




大语言模型框架-Megatron-LM源码分析
原创 MLOps社区 DeepPrompting 2023年11月11日 11:44 北京
Megatron-LM是NVIDIA开源的大语言模型框架,是很多披露的大语言模型的训练使用的源头框架,很多公司基于其二次开发新的语言模型系统,例如Megatron-LM-DeepSpeed。
Megatron核心解决问题就是提供多种分布式切分并行策略,让大语言模型能够部署在多卡分布式环境下。本文将针对,张量并行,流水并行,数据并行的实现展开源码分析。MoE我们可以当成一种特殊的稀疏化结构,就不在本章进行介绍。
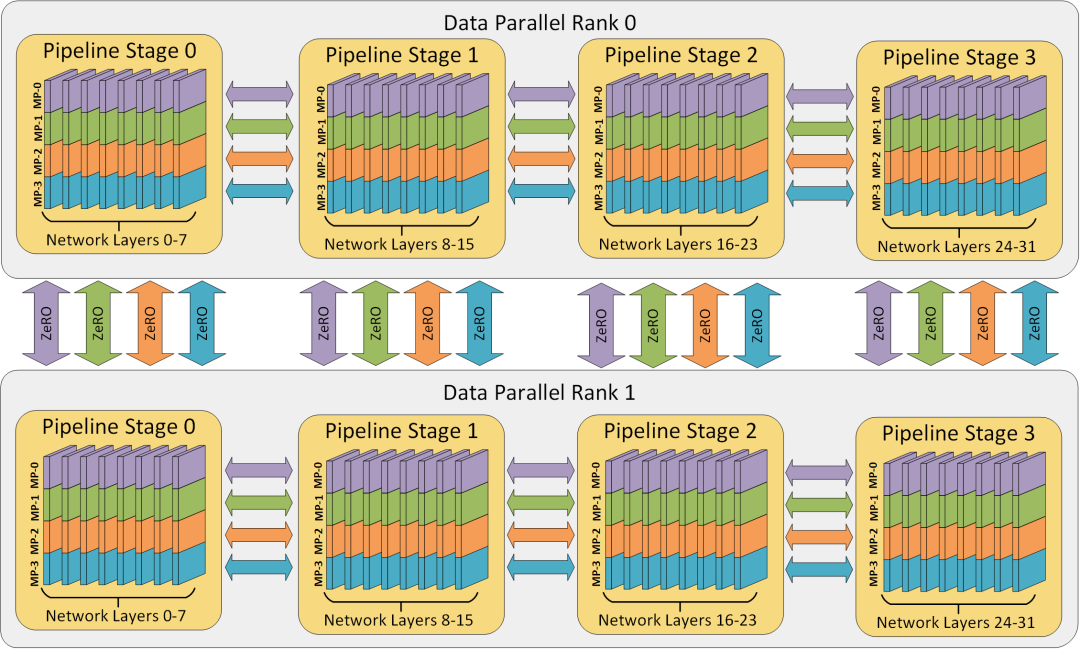
图片来自DeepSpeed(本文不介绍ZeRO,感兴趣读者可参考相关论文)
1 张量并行
张量并行分为行切和列切并行(指的是对输入矩阵切法),具体读者可以参考Megatron论文,其实现方式是继承实现Linear层,进而实现其中的并行策略,只需要替换模型中的Linear即可,后面我们也会看到MoE也是这种实现技巧。
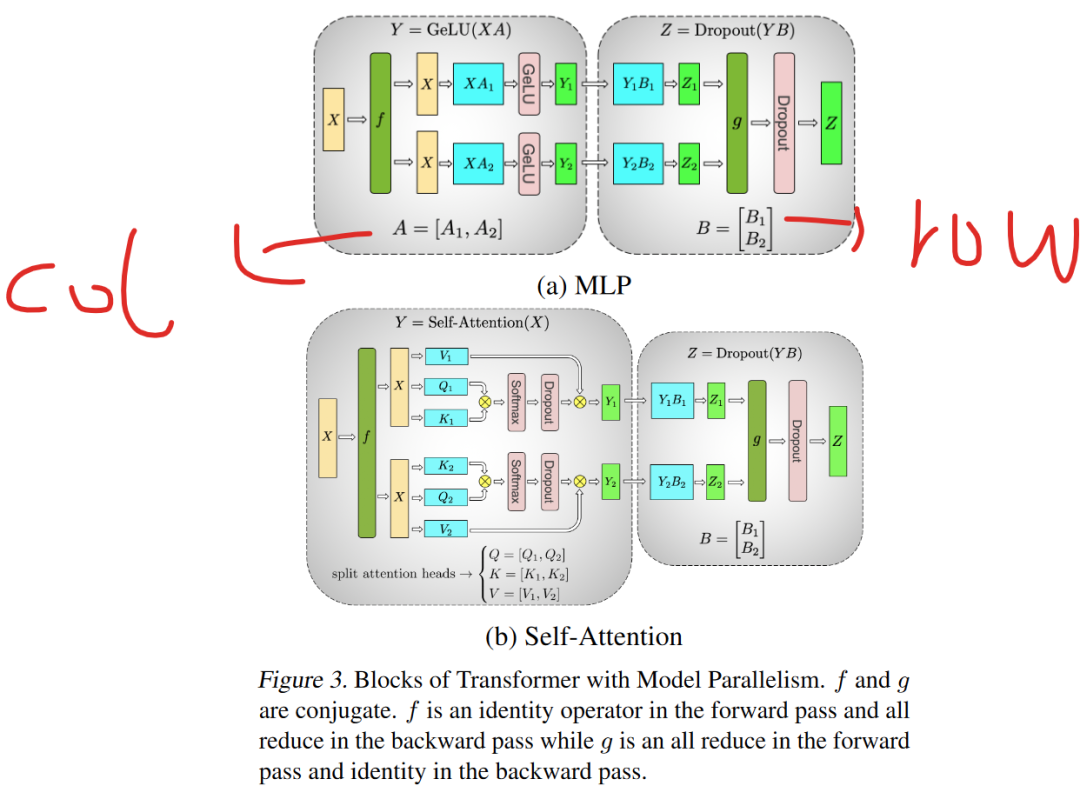
图来源Megatron-LM
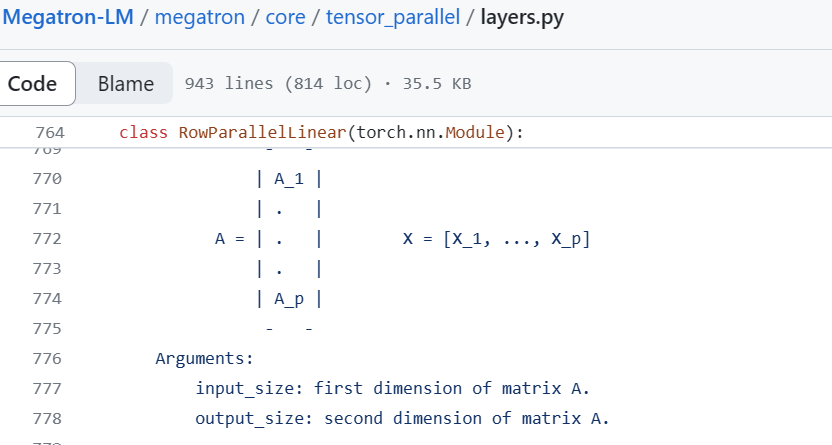
world_size = get_tensor_model_parallel_world_size()
self.input_size_per_partition = divide(input_size, world_size)通过这部分代码进行并行partition划分,worldsize是配置的tensorparallel的卡数,将完整input切成这么多份数,在每个执行这个代码的rank进行权重创建。
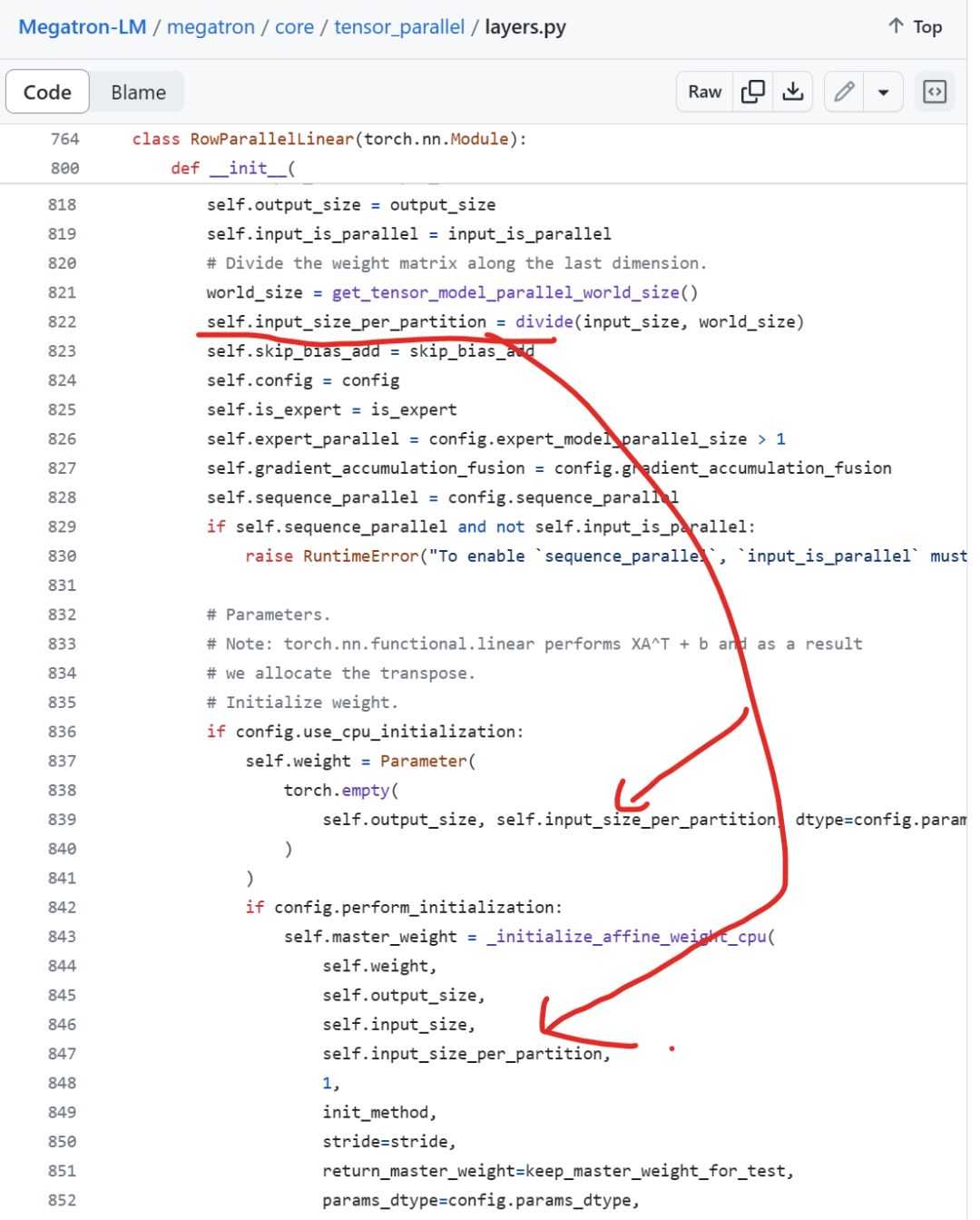
如果输入不是并行切分好的,通过scatter去拿这部分权重对应的输入数据。
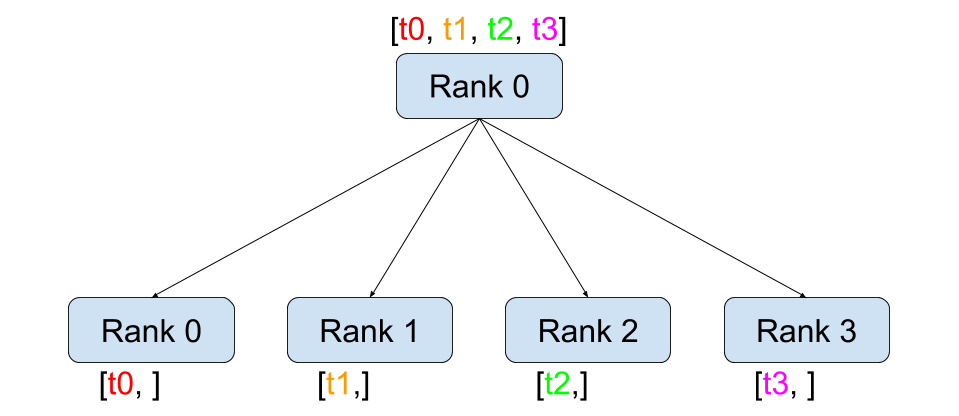
scatter[图来源PyTorch官网]
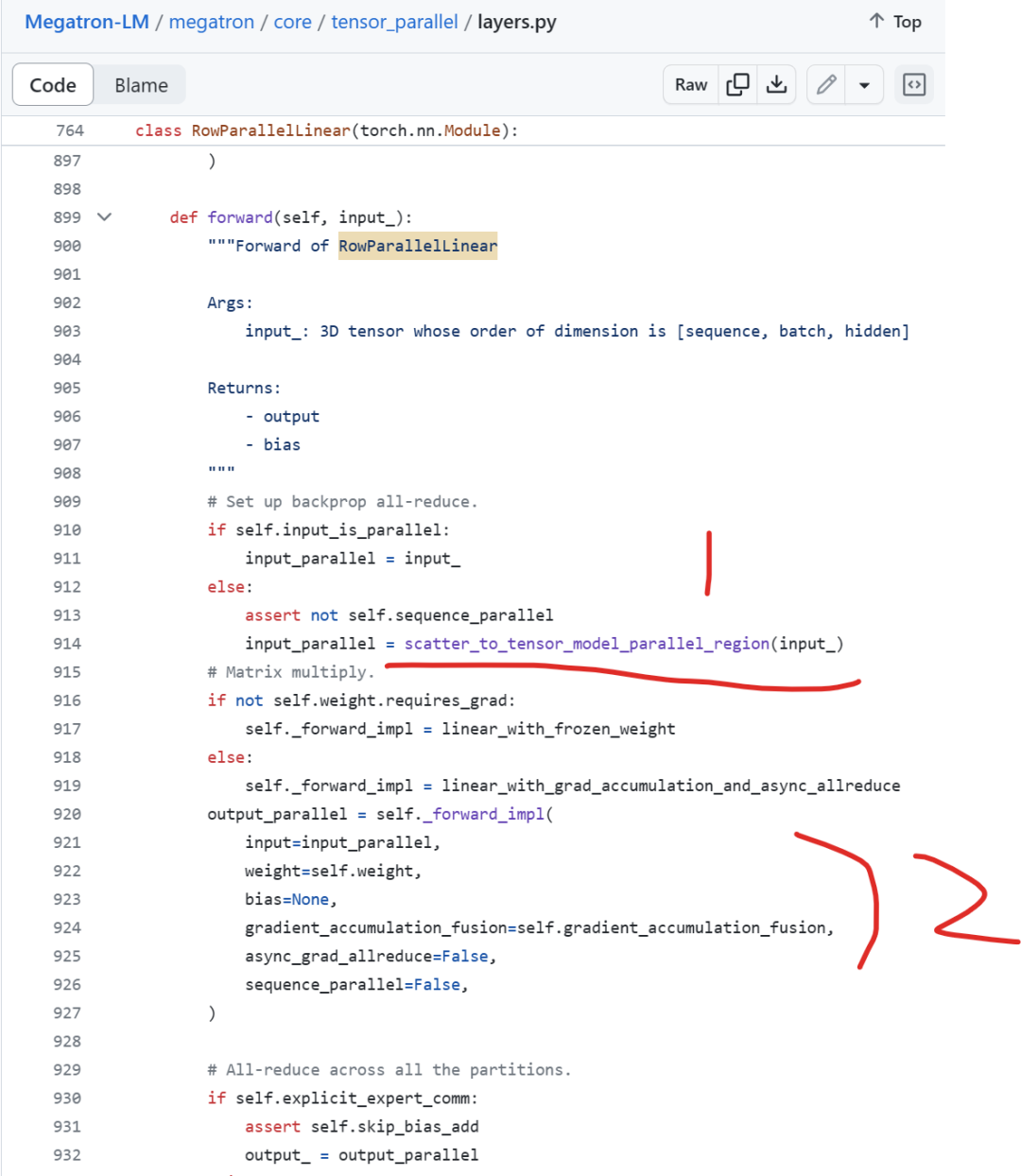
forward实现是配合异步allreduce进而将计算和comm通信并发执行。


async_grad_allreduce (b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











