






成本最高直降100倍!大模型清洗与蒸馏数据的高效方法
原创 SiliconCloud 硅基流动 2024年12月13日 18:08 北京
随着大模型规模的增加,以及持续改进性能的必然要求,拥有大量数据比模型架构本身或计算能力更为重要,甚至,现在数据在大模型领域几乎就是一切。
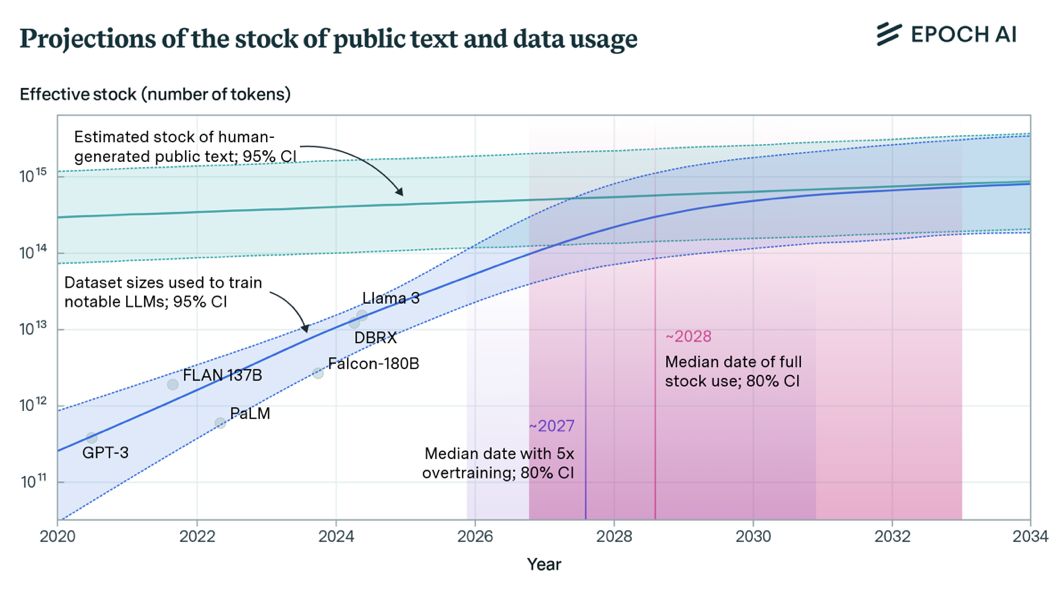
现实情况是,对多数生成式AI企业与研究机构而言,获取高质量数据及特定领域数据具有很高门槛。此外,根据调研机构Epoch AI预测[1],人类生成的公开文本总量约为300万亿个Token,语言模型会在2026年至2032年将这些数据消耗殆尽。
在AI大模型的推动下,业界对使用顶尖大模型蒸馏数据、合成数据来推动数据预处理阶段变革的兴趣显著增加。
尤其在预训练以及微调领域,Llama 3.3、o1-preview、QwQ、AlphaZero等大模型使用合成数据在编码、逻辑推理和长上下文等任务进行训练,并展现出强实用性。针对医疗、金融和法律等垂类应用,不少机构正通过算法大量调用上述大模型API来清洗及蒸馏数据,以训练/微调垂类大模型,实现在该领域与通用大模型相当甚至更优性能。比如,上海交通大学GAIR研究组通过蒸馏OpenAI o1的长思维链数据,然后进行监督微调,开发出比原版模型效果更好的模型[2]。
现实情况无一不在说明,如果不通过大模型本身解决数据问题,你将无法构建高质量、高价值的AI模型与产品。
大模型在数据预处理中的场景与案例
从头构建大规模、全面的数据集来训练大模型是一个耗时、高成本且具有挑战性的过程。以往,你可能需要花费数周精心制作诸多数据集,现在,利用大模型进行数据预处理,能在非常短的时间内生成类似效果的高数据,进而推动高效、可扩展的AI模型训练,帮助生成式AI组织大幅降低构建AI产品的数据障碍。
以下是一些具体应用案例:
-
利用大模型清洗数据:电商平台拥有大量的产品描述数据,这些数据来源多样,格式不一,包含大量冗余信息、错别字等。通过大模型可以自动对产品描述进行清洗,从而提高数据质量,使得后续的数据分析、产品推荐等业务更加准确有效。
-
利用大模型做数据抽取:在很多行业内,处理文本、图像和音频文件等非结构化数据既耗时又费力。基于大模型识别数据中的模式、关系和上下文的能力,可以将非结构化文本数据执行关键词提取、分类、总结和摘要等任务。比如,企业可以利用大模型分析外卖平台的用户评论情绪,通过文本分类、情感分析和主题建模,从大量文本数据中提取有价值的洞见和见解,以帮助客户改善服务质量。
-
用合成数据蒸馏学生模型:利用大模型生成的合成数据高效训练“学生”模型,为开发者和企业提供一种快速、低成本的定制化模型创建方式。
利用大模型做大规模数据预处理已是必然趋势。与此同时,Meta的Llama等顶尖模型允许开发者使用其模型输出来改进其他模型,通过蒸馏数据、合成数据将推动生成式AI取得新进展。
当然,开发者与企业也非常在意,如何获取高性价比的大模型服务进行数据预处理?
MaaS服务:高效、经济的数据预处理选择
一般而言,企业在使用大模型服务进行蒸馏数据、合成数据的挑战在于,对模型吞吐能力要求高、模型输出速度快、成本敏感,且阶段性爆发式调用需要稳定、可靠的服务。这时,调用第三方大模型API(MaaS服务)在很大程度帮助开发者与企业省心省力。
以硅基流动提供的大模型云服务平台SiliconCloud为例,基于高性能大模型推理引擎加速,平台提供极速输出、服务稳定、品类多样的高性价比API服务,开发者与企业可根据自身业务需求随时调用包括QWQ、DeepSeek 2.5、llama3.3、FLUX.1等在内的数十种大模型,按需计费。对于需求量大、要求严苛的场景,SiliconCloud也可提供专属资源、与其他用户隔离互不影响。
在实际应用中,一家日平均Token调用量数十亿的SiliconCloud客户发现,相比调用GPT-4o的API服务来做数据预处理,SiliconCloud这样的MaaS平台是更经济、高效的方式。
首先,相比GPT-4o的数据生成质量,调用Qwen2.5、DeepSeek 2.5这样的开源大模型同样能满足客户自身业务场景的高质量数据需求。
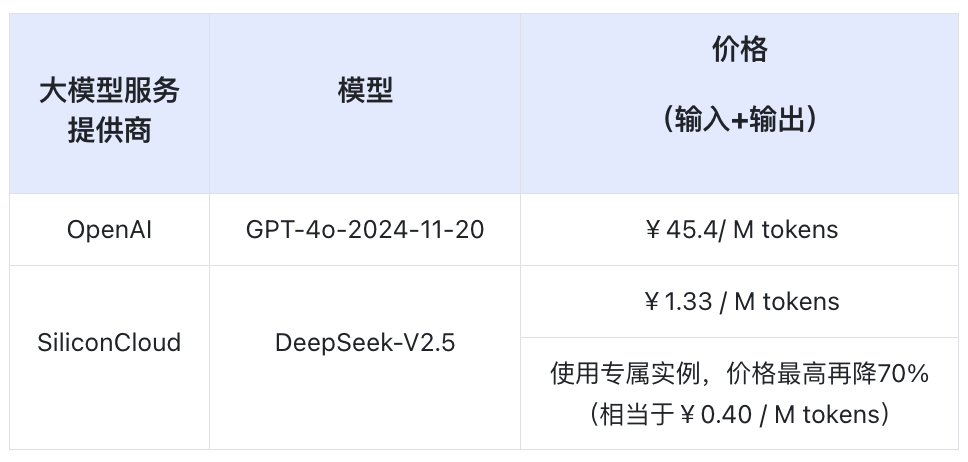
其次,在计算成本方面,调用SiliconCloud具有更高的性价比。如果调用OpenAI官方的GPT-4o-2024-11-20,输入输出的平均价格为$6.25/1M tokens(约为¥45.4/M tokens,其中输入价格为$2.5/1M tokens,输出价格为$10/1M tokens,按场景中输入和输出的长度相等,未启用输入缓存)计算,而调用SiliconCloud平台的DeepSeek-V2.5,按¥1.33/M tokens(输入/输出)计算,比GPT-4o低约34倍;而该客户使用的是SiliconCloud提供的专属实例,成本最高可再降70%以上,总体比调用GPT-4o低约114倍。
此外,基于该客户的不同业务场景的需求,他们需要调用多个LLM来处理数据,以利用不同LLM的独特优势,确保为每个特定任务使用最合适的模型,从而提高准确度、相关性和性能。例如,他们的法律客户需要使用专门针对法律术语和文档分析优化的LLM,而医疗客户需要另一个专门医学数据的LLM,该客户可在SiliconCloud上任意对比数十种模型的数据处理效果,从而选择与不同业务需求最匹配的模型。
值得一提的是,SiliconCloud已上线模型微调,最快3分钟就可以帮你打造专属大模型,同时,自动托管功能上线后,客户可在平台上一站式解决数据预处理、专有模型微调及部署需求,大幅降低生成式AI应用开发的门槛与成本。
基于SiliconCloud API进行数据合成
1. 设置对应环境变量
load_dotenv()# 获取环境变量API_KEY = os.getenv('SILICONFLOW_API_KEY')if API_KEY is None:print("API_KEY not found in environment variables")else:print("API_KEY loaded successfully")client = OpenAI(api_key=API_KEY, # 从https://cloud.siliconflow.cn/account/ak获取base_url="https://api.siliconflow.cn/v1" # 此处使用硅基流动Qwen2.5-72B-Instruct来进行数据处理)# choose one of these API providers: "SF" or "OAI"API_PROVIDER = "SF"MODEL_NAME = "Qwen/Qwen2.5-72B-Instruct" # 使用 SiliconCloud 的模型
SEED = 42N_SAMPLE = 20 # 可以采样部分数据以加快测试。设为 False 则运行完整数据集,设为整数则进行采样SELF_CONSISTENCY_ITERATIONS = 3 # 模型应尝试预测相同文本的次数,用于自一致性检查DATA_SUBSET = "sentences_allagree" # 数据子集选择:"sentences_allagree", "sentences_66agree", "sentences_75agree"
2. 设置对应Prompt
# prompt is inspired by the annotator instructions provided in section "Annotation task and instructions"# in the financial_phrasebank paper: https://arxiv.org/pdf/1307.5336.pdfprompt_financial_sentiment = """\You are a highly qualified expert trained to annotate machine learning training data.Your task is to analyze the sentiment in the TEXT below from an investor perspective and label it with only one the three labels:positive, negative, or neutral.Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.Do not provide any explanations and only respond with one of the labels as one word: negative, positive, or neutralExamples:Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.Label: positiveText: The company generated net sales of 11.3 million euro this year.Label: neutralText: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.Label: negativeYour TEXT to analyse:TEXT: {text}Label: """prompt_financial_sentiment_cot = """\You are a highly qualified expert trained to annotate machine learning training data.Your task is to briefly analyze the sentiment in the TEXT below from an investor perspective and then label it with only one the three labels:positive, negative, neutral.Base your label decision only on the TEXT and do not speculate e.g. based on prior knowledge about a company.You first reason step by step about the correct label and then return your label.You ALWAYS respond only in the following JSON format: {{"reason": "...", "label": "..."}}You only respond with one single JSON response.Examples:Text: Operating profit increased, from EUR 7m to 9m compared to the previous reporting period.JSON response: {{"reason": "An increase in operating profit is positive for investors", "label": "positive"}}Text: The company generated net sales of 11.3 million euro this year.JSON response: {{"reason": "The text only mentions financials without indication if they are better or worse than before", "label": "neutral"}}Text: Profit before taxes decreased to EUR 14m, compared to EUR 19m in the previous period.JSON response: {{"reason": "A decrease in profit is negative for investors", "label": "negative"}}Your TEXT to analyse:TEXT: {text}JSON response: """
更多操作详情请查看:https://github.com/siliconflow/siliconcloud-cookbook/blob/main/examples/synthetic-data/synthetic_data_creation_simple.ipynb[3]
结语
利用大模型在数据预处理阶段进行数据优化,已成为生成式AI领域改进大模型性能的优先选择。在本文中,我们介绍了使用大模型进行数据优化与增强的场景及具体案例,并分析了在满足业务需求的数据质量前提下,调用SiliconCloud这样的MaaS服务是更具性价比的选择。未来,生成式AI将进一步通过大模型自身的数据处理能力来解决高质量数据获取的难题。
参考资料:
[1]https://epochai.org/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
[2]https://github.com/GAIR-NLP/O1-Journey/blob/main/resource/report-part2.pdf
[3]https://github.com/huggingface/blog/blob/main/zh/synthetic-data-save-costs.md
近期更新
• SiliconCloud上线DeepSeek-V2.5-1210
• SiliconCloud上线HunyuanVideo
• SiliconCloud上线Fish Speech 1.5
• 3分钟用SiliconCloud轻松打造专属LLM
• SiliconCloud上线Llama-3.3-70B-Instruct
• SD3.5上线ControlNet三件套,BizyAir已支持



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











