于 MAE 是基于 ViT 设计的,在具体了解 MAE 之前,有必要先简单回顾下 ViT 框架,如下图所示:
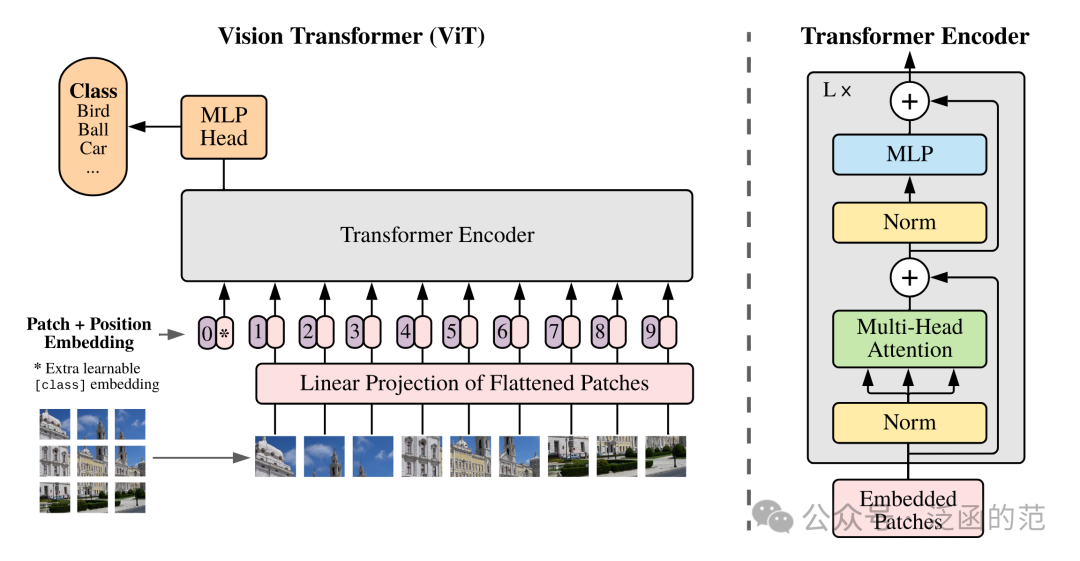
ViT 最早发表在 ICLR 2021 的《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,其核心思想是将图像分割成一组不重叠的图块(Patch),每个图块通过一层线性映射转换为对应的向量表示。然后将这些向量和对应图块的位置信息以序列的形式输入给 Transformer Encoder。Encoder 由多个自注意力层和前馈神经网络层组成,用于对图块之间的关系进行建模和特征提取。
在训练过程中,ViT 可以在大规模图像数据集上进行监督学习,来优化模型参数。而在推断阶段,ViT 可以用于图像分类、物体检测、图像分割等各种计算机视觉任务。ViT 能够更好地捕捉全局图像信息,在一些任务上取得了与 CNN 相媲美甚至更好的效果。
二、Masked AutoEncoder(MAE)
MAE 是一种简单的自编码方法,它根据部分观测来重构原始信号。与所有 AutoEncoder 一样,MAE 同样包含一个 Encoder(用于将观测信号映射为潜在表示),和一个 Decoder(用于从潜在表示中重构原始信号)。与传统的 AutoEncoder 不同的是,MAE 采用了非对称设计:Encoder 仅在部分观测到的信号上操作(无需掩码标记),并采用轻量级 Decoder,从潜在表示和掩码标记中重构完整信号。MAE 框架如下图所示:
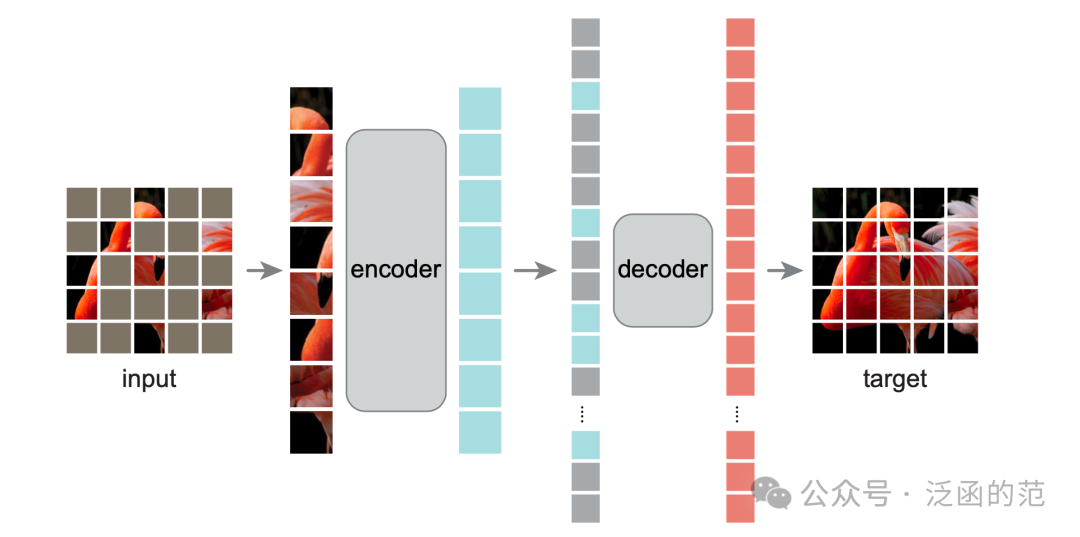
MAE 方法的特点:高 Masking ratio 的随机抽样策略、非对称的编、解码器设计 和 像素值重构目标。
2.1、Masking
首先,论文沿用 ViT 论文的做法,将图像分割成规则的、不重叠的图块。然后对图块进行随机抽样,并 Mask 掉(即移除)其余的图块。
-
随机抽样:按照均匀分布随机选择不重复得图块进行抽样
高 Masking Ratio 的随机抽样,即移除大部分(如75%)的图块,大大减少了信息冗余,从而构造了一个不能通过从相邻的可见图块进行外推来轻松解决的任务。论文中对比了不同 Masking ratio 的效果,发现无论是 fine-tuning 还是 linear probing,masking ratio 在 75% 左右时效果比较好。
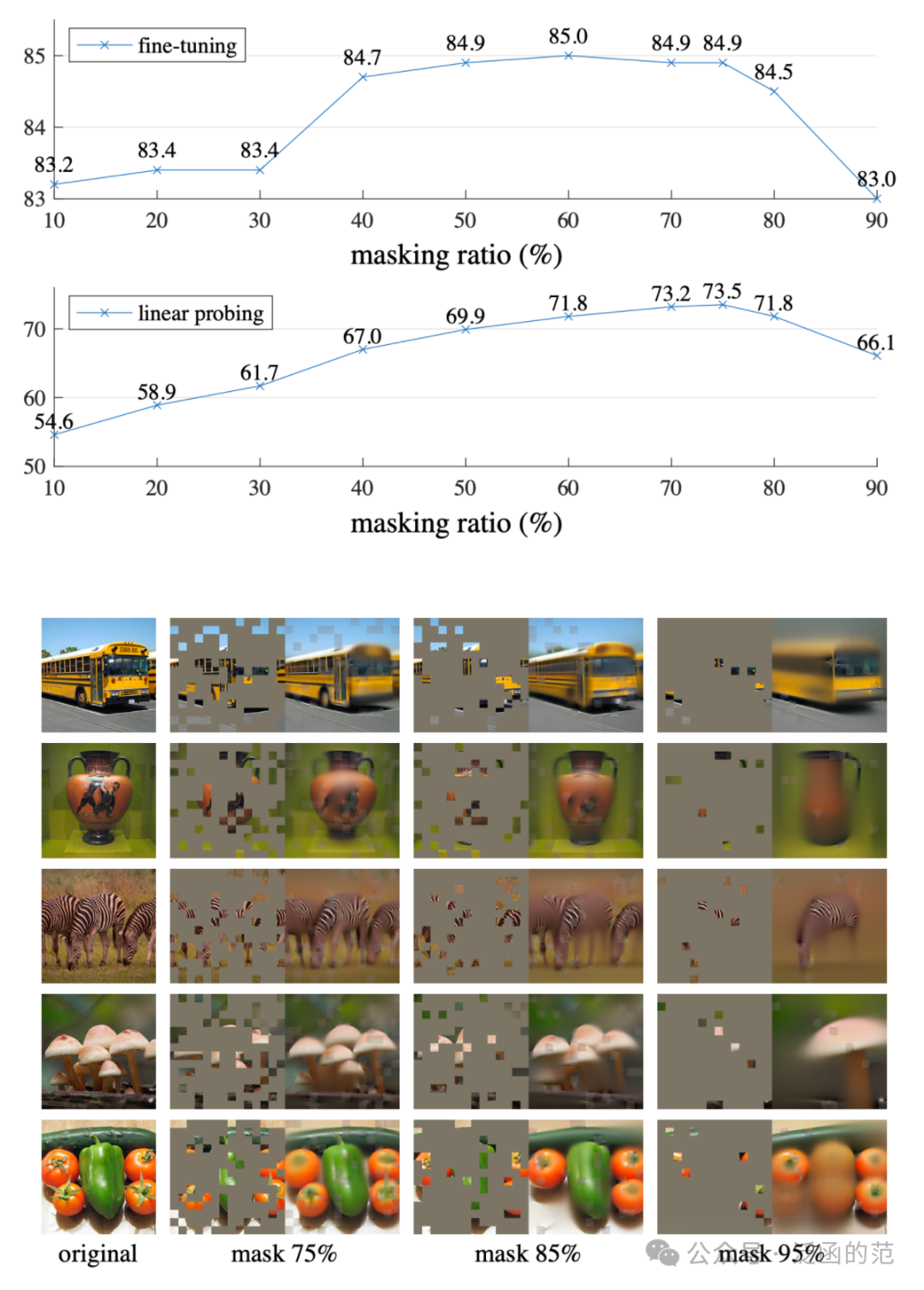
均匀分布 则避免了潜在的中心偏差(即图像中心附近 Mask 掉的图块更多)。如下图所示,作者对比了不同 采样策略的效果,发现采用均匀分布采样的效果更好。

需要注意的是 block-wise masking(上图中间)是将图中较大的图快移除,这使得同样 masking ratio下任务更难。MAE 在 50% block-wise masking 时效果较好,而进一步增大到 75% 时,效果出现明显下降。
2.2、Encoder
Encoder 仅处理可见的、未 Mask 掉的图块,如下图红框部分。与标准的 ViT 一样,Encoder 通过线性投影和添加位置信息对图块进行 Embedding,并通过一系列 Transformer Block 对结果进行处理。

由于 Mask 掉的图快被移除,Encoder 仅在一个小子集(如25%)上操作,使得我们能使用更少的计算资源和内存来训练更大的 Encoder。如下图所示,Encoder 中移除 Mask掉的图块不仅对计算量有大幅降低,还能提升采用 linear probing 方式的下游任务的性能。

主要原因是预训练和下游任务之间存在 Gap:如果将 Mask Token 引入到 Encoder 中,会导致Encoder 的输入中有很大一部分是 Mask Token,而这在未经破坏的图像中是不存在的。这种 Gap 会降低下游任务的准确性。将Mask掉的图快的掩码标记从 Encoder 中移除能限制 Encoder 始终只看到真实的图块,从而提高准确性。
2.3、Decoder
如下图红框所示,Decoder 的输入由两部分组成:(1) 编码了的可见图块,和 (2) 掩码标记。每个掩码标记是一个共享的、可学习的向量,用于指示待预测的缺失图块的存在。此外,为了让掩码标记能够表示它们所在图像中的位置信息,作者在每个标记集中添加了Position Embedding。最后,Decoder 由一系列 Transformer Block 组成。
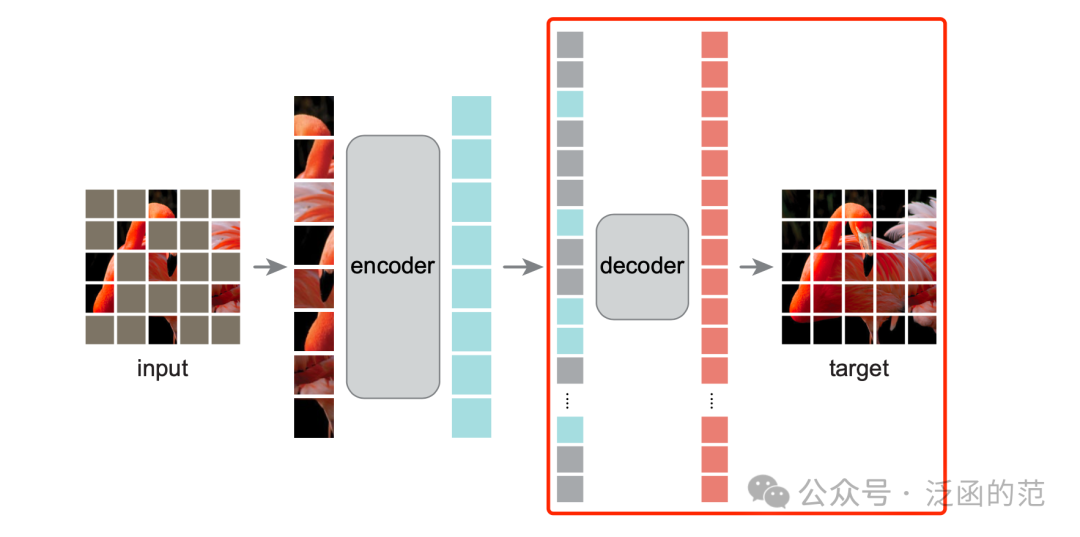
需要注意的是,Decoder 仅在预训练期间用于执行图像重构任务,而用于下有任务的图像表示仅由 Encoder 生成。因此,Decoder 的架构可以灵活设计,独立于 Encoder 的设计。通过这种非对称的设计,完整的 Token 集可以仅由轻量级 Decoder 处理,从而显著减少了预训练时间。
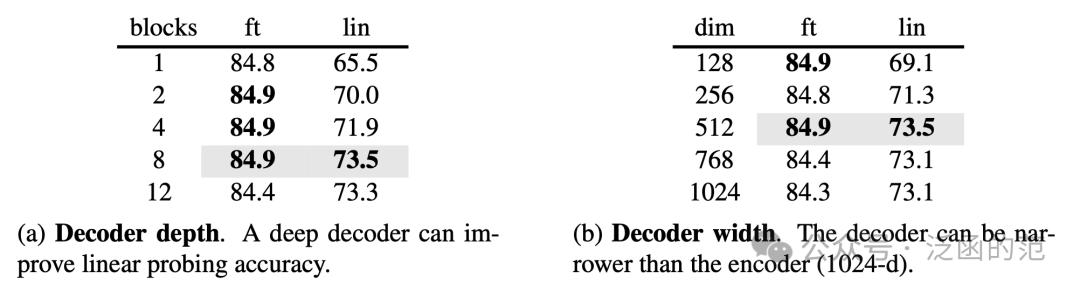
如下图所示,采用不同深度和宽度的 Decoder,对下游任务中采用 fine-tuning 模式下的效果影响不大,但对 linear probing 方式的任务影响较大(预训练任务与下游任务存在Gap)。
2.4、Reconstruction target
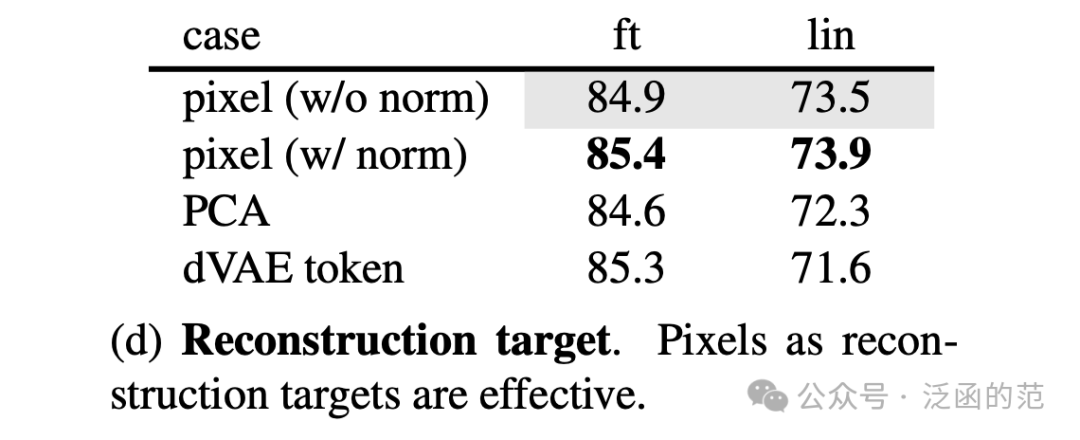
MAE 通过预测每个 Mask 掉的图块的像素值来重构输入。因此,Decoder 输出的每个元素都是表示一个图块的像素值向量。Decoder 最后一层是一个线性映射,其输出通道数等于一个图块中的像素值数量。最终,输出被重新 Reshape 成重构的图像大小。与 BERT 做法类似,Decoder 采用 MSE 在算像素空间中计算 Mask 掉的重构图像与原始图像之间的 Loss。
此外,作者指出使用归一化像素值作为 target 可以提高表示效果。具体而言,计算一个图块中所有像素的均值和标准差,然后使用它们来对该图块进行归一化。
三、Usage
现在已经有很多实现好的 MAE 包和预训练好的模型,我们可以很方便的应用起来,如Hugging-Face中:
# 来源:https://huggingface.co/docs/transformers/model_doc/vit_mae
from transformers import AutoImageProcessor, ViTMAEModel
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
Conclusion
本文介绍了在 CV 领域进入 Transformer 时代时具有里程碑意义的方法 MAE,通过随机 Mask 掉图片中较高比例 Patch,然后重构这些 Patch 的像素值,使我们能通过 Self-Supervised Pretraining 方式来预训练图像 Encoder 模型。MAE 通过高Masking ratio方式构造更难的任务,使模型能学到更抽象的图像表示,提升下游任务的效果。MAE 成功将 CV 从基于CNN的 Supervised Pretraining 推向基于 ViT 的 Self-Supervised Pretraining 的新阶段。
公众号
References
[1] He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 16000-16009.
[2] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[3] ViTMAE. Hugging Face. https://huggingface.co/docs/transformers/model_doc/vit_mae. 2022.
[4] Ritvik Rastogi. Masked Autoencoder: Vision Transformer. https://www.kaggle.com/code/ritvik1909/masked-autoencoder-vision-transformer. 2022.


















 8928
8928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











