







全文总结
本文介绍了Suphx,这是一个基于深度强化学习的AI系统,用于玩四人日本麻将(立直麻将)。Suphx采用了全局奖励预测、Oracle指导和运行时策略适应等新技术,展示了比大多数顶级人类玩家更强的表现。
研究背景
- 研究问题: 这篇文章旨在解决如何构建一个能够在复杂的不完美信息多人游戏中表现出色的AI系统,特别是针对麻将这种具有复杂规则和丰富隐藏信息的游戏。
- 研究难点: 麻将的复杂性主要体现在以下几个方面:
- 复杂的计分规则: 每局麻将包含多个回合,最终排名由各回合累积得分决定。每局的输赢并不总是能直接反映玩家的表现。
- 丰富的隐藏信息: 每个玩家有13张私人牌,死墙有14张牌,活墙有70张牌,总共超过10^48种不可区分的隐藏状态。
- 复杂的玩法规则: 包括不同的动作类型(如立直、吃、碰、杠、弃牌)以及打断常规顺序的特殊情况(如形成杠或立直)。
研究方法
这篇论文提出了Suphx,用于解决麻将AI的挑战。具体来说,
- 全局奖励预测: 训练一个预测器来预测基于当前和前几轮信息的最终奖励。这个预测器提供了有效的学习信号,使得策略网络的训练得以进行。此外,设计了前瞻特征来编码不同获胜手牌及其获胜分数的可能性,以支持RL代理的决策。
- Oracle指导: 引入了一个可以看到完美信息的Oracle代理,包括其他玩家的私人牌和墙牌。在RL训练过程中,逐渐从Oracle代理中丢弃完美信息,最终将其转换为只能输入可观测信息的普通代理。通过Oracle代理的帮助,普通代理的改进速度比仅利用可观测信息的标准RL训练快得多。
- 参数化蒙特卡罗策略适应: 由于麻将的复杂玩法规则导致不规则的游戏树,防止了蒙特卡罗树搜索技术的应用,因此引入了参数化蒙特卡罗策略适应(pMCPA)来提高代理的运行时性能。pMCPA在在线游戏阶段逐步修改和适应离线训练的策略,以应对当前回合中更多的可观测信息。
实验设计
- 数据收集: 使用来自Tenhou平台的人类职业玩家的日志数据进行监督学习。
- 实验设置:
- 分布式强化学习: 使用策略梯度方法和重要性采样处理异步分布式训练中的轨迹陈旧问题。
- 全局奖励预测: 使用两层门控循环单元(GRU)和两个全连接层的循环神经网络作为奖励预测器。
- Oracle指导: 通过逐步丢弃完美特征,将Oracle代理转换为普通代理。
- 参数化蒙特卡罗策略适应: 在每局开始时,模拟10万条轨迹,并使用基本策略梯度方法对离线训练的策略进行微调。
结果与分析
- 监督学习: 各模型的训练数据量和测试准确率如下:
- 弃牌模型: 1500万样本,测试准确率为76.7%。
- 立直模型: 500万样本,测试准确率为85.7%。
- 吃模型: 1000万样本,测试准确率为95.0%。
- 碰模型: 1000万样本,测试准确率为91.9%。
- 杠模型: 400万样本,测试准确率为94.0%。
- 强化学习: 训练了几个麻将代理,包括SL(监督学习代理)、RL-basic(基本强化学习代理)、RL-1(增强版RL-basic,加入全局奖励预测)和RL-2(进一步增强版RL-1,加入Oracle指导)。实验结果表明,RL-basic比SL有显著改进,RL-1优于RL-basic,RL-2相对于RL-1也有额外提升。
- 运行时策略适应: 在每局开始时,模拟10万条轨迹并微调策略。实验结果显示,适应后的版本在对抗非适应版本时的胜率为66%,证明了运行时策略适应的优势。
结论
Suphx是目前最强的麻将AI系统,也是第一个在Tenhou.net上超越大多数顶级人类玩家的麻将AI。尽管Suphx表现优异,但仍有很大的改进空间。未来的工作包括:
- 改进奖励预测器: 考虑更多信息以提供更好的奖励信号,例如通过比较不同玩家的初始手牌来衡量游戏的难度。
- 优化Oracle指导: 探索同时训练Oracle代理和普通代理的方法,或者设计Oracle评论家以提供更有效的即时反馈。
- 增强运行时策略适应: 在每局中进行多次模拟和适应,以进一步提高策略性能。
Suphx在麻将AI领域的突破展示了深度强化学习在处理复杂不完美信息游戏中的潜力,这些技术也有望应用于金融预测和物流优化等现实世界问题。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在麻将这种复杂的多玩家不完全信息游戏中,设计一个能够超越人类顶级玩家的AI系统。
- 研究难点:麻将游戏的复杂性主要体现在以下几个方面:
- 复杂的得分规则:每局游戏包含多轮,最终排名由多轮得分累计决定,单轮得分不能直接作为反馈信号。
- 丰富的隐藏信息:每个玩家有最多13张私有牌,墙牌中有14张死牌和70张活牌,导致每个信息集有超过10^48种不可区分的状态。
- 复杂的游戏规则:包括多种行动类型(如立直、吃、碰、杠、弃牌)以及打断常规出牌顺序的情况(如鸣牌、和牌、抢杠)。
- 相关工作:近年来,游戏AI的研究逐渐从简单的完全信息游戏(如围棋、国际象棋、将棋)和多玩家不完全信息游戏(如德州扑克、星际争霸II)发展到更复杂的多人不完全信息游戏(如麻将、桥牌)。之前的研究在得分规则简单、隐藏信息较少的游戏中取得了显著成果,但在麻将这种复杂游戏中仍有较大差距。
研究方法
这篇论文提出了Suphx(超级凤凰),用于解决麻将AI的问题。具体来说,
-
全局奖励预测:训练一个预测器来预测基于当前和前几轮信息的最终奖励。该预测器提供了有效的学习信号,使得策略网络的学习可以进行。此外,设计了前瞻特征来编码不同和牌方式及其得分,以支持RL代理的决策。
-
神谕指导:引入一个可以看到完美信息的神谕代理(包括其他玩家的私有牌和墙牌)。在RL训练过程中,逐步减少神谕代理的完美信息,最终将其转换为仅使用可观察信息的正常代理。在神谕代理的帮助下,正常代理的进步速度比仅使用可观察信息的标准RL训练快得多。
-
参数化蒙特卡罗策略适应(pMCPA):由于麻将的复杂游戏规则导致无法应用蒙特卡罗树搜索技术,引入了pMCPA来提高代理的运行时性能。pMCPA在每轮开始时,根据初始手牌逐步修改和适应离线训练的策略。
具体公式如下:
θa=argθmaxτ∼θoT(h)∑R(τ)p(τ;θo)p(τ;θ),
其中,T(h) 是具有前缀 h 的轨迹集合,p(τ;θ) 是策略 θ 生成轨迹 τ 的概率。
实验设计
- 数据收集:从Tenhou平台收集了人类职业玩家的游戏日志,用于监督学习和RL训练。
- 实验设置:在Tenhou平台上进行在线评估,Suphx在专家房间进行了超过5000场比赛,达到了10段的记录等级和8.74段的稳定等级。
- 对比对象:与多个AI和人类顶级玩家进行对比,包括Bakuuchi、NAGA和人类顶级玩家。
结果与分析
-
监督学习结果:五个模型的测试准确率分别为:弃牌模型76.7%、立直模型85.7%、吃模型95.0%、碰模型91.9%、杠模型94.0%。
-
强化学习结果:通过多次实验验证了RL组件的价值,结果表明RL-basic、RL-1和RL-2分别比SL、RL-basic和RL-1有显著提升。
-
运行时策略适应结果:适应性RL-2在与非适应性版本的对局中胜率为66%,证明了运行时策略适应的优势。
-
在线评估结果:Suphx在Tenhou平台的稳定等级超过了99.99%的人类玩家,成为第一个在Tenhou达到10段记录的AI。
总体结论
Suphx是目前最强的麻将AI系统,也是第一个在Tenhou平台上超越大多数人类顶级玩家的AI。尽管取得了显著成果,但仍有改进空间,如进一步优化全局奖励预测、探索更多的神谕指导方法和改进运行时策略适应。Suphx的技术在金融市场监管和物流优化等实际应用中具有巨大潜力。
论文评价
优点与创新
- 全球奖励预测:引入了全局奖励预测器,能够在多轮游戏中预测最终奖励,为策略网络的学习提供了有效的信号。
- 神谕引导:通过逐步减少神谕代理的完美信息访问,最终将其转换为普通代理,显著加速了强化学习的训练过程。
- 参数化蒙特卡罗策略适应:设计了参数化蒙特卡罗策略适应(pMCPA)方法,能够在每轮游戏中根据新的观察信息调整离线训练的策略,提高了运行时的性能。
- 深度卷积神经网络:采用了深度卷积神经网络作为模型架构,展示了其在处理复杂游戏信息方面的强大能力。
- 多种技术结合:将监督学习、自我对弈强化学习和运行时策略适应等多种技术结合起来,解决了麻将游戏中的复杂规则和隐藏信息问题。
- 在Tenhou平台上的卓越表现:在Tenhou平台上达到了10段的记录排名,超过了大多数顶级人类玩家。
不足与反思
- 奖励信号的设计:当前的奖励预测器输入信息有限,未来考虑利用完美信息(如不同玩家的初始手牌比较)来衡量游戏的难度,并提升奖励预测器。
- 神谕引导的进一步优化:除了逐步过渡到普通代理的方法外,还可以同时训练神谕代理和普通代理,让神谕代理向普通代理知识蒸馏,或者在设计神谕评论家方面进行探索。
- 运行时策略适应的改进:当前系统在每轮开始时进行模拟,未来可以考虑在游戏进行中继续进行模拟,以进一步提高策略的性能。此外,逐步适应策略可以减少每一步的采样和回滚次数,从而在在线对战中实现更高效的策略适应。
关键问题及回答
问题1:Suphx在训练过程中使用了哪些具体的技术来应对麻将游戏的复杂性?
- 全局奖励预测:训练一个预测器来预测基于当前和前几轮信息的最终奖励。该预测器提供了有效的学习信号,使得策略网络的学习可以进行。此外,设计了前瞻特征来编码不同和牌手及其得分,以支持RL代理的决策。
- 神谕指导:引入一个可以看到所有完美信息的神谕代理(包括其他玩家的私有牌和墙牌)。在RL训练过程中,逐步减少神谕代理的完美信息,最终将其转换为仅使用可观察信息的正常代理。
- 参数化蒙特卡罗策略适应(pMCPA):由于麻将规则的复杂性导致不规则的游戏树,无法应用蒙特卡罗树搜索技术,因此引入了pMCPA来提高代理的运行时性能。pMCPA在每轮进行时逐步修改和适应离线训练的策略。
这些技术共同帮助Suphx在复杂的麻将游戏中超越了人类顶级玩家。
问题2:Suphx在Tenhou平台上的表现如何,与其他AI和人类玩家相比有何优势?
- 记录等级:Suphx在Tenhou平台上达到了10段的记录等级,这是第一个达到这一成就的AI。
- 稳定等级:Suphx的稳定等级为8.74段,超过了大多数达到10段的人类玩家。在Tenhou的官方排名中,Suphx的稳定等级超过了99.99%的人类玩家。
- 对比对象:与之前的AI如Bakuuchi和NAGA相比,Suphx在稳定等级上有显著提升。与多位达到10段的人类玩家相比,Suphx在实际游戏中的表现更为稳定和出色。
- 统计结果:Suphx在防守方面非常强大,具有很低的上手率和很低的第四名率。这些统计数据表明,Suphx不仅在得分上表现优异,而且在游戏的整体策略上也更为出色。
问题3:Suphx在未来的研究方向有哪些可能的改进?
- 全局奖励预测的进一步优化:考虑更多信息和游戏难度来设计更好的奖励信号。例如,可以通过比较不同玩家的初始手牌来衡量游戏的难度,并据此调整奖励。
- 神谕指导的进一步研究:包括同时训练神谕代理和普通代理的方法,或者设计一个神谕批评家,提供更有效的状态级即时反馈,以加速策略函数的训练。
- 运行时策略适应的改进:例如在游戏进行中持续进行模拟和策略调整,而不是仅在每轮开始时进行一次。这样可以进一步利用有限的计算资源,并在整个游戏中持续改进策略。
这些改进有望进一步提升Suphx的性能,使其在复杂的麻将游戏中更加强大。
苏帕克斯:利用深度强化学习掌握麻将
李俊杰,1 小林智之,2 叶启伟,1
刘国庆,3 王超,4 杨瑞涵,5 赵丽,1
秦涛,1 刘铁岩,1 洪小文,1
1 微软亚洲研究院
2 京都大学
3 中国科学技术大学
4 清华大学
5 南开大学
摘要
人工智能(AI)在许多领域取得了巨大成功,游戏AI自AI诞生之初就被广泛认为是其滩头阵地。近年来,游戏AI的研究逐渐从相对简单的环境(例如,完美信息游戏如围棋、国际象棋、将棋或双人不完美信息游戏如德州扑克)演变到更为复杂的环境(例如,多人不完美信息游戏如多玩家德州扑克和星际争霸II)。麻将是全球流行的多人不完美信息游戏,但由于其复杂的玩法/计分规则和丰富的隐藏信息,对AI研究来说非常具有挑战性。我们设计了一款名为苏帕克斯的麻将AI,基于深度强化学习,并引入了一些新技术,包括全局奖励预测、神谕指导和运行时策略适应。苏帕克斯在稳定排名方面的表现超过了大多数顶尖人类玩家,并在天凤平台上的官方排名人类玩家中评分超过99.99%。这是计算机程序首次在麻将领域超越大多数顶尖人类玩家。
1 引言
构建游戏超人工智能程序是人工智能(AI)的一个长期目标。过去二十年,游戏AI取得了巨大进展(2,3,11,13,15,16,18)。最近的研究逐渐从相对简单的完全信息或双人游戏(例如,将棋、国际象棋、围棋和德州扑克)发展到更复杂的不完全信息多人游戏(例如,桥牌(12)、Dota(1)、星际争霸II(21)和多玩家德州扑克(4))。
麻将是一种多轮次、基于牌的不完全信息多人游戏,拥有数亿全球玩家。在麻将的每一轮中,四位玩家相互竞争,争取首先完成获胜的手牌。构建强大的麻将程序对当前的游戏AI研究提出了巨大挑战。
首先,麻将有着复杂的计分规则。每场麻将包含多轮,游戏的最终排名(以及相应的奖励)由这些轮次的累计得分决定。一轮的失败并不总是意味着该玩家在该轮表现不佳(例如,如果玩家在前面几轮有优势,他/她可能会策略性地输掉最后一轮以确保获得游戏的头名),因此我们不能直接使用轮次得分作为学习的反馈信号。此外,麻将有大量的可能获胜手牌。这些获胜手牌彼此之间可能非常不同,不同的手牌会导致该轮的不同获胜得分。这样的计分规则比之前研究的棋类游戏如国际象棋、围棋等要复杂得多。专业选手需要仔细选择构成何种胜利手牌,以便权衡该回合的胜利概率和得分。
其次,在麻将中,每位玩家手中都有多达13张私有牌对其他玩家不可见,而14张死墙牌在游戏中对所有玩家都不可见,还有70张活墙牌,一旦被玩家打出和丢弃就会变得可见。因此,平均来说,对于玩家的每一个信息集(一个决策点),都有超过1048个隐藏状态对他/她来说是不可区分的。如此大量的隐藏信息使得麻将成为一种比之前研究的如德州扑克等不完全信息博弈游戏要难得多。麻将玩家很难仅凭自己手中的私有牌来判断哪个行动是好的,因为一个行动的优劣高度依赖于其它玩家的私有牌以及所有人不可见的墙牌。因此,人工智能也很难将奖励信号与观察到的信息联系起来。
第三,麻将的玩法规则复杂:(1) 有多种不同类型的行动包括立直、吃、碰、杠、弃牌;(2) 在和牌(宣布胜利手牌)、碰或杠时,常规的出牌顺序可以被中断。由于每位玩家最多可以有13张私密牌,很难预测这些中断,因此我们甚至无法构建一个常规的游戏树;即使我们构建了游戏树,这样的树在一个玩家的连续行动之间会有大量的路径。这阻止了之前成功应用于像蒙特卡洛树搜索(Monte-Carlo tree search)和对偶遗憾最小化(counterfactual regret minimization)等游戏的直接应用。
由于上述挑战,尽管有几次尝试(7-9,20),但最好的麻将AI仍然远远落后于顶尖的人类选手。
在这项工作中,我们构建了Suphx(意为超级凤凰),一个用于4人日本麻将(立直麻将)的AI系统,这是世界上最大之一的麻将社区。Suphx采用深度卷积神经网络作为其模型。这些网络首先通过监督学习从人类职业玩家的日志中训练,然后通过自我对弈强化学习(RL)进行提升,以网络作为策略。我们使用流行的政策梯度算法(policy gradient algorithm)进行自我对弈RL,并引入了几项技术来解决上述挑战。
-
全局奖励预测训练一个预测器,基于当前轮次和之前轮次的信息来预测游戏的最终奖励(在几轮之后)。这个预测器提供有效的学习信号,以便执行策略网络的训练。此外,我们设计了预见性特征来编码不同获胜手及其本轮得分丰富的可能性,作为我们强化学习代理决策的支持。
-
神谕引导引入了一个神谕代理,该代理可以看到完美的信息,包括其他玩家的私密牌和墙牌。由于(不公平的)完美信息访问,这个神谕代理是一个非常强大的麻将AI。在我们的强化学习训练过程中,我们逐渐从神谕代理中去掉完美信息,最终将其转换为只以可观察信息作为输入的普通代理。在神谕代理的帮助下,我们的普通代理比仅利用可观察信息的标准强化学习训练进步得快得多。
-
由于麻将复杂的游戏规则导致游戏树不规则,阻碍了蒙特卡洛树搜索技术的应用,我们引入了参数化蒙特卡洛策略适应(pMCPA),以提高我们代理的运行时性能。pMCPA在在线对战阶段逐步修改并适应离线训练的策略,以适应特定轮次,此时游戏还在继续,有更多可观察的信息(如四名玩家丢弃的公共牌)。
我们在最受欢迎且具有竞争力的麻将平台Tenhou(19)上评估了Suphx,该平台拥有超过350,000名活跃用户。Suphx在Tenhou达到了10段,其稳定等级描述了一个玩家的长期平均表现,超越了大多数顶尖人类玩家。
2 Suphx概览
在本节中,我们首先描述了Suphx的决策流程,然后介绍了Suphx中使用到的网络结构和特征。
| Model | Functionality |
|---|---|
| Discard model | Decide which tile to discard in normal situations |
| Riichi model | Decide whether to declare Riichi |
| Chow model | Decide whether/what to make a Chow |
| Pong model | Decide whether to make a Pong |
| Kong model | Decide whether to make a Kong |
表1:Suphx中的五种模型
2.1 决策流程
由于麻将的规则复杂,Suphx学习了五种模型来处理不同的情况:弃牌模型、立直模型、吃牌模型、碰牌模型和杠牌模型,如表1所总结。
除了这五个学习到的模型,Suphx还采用另一个基于规则的获胜模型来决定是否宣示一手赢得该局。它基本上检查是否能从其他玩家丢弃的牌或从墙上摸到的牌组成一手赢牌,然后根据以下简单的规则做出决定:
● 如果不是游戏的最后一轮,宣示并赢得该局;
● 如果是游戏的最后一轮,
-
如果在宣示一手赢牌后整场比赛的累计轮次得分是四名玩家中最低的,则不宣示;
-
否则,宣示并赢得该局。
麻将玩家需要采取行动的情况有两种,我们的AI Suphx也是如此(见图1):
● 吃牌情况:Suphx从墙上摸一张牌。如果其私人牌可以与摸到的牌组成赢牌,则由赢牌模型决定是否宣示获胜。如果是,则宣示并且该局结束。否则,
- 杠牌步骤:如果私人牌可以与摸到的牌组成闭杠或暗杠,则由杠牌模型决定是否进行闭杠或暗杠。如果不是,则进入立直步骤;否则,有两个子情况:
(a) 如果是闭杠,则完成闭杠并回到吃牌情况。
(b) 如果是加杠,其他玩家可以使用这个加杠牌赢得这一轮。如果其他某个玩家赢了,则本轮结束;否则,完成加杠后回到摸牌状态。
-
立直步骤:如果手牌加上摸到的牌可以立直,立直模型决定是否宣布立直。如果不能,进入弃牌步骤;如果能,宣布立直然后进入弃牌步骤。
-
弃牌步骤:弃牌模型选择一张牌丢弃。之后轮到其他玩家采取行动或者在没有壁牌的情况下本轮结束。
● 其他人弃牌情况:其他玩家丢弃一张牌。如果Suphx可以用这张牌组成赢牌,赢牌模型决定是否宣布赢牌。如果是,宣布赢牌并且本轮结束。如果不是,检查是否可以用丢弃的牌组成吃、碰或杠。如果不能,轮到其他玩家采取行动;否则,吃、碰或杠模型决定采取什么行动:
-
如果三个模型都没有建议任何行动,则轮到其他玩家采取行动或者在没有壁牌的情况下本轮结束。
-
如果有一个或多个建议的行动,Suphx提出这些模型中置信度得分最高的行动(由这些模型输出)。如果提议的行动没有被其他玩家更高优先级的行动打断,Suphx就进行该行动,然后根据第一种情况进入弃牌步骤。否则,提议的行动被中断,轮到其他玩家采取行动。
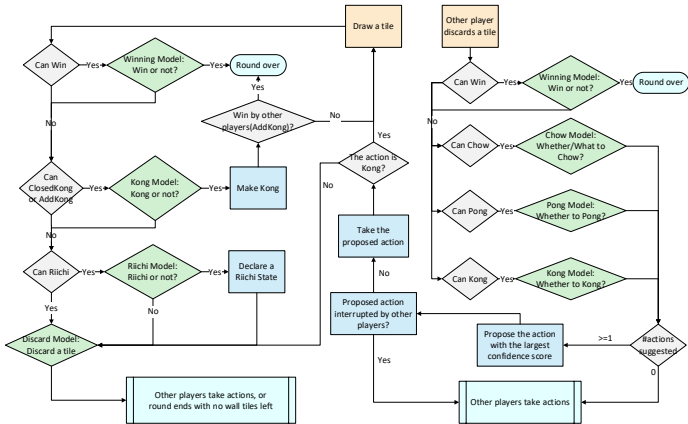
图1:Suphx的决策流程。
2.2 特征与模型结构
由于深度卷积神经网络(CNNs)展现了强大的表征能力,并已在下棋、将棋和围棋等游戏中得到验证,Suphx也采用深度CNN作为其策略的模型架构。
与围棋和象棋等棋类游戏不同,麻将玩家获得的信息(如图2所示)并不是自然以图像格式呈现的。我们精心设计了一套特征,将观察到的信息编码成能被CNNs处理的通道。
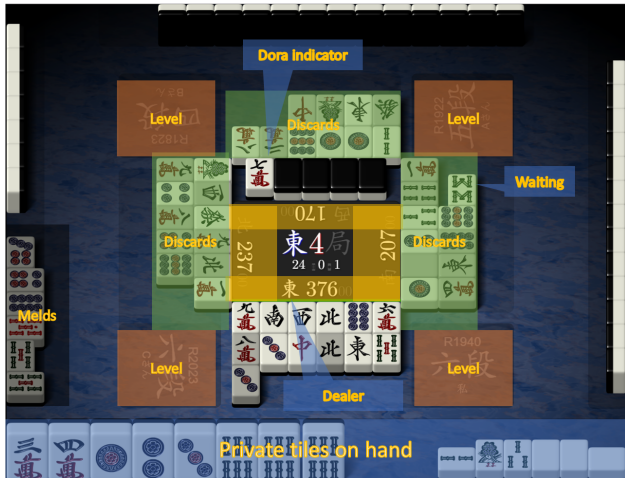
图2:状态示例。麻将的状态包含几种类型的信息:(1)包括私密牌、开局手牌和刻子的牌组,(2)丢弃的牌的序列,(3)整数特征,包括四位玩家的累计轮次得分以及活墙中剩余的牌数,(4)分类特征,包括轮次编号、庄家、重复庄家的计数器和立直赌注。
由于日本麻将中有34张独特的牌,我们使用多个34×1通道来表示一个状态。如图3所示,我们用四个通道来编码玩家的私密牌。开局手牌、刻子和丢弃的牌的序列被类似地编码到其他通道。分类特征被编码到多个通道中,每个通道要么全是0,要么全是1。整数特征被划分到桶中,每个桶使用一个全是0或全是1的通道进行编码。
除了直接可观察的信息外,我们还设计了一些外观-
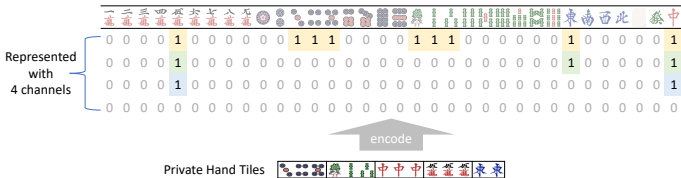
图3:私人牌块的编码。我们将玩家的私人牌块编码成四个通道。共有四行和34列,每行对应一个通道,每一列表示一种牌块。第n个通道的第m列表示手中是否有n块第m型的牌。
前瞻性特征,这些特征指示了如果我们从当前手牌中丢弃一块特定的牌,然后从墙上摸牌来替换一些其他的手牌,赢得一手牌的概率和轮次分数。在日本麻将中,一手14张牌的赢牌包含四个刻子和一对。有89种刻子和34种对子,这导致有极其众多不同的可能赢牌组合。此外,根据复杂的计分规则,不同的手牌会导致轮次得分不同。不可能枚举所有不同的丢弃/摸牌行为和赢牌的组合。因此,为了降低计算复杂度,我们在提取前瞻性特征时做了几项简化:(1)我们执行深度优先搜索来找到可能的赢牌。(2)我们忽略对手的行为,只考虑我们自己代理的摸牌和丢弃行为。通过这些简化,我们获得了100多个前瞻性特征,每个特征对应一个34维向量。例如,一个特征表示丢弃一块特定的牌是否可以通过用从墙上摸来的牌或由其他玩家丢弃的牌替换3张手牌,来赢得一手12000分轮次分数的赢牌。
在Suphx中,所有模型(i.即,弃牌/立直/吃/碰/杠模型使用类似的网络结构(图4和图5),除了输入层和输出层的维度不同(表2)。弃牌模型有34个输出神经元,对应于34个独特的牌,而立直/吃/碰/杠模型仅有两个输出神经元,对应于是否采取某个动作。除了状态信息和预见特征外,吃/碰/杠模型的输入还包含关于要形成何种牌的信息。请注意,我们的模型中没有池化层,因为通道的每一列都有其语义含义,池化会导致信息丢失。
| Discard | Riichi | Chow | Pong | Kong | |
|---|---|---|---|---|---|
| Input | 34×838 | 34×838 | 34×958 | 34×958 | 34×958 |
| Output | 34 | 2 | 2 | 2 | 2 |
表2:不同模型的输入/输出维度

图4:丢弃模型的结构

图5:立直、抽牌、碰牌和杠牌模型的结构
3 学习算法
Suphx的学习包含三个主要步骤。首先,我们通过监督学习,使用从天胡平台收集到的前十名人类玩家的(状态,动作)对,来训练Suphx的五个模型。其次,我们通过自我对弈强化学习(RL)来改进监督模型,以模型作为策略。我们采用流行的政策梯度算法(第3.1节),并引入全局奖励预测(第3.2节)和神谕引导(第3.3节)来应对麻将的独特挑战。第三,在在线对局期间,我们运用运行时策略适应(第3.4节)来利用当前轮次的新观察结果,以便表现得更好。
3.1 采用熵正则化的分布式强化学习
Suphx的训练基于分布式强化学习。特别是,我们采用策略梯度方法,并利用重要性采样来处理由于异步分布式训练导致的轨迹过时问题:
L(θ)=s,a∼πθ′E[πθ′(a∣s)πθ(a∣s)Aπθ(s,a)],
其中,θ′ 是(用于生成训练轨迹的)旧策略的参数,θ 是要更新的最新策略,而 Aπθ(s,a) 是在状态 s 下采取动作 a 的优势。
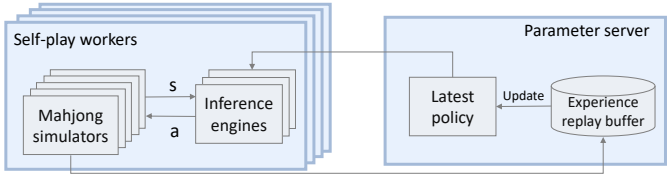
图6:Suphx中的分布式强化学习系统
关于策略πθ的状态s。
我们发现,强化学习训练对策略的熵敏感。如果熵过小,强化学习训练会迅速收敛,并且自玩不会显著提高策略;如果熵过大,强化学习训练变得不稳定,学到的策略方差较大。因此,在强化学习训练过程中,我们对策略的熵进行如下规范:
∇θJ(πθ)=s,a∼πθ′E[πθ′(s,a)πθ(s,a)∇θlogπθ(a∣s)Aπθ(s,a)]+α∇θH(πθ)(2)
其中,H(πθ) 是策略 πθ 的熵,α>0 是一个权衡系数。为了确保稳定的探索,如果近期我们的策略的熵小于/大于目标熵 Htarget,我们会动态调整 α 来增加/减少熵项。
α←α+β(Htarget−Hˉ(πθ)),(3)
其中,Hˉ(πθ) 是近期轨迹的经验熵,β>0 是一个小步长。
Suphx使用的分布式强化学习系统如图6所示。该系统由多个自玩工作线程组成,每个线程包含一组基于CPU的麻将模拟器和一组基于GPU的推理引擎来生成轨迹。策略 πθ 的更新与轨迹的生成是解耦的:使用一个参数服务器,基于重放缓冲区,利用多个GPU来更新策略。在训练期间,每个麻将模拟器随机初始化一局游戏,我们的强化学习代理作为一个玩家和其他三个对手进行对局。当四位玩家中的任何一位需要采取行动时,模拟器将当前状态(由一个特征向量表示)发送给一个GPU推理引擎,然后推理引擎返回一个动作给模拟器。GPU推理引擎定期从参数服务器获取最新的策略 πθ ,以确保自玩策略足够接近最新策略 πθ 。
3.2 全局奖励预测
在麻将中,每局游戏包含多轮,例如,天凤中的8-12轮。3 一局以给每位玩家发13张私密牌开始,接着玩家依次摸牌和弃牌,直到其中一位玩家完成一手胜利牌或者牌墙中没有牌了,然后每位玩家得到本轮分数。例如,形成胜利牌的玩家获得正分,其他玩家则得到零分或负分。当所有轮次结束时,每位玩家根据累积轮次得分的排名获得游戏奖励。
玩家在每轮结束时获得轮次得分,并在8-12轮后获得游戏奖励。然而,轮次得分和游戏奖励都不是强化学习(RL)训练的良好信号:
-
由于同一场游戏中的多轮共享相同的游戏奖励,使用游戏奖励作为反馈信号无法很好地区分表现好的轮次和表现差的轮次。因此,最好分别衡量每轮的表现。
-
虽然每轮都计算轮次得分,但它可能无法反映行动的好坏,特别是对于顶尖职业选手来说。例如,在游戏最后一两轮中,累积轮次得分大幅领先的排名第一的玩家通常会变得更加保守,并可能故意让排名第三或第四的玩家赢得这一轮,以便他/她能安全地保持总分排名第一。也就是说,负的轮次得分并不一定意味着策略差:有时它可能反映了某些战术,因此对应于相当好的策略。
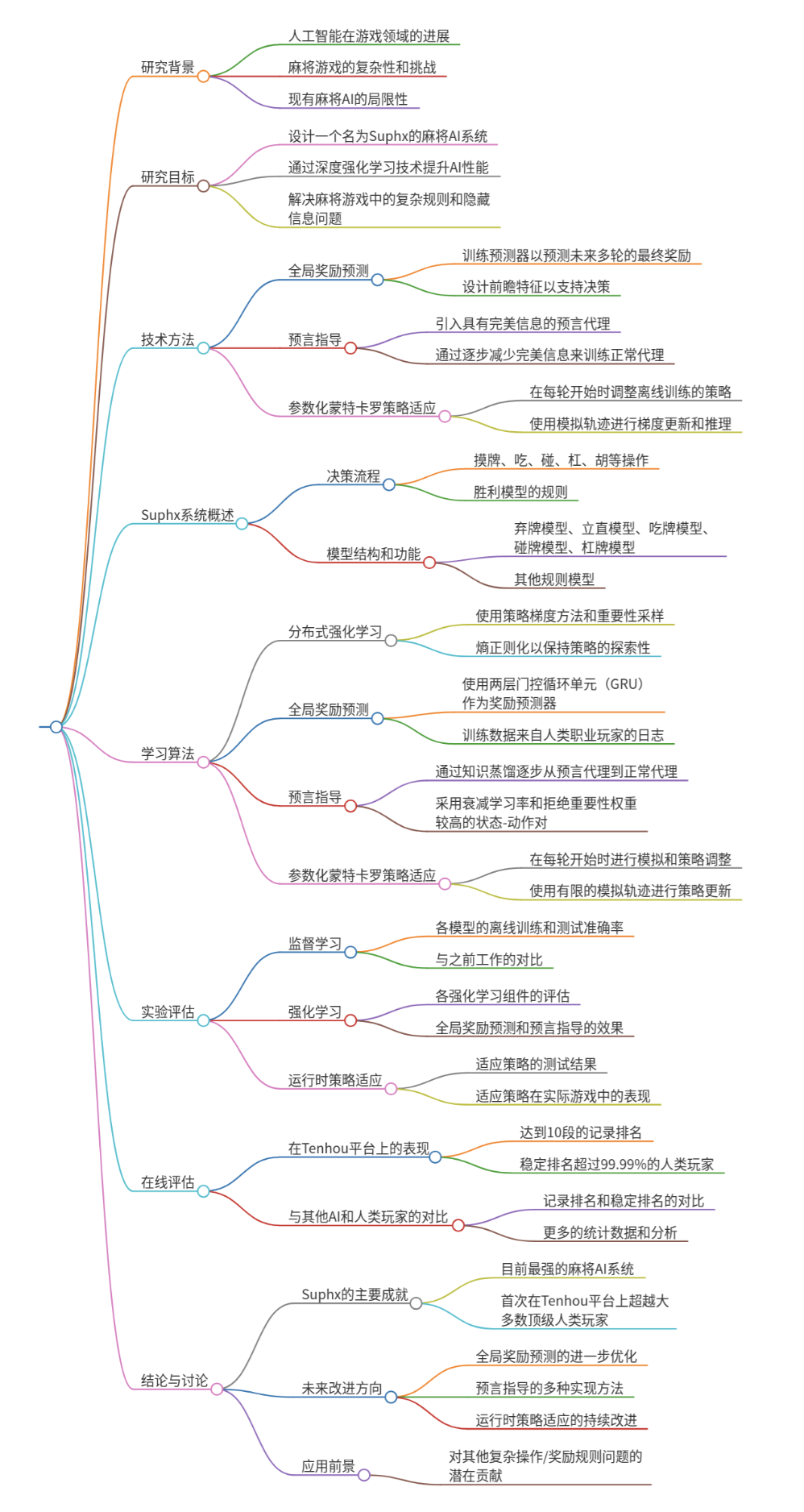
因此,为了提供有效的RL训练信号,我们需要适当地将最终游戏奖励(一个全局奖励)归属于游戏的每一轮。为此,我们引入了一个全局奖励预测器 Φ ,它根据当前轮次及此前所有轮次的信息来预测最终游戏奖励。在Suphx中,奖励预测器Φ是一个循环神经网络,更具体地,是一个由两层门控循环单元(GRU)后接两个全连接层组成的结构,如图7所示。
这个奖励预测器Φ的训练数据来源于天凤顶尖人类玩家的日志,通过最小化以下均方误差来训练Φ:
minN1∑i=1NKi1∑j=1Ki(Φ(xi1,⋯,xij)−Ri)2,
其中N表示训练数据中的游戏数量,Ri 表示第i场游戏的最终游戏奖励,Ki 表示第i场比赛的轮数,xik 表示第i场比赛中第k轮的包含特征向量。
图7:奖励预测器:GRU网络
本轮得分,当前累计轮次得分,庄家位置,重复庄家和立直注的计数。
当 Φ 训练有素时,对于一个K局的自玩游戏,我们使用 Φ(xk) - Φ(xk−1) 作为第k局强化学习的奖励。
3.3 神谕指导
麻将中有丰富的隐藏信息(例如,其他玩家的私密牌和墙牌)。如果没有获取这些隐藏信息的途径,就很难采取好的行动。这是麻将是一项困难游戏的一个根本原因。在这种情况下,尽管代理可以通过强化学习学会一种策略,但这种学习可能会非常缓慢。为了加快强化学习的训练速度,我们引入了一个神谕代理,它能看到一个状态的所有完美信息:(1)玩家的私密牌,(2)所有玩家已打出的(之前丢弃的)开放牌,(3)其他公共信息,如累计轮次得分和立直注,(4)其他三个玩家的私密牌,以及(5)墙中的牌。普通代理只能获得(1)(2)和(3),而(4)和(5)是额外的“完美”信息,只有神谕才能获得。
凭借(不公平的)完美信息获取能力,神谕代理在强化学习训练后将容易成为麻将大师。这里的挑战是如何利用神谕代理来指导和加速我们普通代理的训练。根据我们的研究,简单的知识蒸馏效果不佳:对于一个信息获取有限的普通智能体来说,要模仿一个训练有素的强大神谕智能体的行为是非常困难的,后者远超普通智能体的能力。因此,我们需要一种更聪明的方法来引导我们的普通智能体与神谕互动。
为此,可能会有不同的方法。在Suphx中,我们首先通过强化学习训练神谕智能体,使用所有特征,包括完美的特征。然后我们逐渐去除完美特征,使神谕智能体最终转变为普通智能体:
L(θ)=s,a∼πθ′E[πθ′(a∣[xn(s),δtxo(s)])πθ(a∣[xn(s),δtxo(s)])Aπθ([xn(s),δtxo(s)],a)],
其中,xn(s) 表示状态 s 的普通特征,xo(s) 表示状态 s 的额外完美特征,δt 是第 t 次迭代的丢弃矩阵,其元素是伯努利变量,有 P(δt(i,j)=1)=γt。我们逐渐将 γt 从 1 递减到 0。当 γt=0 时,所有完美特征都被丢弃,模型从神谕代理人转变为普通代理人。
在 γt 变为零后,我们继续对普通代理进行一定次数的训练。在持续训练期间,我们采用两个技巧。首先,我们将学习率减少到原来的十分之一。其次,如果某个状态-动作对的重要性权重超过预设的阈值,我们将其拒绝。根据我们的实验,如果没有这些技巧,持续训练是不稳定的,也无法带来进一步的改进。
3.4 参数化蒙特卡洛策略适应
当顶尖人类玩家的初始手牌(私密牌)发生变化时,他/她的策略将会非常不同。例如,如果他/她有一个好的初始手牌,他/她会采取积极的玩法以赢得更多;如果他/她的初始手牌不好,则会采取保守的玩法以损失更少。这与之前包括围棋和星际争霸在内的游戏非常不同。因此,我们相信如果我们能够在运行时适应离线训练的策略,我们就能够构建一个更强的麻将代理。
蒙特卡洛树搜索(MCTS)是在围棋等游戏中用于提升运行时性能的一种成熟技术。不幸的是,如前所述,麻将的打牌顺序是不固定的,很难构建一个常规的游戏树。因此,蒙特卡洛树搜索(MCTS)不能直接应用于麻将。在这项工作中,我们设计了一种新方法,名为参数化蒙特卡洛策略适应(pMCPA)。
当一轮开始且初始的私密手牌分发给我们的代理时,我们按以下步骤调整离线训练的策略以适应这个给定的初始手牌:
-
模拟:从不包括我们自己私密牌堆的瓷砖池中随机抽取三位对手的私密牌和墙牌,然后使用离线训练的策略来展开并完成整个轨迹。这样总共生成了K条轨迹。
-
调整:使用展开轨迹进行梯度更新,以微调离线策略。
-
推断:使用微调后的策略在本轮与其他玩家对战。
设h表示我们代理在一局的私密手牌,θo 表示离线训练的策略参数,θa 表示适应本局的新策略参数。那么我们有
θa=argmaxθ∑τ∼θoT(h)R(τ)p(τ;θo)p(τ;θ),(6)
其中,T(h) 是具有前缀 h 的轨迹集合,p(τ;θ) 是策略 θ 生成轨迹 τ 的概率。
根据我们的研究,模拟/轨迹的数量 K 不需要非常大,pMCPA 也不需要为这一轮中所有后续状态收集统计数据。由于 pMCPA 是一种参数方法,使用 K 次模拟更新的策略也可以导致对那些在模拟中未访问过的状态的更新估计。也就是说,这种运行时适应可以帮助我们将从有限模拟中获得的知识推广到未见过的状态。
请注意,策略适应是独立于每一轮进行的。也就是说,在我们当前轮次适应了代理的策略之后,对于下一轮,我们将再次从离线训练的策略开始。
4 离线评估
在本节中,我们通过离线实验报告了Suphx的每个技术组件的有效性。
4.1 监督学习
在Suphx中,五个模型首先分别通过监督学习进行训练。每个训练样本是从人类专业玩家那里收集的状态-动作对,状态作为输入,动作作为监督学习的标签。例如,在丢弃模型的训练中,样本的输入是一个状态的所有可观察信息(和前瞻特征),标签是人类玩家采取的动作,即在该状态下丢弃的牌。
训练数据大小和测试准确率在表3中给出。所有模型验证数据和测试数据的大小分别为10千(10 K)和5万(50 K)。由于丢弃模型解决的是一个34类分类问题,我们为其收集了更多的训练样本。从表中可以看出,我们获得了丢弃模型76.7%的准确率,Riichi模型85.7%的准确率,Chow模型95.0%的准确率,Pong模型91.9%的准确率,Kong模型94.0%的准确率。我们还列出了先前研究(6)所取得的准确率作为参考。5
| Model | Training Data Size | Test Accuracy | Previous Accuracy(6) |
|---|---|---|---|
| Discard model | 15M | 76.7% | 68.8% |
| Riichi model | 5M | 85.7% | |
| Chow model | 10M | 95.0% | 90.4% |
| Pong model | 10M | 91.9% | 88.2% |
| Kong model | 4M | 94.0% |
表3:监督学习的结果
4.2 强化学习
为了展示Suphx中每个强化学习(RL)组件的价值,我们训练了几个麻将代理:
● SL:监督学习代理。该代理(包括所有五个模型)以前一小节所述的监督方式进行训练。
● SL-weak:SL代理的一个训练不足的版本,在评估其他代理时作为对手模型。
● RL-basic:强化学习代理的基础版本。在RL-basic中,丢弃模型以SL丢弃模型初始化,然后通过策略梯度方法提升,以轮次分数作为奖励,并以熵正则化。立直、吃、碰、杠的模型与SL代理的相同。
● RL-1:通过全局奖励预测增强RL-basic的RL代理。奖励预测器通过监督学习训练,使用来自天凤的人类游戏日志。
● RL-2:通过神谕引导进一步增强RL-1的RL代理。请注意,在RL-1和RL-2中,我们也仅使用RL训练了丢弃模型,其余四个模型与SL代理的相同。
初始的私密牌具有很大的随机性,会极大地影响游戏的胜负。为了降低初始私密牌带来的方差,在离线评估期间,我们随机生成了100万局游戏。每个代理在这些游戏中与3个SL-weak代理对战。在这样的设置下,对一个代理的评估使用了20个特斯拉K80 GPU两天时间。对于评估指标,我们按照天凤(Tenhou)的规则计算了代理的稳定排名(见附录C)。为了降低稳定排名的方差,我们对每个代理,从一百万场比赛中随机抽取80万场进行1000次采样。
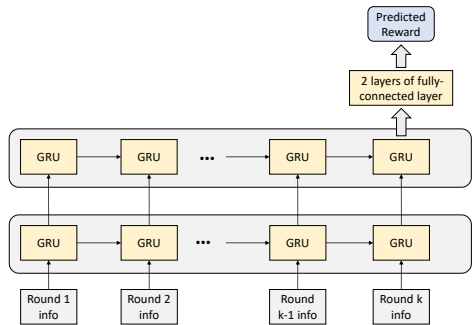
图8显示了在1000次采样中,这些代理的稳定排名的四分位数范围。请注意,为了公平比较,每个强化学习(RL)代理都使用了150万场比赛进行训练。每个代理的训练需要44个GPU(参数服务器使用4个泰坦XP,自我对弈工作器使用40个特斯拉K80)以及两天时间。如图所示,RL-基础在超越SL方面取得了良好的改进,RL-1的表现优于RL-基础,而RL-2在与RL-1的对战中带来了额外的收益。这些实验结果清楚地展示了强化学习价值,以及全局奖励预测和神谕引导的额外价值。
图8:超过一百万局游戏的稳定排名统计。该图显示了分布的三个四分位数以及极端值。“须子”延伸到位于下四分位数和上四分位数1.5个四分位距(IQR)之内的点,然后独立显示落在这个范围之外的观测值。
由于全局奖励预测器将游戏奖励分配给每一轮,训练有素的代理可以更好地最大化最终游戏奖励,而不是单轮得分。例如,在图9中,我们的代理(南方玩家)在游戏最后一轮拥有领先优势并且手气不错。根据四名玩家当前的累计轮次得分,赢得这一轮只能获得微小的奖励,而输掉这一轮则会导致重大惩罚。因此,我们的代理没有选择积极进攻以赢得这一轮,而是采取保守策略,选择最安全的牌来丢弃,并最终获得了第一名/排名;相比之下,基于强化学习的代理则丢弃另一张牌来赢得这一轮,这带来了输掉整场比赛第一名的大风险。
百分位数,或者在上四分位数和下四分位数之间,IQR= Q3- Q1。换句话说,IQR 是从第三四分位数减去第一四分位数得到的;这些四分位数可以在数据上的箱型图上清晰地看到。它是一种修剪估计量,定义为 25% 修剪范围,是一种常用的鲁棒尺度度量。
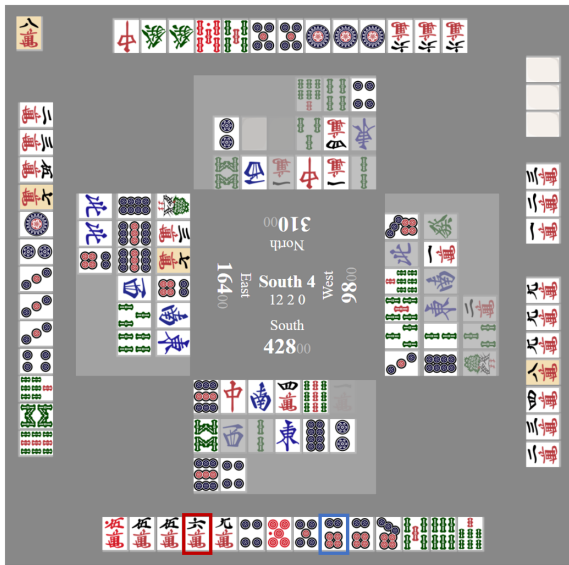
图9:通过全局奖励预测,当我们的代理(南方玩家)在一局游戏的最后一轮中累积轮次得分大幅领先时,即使其手牌很好且有一定概率赢得本轮,也会采取保守策略。基于强化学习的初级代理丢弃红色框定的牌以赢得本轮,但丢弃此牌有风险,因为同一块牌在本轮中没有被任何玩家丢弃。相比之下,RL-1和RL-2代理则处于防守模式,并丢弃蓝色框定的牌,这是一个安全牌,因为同一块牌刚刚被西方玩家丢弃。
4.3 运行时策略适应性的评估
除了测试对离线强化学习训练的改进外,我们还测试了运行时策略适应性。实验设置如下所述。
当一轮开始时,私人牌发给我们代理,
-
数据生成:我们固定代理的手牌,并模拟10万次轨迹。在每条轨迹中,其他三名玩家的手牌和墙牌都是随机生成的,我们使用四个代理的副本进行掷骰子并完成轨迹。
-
策略适应性:我们通过使用基本策略梯度方法,对离线训练的策略在
那10万次轨迹上进行微调和更新。
- 测试适应性策略:我们的代理使用更新后的策略与其他三名玩家在另一个1万次测试集上进行比赛,其中代理的私人牌仍然是固定的。由于我们代理的初始私人牌是固定的,因此在这个测试集上改编代理的表现可以告诉我们这种运行时策略适应是否真的使我们的代理适应并在当前的私人牌上表现得更好。
请注意,由于展开和在线学习,运行时策略适应是耗时的。因此,在当前阶段,我们仅在数百个初始回合中测试了这项技术。改编后的RL-2版本与其未改编版本的获胜率为66%,这证明了运行时策略适应的优势。
策略适应使我们的代理在当前私人手牌中表现得更好,特别是在游戏的最后1或2轮。图10展示了游戏最后一轮的一个例子。通过模拟,代理学会了知道虽然以漂亮的回合得分赢得这一轮很容易,但这不幸不足以避免以第四名结束游戏。因此,在适应后,代理打得更加积极,承担更多风险,并最终赢得了比赛,特别是在游戏的最后1或2轮。图10展示了以第四名结束游戏的一个例子。
5 在线评估
为了评估我们的麻将AI Suphx8的真实表现,我们让它在日本最流行的在线麻将平台Tenhou.net上进行游戏。Tenhou有两个主要房间,专家室和凤凰室。专家室对4段及以上的AI和人类玩家开放,而凤凰室仅对7段及以上的人类玩家开放。根据这一政策,Suphx只能在专家室中玩。
Suphx在专家房间中玩了超过5000局游戏,并且在记录排名上达到了10段,在稳定排名上达到了8.74段。它是天凤中第一个也是唯一一个在记录排名上达到10段的AI。
我们在表4中将Suphx与几位AI/人类玩家进行了对比:
Suphx在专家房间中玩了超过5000局游戏,并且是基于蒙特卡洛模拟和对局建模达到10段的。它不使用强化学习。
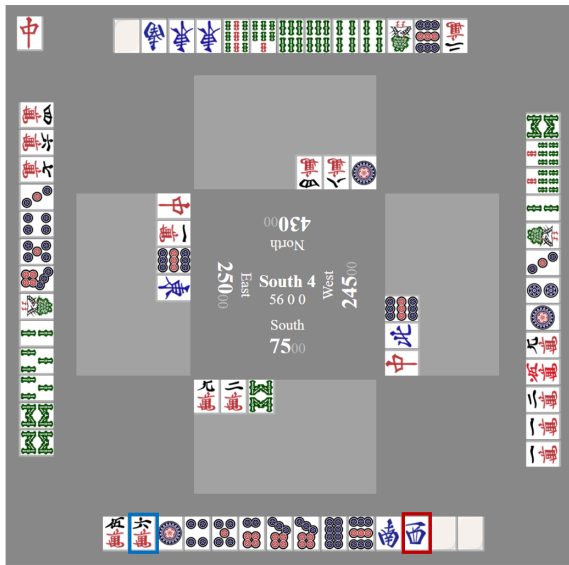
图10:在这个例子中,为了摆脱比赛的第四名,智能体需要在本轮赢得超过12000分的得分。通过模拟,智能体学会知道丢弃红色框定的牌可以轻松赢得本轮;然而,相应的获胜轮次分数会少于12000分。适应之后,智能体选择丢弃蓝色框定的牌,虽然这会导致获胜概率降低,但一旦获胜,获胜轮次分数将超过12000分。通过这样做,它承担了风险,并成功摆脱第四名。
● NAGA11:这是由多玩媒体村基于深度卷积神经网络设计的麻将AI。它也不使用强化学习。
● 我们还将Suphx与达到10段的顶尖人类玩家进行比较,就记录排名而言。公平地说,我们只比较他们在达到10段后在专家房的棋局。由于这些顶尖人类玩家在达到10段后大部分时间都在凤凰房(部分原因是其更为友好的计分规则),并且偶尔在达到10段后在专家房进行比赛,我们几乎无法计算出他们每个人的可靠稳定排名。因此,我们将他们视为一个宏观玩家来进行统计上合理的比较。
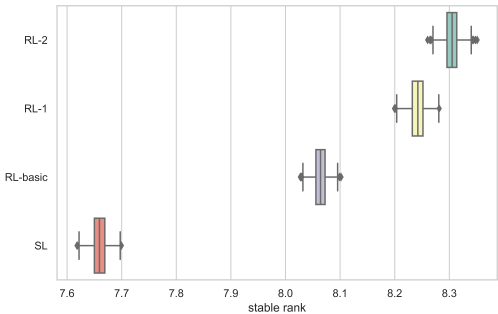
我们可以看到,就稳定排名而言,Suphx比Suphx之前的两位最佳麻将AI——Bakuuchi和NAGA——高出大约2段。尽管这些顶尖人类玩家与Suphx达到了相同的记录排名(10段),但在稳定排名方面,他们不如Suphx强大。图11绘制了当前活跃用户在天凤中的记录排名13的分布情况,显示Suphx的天凤排名超过99.99%的人类玩家。
| #Game | record rank | Stable Rank | |
|---|---|---|---|
| Bakuuchi | 30,516 | 9 dan | 6.59 |
| NAGA | 9,649 | 8 dan | 6.64 |
| Top human | 8,031 | 10 dan | 7.46 |
| Suphx | 5,760 | 10 dan | 8.74 |
表4:与其他人工智能和顶尖人类玩家的比较。
图11:天凤游戏中人类玩家记录段位的分布。每个条形表示天凤中达到某一水平的人类玩家数量。
如附录B所述,记录段位有时无法反映玩家的真实水平:例如,天凤历史上有多达100多位记录段位为10段的玩家,但他们的真实水平可能大相径庭。稳定段位(按其定义)比记录段位更为稳定且粒度更细;然而,当玩家在天凤中未进行足够数量的游戏时,其波动也可能很大。因此,为了进行更有信息和可靠的比较,我们采取如下步骤。对于每个AI/人类玩家,我们从其在专家房间的对局中随机抽取K局游戏,并使用这些K局游戏计算稳定段位。我们进行N次这样的抽样,并在图12中展示每位玩家对应的N个稳定段位的统计数据。如图所示,Suphx大幅领先其他两个AI以及顶尖人类职业玩家的平均表现。
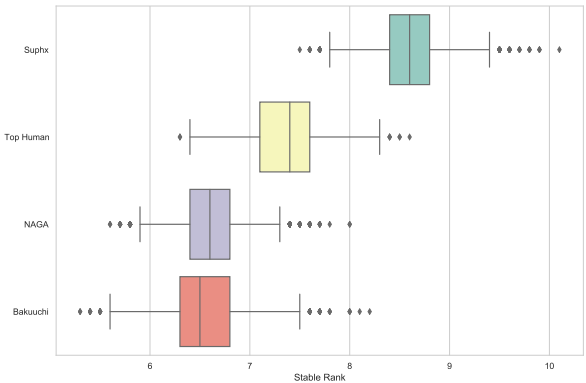
图12:当K=2000和N=5000时稳定段位的统计数据。
我们在表5中进一步展示了这些AI/人类玩家的更多统计数据。从表中我们得到了一些有趣的观察结果:
● Suphx在防守方面非常强大,且入局率非常低。这一点得到了顶尖人类玩家对Suphx的评论的证实。14
● Suphx的第四名段位率非常低,根据其计分规则,这是获得天凤高稳定段位的关键。
Suphx已经发展出了自己独特的玩法风格,这被顶尖人类玩家所认可。例如,Suphx非常擅长保留安全牌,更喜欢……
| 1st | 2nd | 3rd | 4th | Win | Deal-in | |
|---|---|---|---|---|---|---|
| Rank | Rank | Rank | Rank | Rate | Rate | |
| Bakuuchi | 28.0% | 26.2% | 23.2% | 22.4% | 23.07% | 12.16% |
| NAGA | 25.6% | 27.2% | 25.9% | 21.1% | 22.69% | 11.42% |
| Top human | 28.0% | 26.8% | 24.7% | 20.5% | ||
| Suphx | 29.3% | 27.5% | 24.4% | 18.7% | 22.83% | 10.06% |
表5:更多统计数据:排名分布及和牌/吃、碰率
半顺子15等获胜手。图13示例了Suphx保留安全牌以平衡未来攻防16。
6 结论与讨论
Suphx是目前最强的麻将AI系统,也是第一个在Tenhou.net(日本麻将的著名在线平台)上超越大多数顶尖人类玩家的麻将AI。由于麻将的复杂性和独特挑战,我们认为尽管Suphx表现非常好,但仍有很大的提升空间。
● 我们在Suphx中引入了全局奖励预测。在当前系统中,奖励预测器以有限的信息作为输入。显然,更多信息将带来更好的奖励信号。例如,如果因为起始手牌的良好运气使得某轮非常容易获胜,那么赢得这一轮并不反映我们策略的优越性,不应过多奖励;相反,赢得困难的一轮应得到更多奖励。也就是说,在设计奖励信号时应考虑游戏难度。我们正在研究如何利用完整信息(例如,通过比较不同玩家的私密起始手牌)来衡量一轮/游戏的难度,然后增强奖励预测器。
● 我们引入了神谕引导的概念,并通过完美的特征丢弃,逐渐过渡从神谕代理到普通代理来实例化这个概念。除此之外,还可以采用其他方法来利用完美信息。例如,我们可以同时训练一个预言代理和一个普通代理,让预言代理将其知识传递给普通代理,同时限制这两个代理之间的距离。根据我们的初步实验,这种方法也表现得相当好。再者,我们可以考虑设计一个预言评论家,它提供更为有效的……

图13:Suphx在状态st保留一个安全牌,以平衡未来的攻防。尽管在状态st丢弃红色框定的牌是安全的(实际上这确实是大多数人类玩家会丢弃的牌),但Suphx还是将其留在手中;相反,它丢弃蓝色框定的牌,这可能会减缓形成赢手的过程。这样做可以在未来的状态中提供更多的灵活性,并能更好地平衡未来的攻防。考虑一个未来的状态st+k,此时另一个玩家宣布了一个我们代理没有预料到的立直。在这种情况下,Suphx可以丢弃在状态st保留的安全牌,并且不会破坏其试图形成的赢手。相比之下,如果Suphx在状态st丢弃了这个安全牌,那么在st+k时它就没有其他安全牌可以丢弃了,因此可能不得不破坏其手中的接近赢手的刻子或对子,从而降低获胜概率。
状态级即时反馈(而不是轮次级反馈)以加速基于完美信息的策略函数训练。
● 对于运行时策略适应,在当前Suphx系统中,我们在每轮开始时当私人牌被分发给我们的代理时进行了模拟。实际上我们也可以在玩家丢弃任何牌后进行模拟。也就是说,我们不仅可以使策略适应初始的手牌,而且随着游戏的进行,当越来越多的信息变得可见时,我们可以继续进行适应。通过这样做,我们应该能够进一步提升我们策略的性能。此外,由于我们逐步调整我们的策略,我们在每一步中不需要太多的采样和部署。换句话说,我们可以将策略适应的计算复杂度分摊到整个对局过程中。有了这个,甚至可以在计算资源可承受的情况下,在在线对局中应用策略适应。
Suphx 是一个不断学习和改进的代理。Suphx 在 Tenhou.net 上的今日成就只是一个开始。展望未来,我们将向 Suphx 引入更多新技术,并继续推动麻将人工智能和不完全信息博弈的前沿。
大多数现实世界问题,如金融市场预测和物流优化,与麻将而非围棋/国际象棋有相似的特点——复杂的操作/奖励规则、不完全信息等。我们相信我们在 Suphx 中为麻将设计的技巧,包括全局奖励预测、神谕指导和参数化蒙特卡洛策略适应,具有很大的潜力,可以为广泛的现实世界应用带来益处。
致谢
我们真诚地感谢 Tsunoda Shongo 和 Tenhou.net 提供专家级对局日志和实验在线平台。我们感谢 Tenhou.net 的玩家与 Suphx 对局。我们感谢 MoYuan 帮助我们收集人类职业玩家的统计数据。我们还要感谢我们的实习生郝正和纪晓红,以及我们的同事李亚涛、曹伟、马卫东和何迪对开发Suphx学习算法和训练系统的贡献。
参考文献
-
克里斯托弗·伯纳(Christopher Berner)、格雷格·布罗克曼(Greg Brockman)、布鲁克·陈(Brooke Chan)、维多利亚·张(Vicki Cheung)、普热梅斯瓦夫·德比亚克(Prze-myslaw Debiak)、克里斯蒂·丹尼森(Christy Dennison)、大卫·法里(David Farhi)、奎林·费舍尔(Quirin Fischer)、沙瑞克·哈什米(Shariq Hashme)、克里斯·赫塞(Chris Hesse)等人。利用大规模深度强化学习的Dota 2。arXiv预印本arXiv:1912.06680,2019年。
-
迈克尔·鲍林(Michael Bowling)、尼尔·伯奇(Neil Burch)、迈克尔·约翰森(Michael Johanson)和奥斯卡里·塔姆林(Oskari Tammelin)。“看牌限注德州扑克已解决”。《计算机协会通讯》,第60卷第11期:81-88页,2017年10月。
-
诺姆·布朗(Noam Brown)和图马斯·桑霍尔姆(Tuomas Sandholm)。超级AI在德州扑克中击败顶尖职业选手。《科学》,第359卷第6374期:418-424页,2018年1月。
-
诺姆·布朗(Noam Brown)和图马斯·桑霍尔姆(Tuomas Sandholm)。超级AI在多人扑克中的应用。《科学》,第365卷第6456期:885-890页,2019年。
-
欧洲麻将协会。日本麻将规则。http://mahjong-europe.org/portal/images/docs/Riichi-rules-2016-EN.pdf。
-
高世祺、大村史文、川原良宏、鹤冈义正。通过深度卷积神经网络对麻将游戏中不完美信息数据进行监督学习。日本信息处理学会,2018年。
-
高世祺、大村史文、川原良宏、鹤冈义正。通过深度卷积神经网络构建计算机麻将玩家。2019年6月。
-
栗原守、堀内邦人。构建具有抽象能力的人工智能玩家以应对麻将多人游戏中的马尔可夫决策过程的方法。2019年4月。
-
水谷伸行和鹤冈良。基于蒙特卡洛模拟和对局模型构建计算机麻将玩家。在2015年IEEE计算智能与游戏会议(CIG),第275-283页,2015年8月。
-
水谷伸行和鹤冈良。基于蒙特卡洛模拟和对局模型构建计算机麻将玩家。在2015年IEEE计算智能与游戏会议(CIG),第275-283页。IEEE,2015年。
-
马泰·莫拉维茨克、马丁·施密特、尼尔·伯奇、维利扬·利西、达斯汀·莫里尔、诺兰·巴德、特雷弗·戴维斯、凯文·沃、迈克尔·约翰森和迈克尔·鲍林。DeepStack:在德州扑克中实现专家级人工智能。科学,356(6337):508-513,2017年5月。
-
蒋荣、秦涛和安波。使用深度神经网络进行竞争性桥牌叫牌。在第18届国际自主代理和多代理系统会议上发表,第16-24页。国际自主代理和多代理系统基金会,2019年。
-
大卫·西尔弗、黄艾佳、克里斯·J·麦迪逊、亚瑟·古兹、洛朗·西弗雷、乔治·范登德德里什、朱利安·施特普维瑟、伊奥安尼斯·安东尼奥格鲁、维达·潘内谢尔瓦姆、马克·兰克托特、桑德尔·迪勒曼、多米尼克·格罗韦、约翰·南姆、纳尔·卡尔奇布伦纳、伊利亚·苏茨克弗、蒂莫西·利克里普、玛德琳·利奇、科雷·卡库古鲁、托尔·格赖珀和德米斯·哈萨比斯。使用深度神经网络和树搜索掌握围棋游戏。自然,529(7587):484-489,2016年1月。
14.大卫·西尔弗,黄阿佳,克里斯·J·麦迪逊,亚瑟·古兹,洛朗·西弗雷,乔治·范登德里施,尤利扬·施特普维瑟,伊奥安尼斯·安东尼奥格鲁,维达·潘内谢尔瓦姆,马克·兰克托特等。利用深度神经网络和树搜索掌握围棋游戏。《自然》,529(7587):484, 2016年。
-
大卫·西尔弗,托马斯·休伯特,尤利扬·施特普维瑟,伊奥安尼斯·安东尼奥格鲁,马修·赖,亚瑟·古兹,马克·兰克托特,洛朗·西弗雷,达尔尚·库马拉南,托尔·格雷佩尔,蒂莫西·利克里普,卡伦·西莫尼安,德米斯·哈萨比斯。一种通用强化学习算法,通过自我对弈掌握国际象棋、将棋和围棋。《科学》,362(6419):1140-1144, 2018年12月。
-
大卫·西尔弗,尤利扬·施特普维瑟,卡伦·西莫尼安,伊奥安尼斯·安东尼奥格鲁,黄阿佳,亚瑟·古兹,托马斯·休伯特,卢卡斯·贝克,马修·赖,阿德里安·博尔顿,虞田·陈,蒂莫西·利克里普,范辉,洛朗·西弗雷,乔治·范登德里施,托尔·格雷佩尔,德米斯·哈萨比斯。无需人类知识掌握围棋游戏。《自然》,550(7676):354-359, 2017年10月。
-
理查德·S·萨顿,大卫·A·麦卡勒斯特,萨特因德尔·P·辛格,伊什亚·曼苏尔。用于带函数逼近的强化学习的策略梯度方法。收录于《神经信息处理系统进展》,第1057-1063页,2000年。
-
杰拉尔德·特索罗。时序差分学习与TD-gammon。美国计算机协会通讯,《计算机协会通讯》杂志,38(3):58-68, 1995年。
-
新宫正明。天凤。https://tenhou.net/。访问日期:2019年6月17日。
-
万代媒体村。长野:深度学习麻将AI。https://dmv nico/ja/articles/mahjong_ai_naga/。访问日期:2019年6月29日。
21.奥里奥尔·维尼亚尔斯、伊戈尔·巴布什金、沃伊切赫·M·查恩凯蒂、迈克尔·马修、安德鲁·杜齐克、郑俊英、大卫·H·崔、理查德·鲍威尔、蒂莫·埃瓦尔德斯、佩特科·格奥尔吉耶夫等。使用多智能体强化学习在《星际争霸II》中达到大师级别。《自然》,575(7782):350-354,2019年。
附录A:麻将规则
麻将是一种基于牌的游戏,起源于中国数百年前,如今已在全球范围内流行,拥有数亿玩家。麻将本身在世界各地有许多不同的变体,不同地区的麻将无论在规则还是使用的牌上都有所不同。在这项工作中,我们专注于4人玩的日本麻将(立直麻将),因为日本麻将在日本有着非常专业的联赛,有17位顶尖选手,而且其规则(5)被明确定义且被广泛接受。由于日本麻将的玩法/计分规则非常复杂,而本项工作的重点不在于全面介绍这些规则,因此在这里我们进行了一些选择和简化,并对这些规则进行了简要介绍。更全面的介绍可以在麻将国际联盟规则(5)中找到。
日本麻将共有136张牌,由34种不同的牌组成,每种牌各有四张。这34张牌包括三种花色,分别是竹、字和点,每种从1到9,以及7张不同的荣誉牌。一局游戏包含多轮,当一位玩家失去所有分数,或者触发某些获胜条件时结束。
游戏中的每位玩家起始分数为25000分,其中一名玩家被指定为庄家。每局游戏开始时,所有牌会被洗混后排列成四堵墙,每堵墙有34张牌。52张牌分给4位玩家(每人13张作为个人手牌),14张牌形成死牌墙,除非玩家喊出“杠”并且抽到替换牌,否则这些牌永远不会被打出,剩余的70张牌形成活牌墙。四位玩家轮流抽牌和弃牌。第一个组成至少一个顺子的完整手牌的玩家赢得该轮,并根据奖励规则获得一定的分数:
● 完整手牌指的是一组4个刻子加上一对。刻子可以是碰(三张相同的牌)、杠(四张相同的牌)和吃(三张同花色的连续单张牌)。对子是由任意两张相同的牌组成,但不能与四个刻子混合。玩家可以从(1)自己从墙上抽到的牌中组成顺子/碰/杠,这种情况下这个刻子是隐藏的;或者(2)其他玩家丢弃的牌中组成顺子/碰/杠,这种情况下这个刻子是公开的。如果是用从墙上抽到的牌组成杠,则称为暗杠。玩家在杠之后需要从死牌墙额外抽取一张牌进行替换。一种特殊的情况叫做加杠,当一个玩家抽到的牌与自己已经公开的碰相匹配时,可以将这个公开的碰转换成一个杠。
● 一组面子或特殊条件被称为一个役。和牌是决定番数的最主要因素,不同番数的和牌值也不同。一个赢局的牌可能包含几种不同的和牌。
| Level | Base Ranking Pts. | 1st | 2nd | 3rd | 4th | Level Up Ranking Pts. | Level Down |
|---|---|---|---|---|---|---|---|
| Rookie | 0 | 0 | 20 | ||||
| 9Kyu | 0 | 0 | 20 | ||||
| 8Kyu | 0 | +20 @Normal Room | +10 @Normal Room | 0 | 20 | - | |
| 7Kyu | 0 | 0 | 20 | ||||
| 6Kyu | 0 | 0 | 40 | ||||
| 5Kyu | 0 | 0 | 60 | ||||
| 4Kyu | 0 | 0 | |||||
| 3Kyu | 0 | +40 | +10 @Advanced Room | 0 | 100 | ||
| 2Kyu | 0 | @Advanced Room | -15 | 100 | |||
| 1Kyu | 0 | -30 | 100 | - | |||
| 1Dan | 200 | +0 | -45 | 400 | Yes | ||
| 2Dan | 400 | +50 | +20 | -60 | 800 | Yes | |
| 3Dan | 600 | 1200 | Yes | ||||
| 4Dan | 800 | @Expert Room | @Expert Room | -90 | 1600 | Yes | |
| 5Dan | 1000 | -105 | 2000 | Yes | |||
| 6Dan | 1200 | -120 | 2400 | Yes | |||
| 7Dan | 1400 | +60 | +30 | -135 | 2800 | ||
| 8Dan | 1600 | -150 | 3200 | Yes | |||
| 9Dan | 1800 | @Phoenix Room | @Phoenix Room | -165 | 3600 | Yes | |
| 10Dan | 2000 | -180 | 4000 | Yes | |||
| Phoenix | H | Hmorable Title | - |
表6:天凤排名系统:不同等级及其要求
所有手牌中的役满和最终轮次分数将会累计。日本麻将的不同变种有不同的役满模式,常见的役满列表包含40种不同类型。此外,在摸牌前通过掷骰子确定的特殊牌—— dorahai(多选一),会作为额外点数作为奖励。
玩家与自己的私牌组成赢牌的最后一个牌可以来自(1)自己摸的墙牌,(2)其他玩家打出的弃牌。对于第一种情况,所有其他玩家都会输给赢家。对于第二种情况,打出该牌的玩家会输给赢家。
一个特殊的役满是,当玩家的手牌只差一张就能和出赢牌时,他可以宣布立直。一旦宣布立直,玩家只能从自己摸到的牌或其他玩家打出的弃牌中赢得赢牌,且不再允许更换手中的牌。19
玩家从一局游戏中获得的最终排名积分由他的等级和在游戏多轮中累积的轮次分数的排名决定,如表6所示。
附录B:天凤排名规则
天凤使用日本武道排名系统20,从新手(9级)开始,降到1级,然后是1段到10段。玩家在赢得/输掉排位赛时获得/失去排名积分。赚取或失去的分数取决于游戏结果(范围从1到4)、玩家的当前等级以及玩家所在的房间。天凤共有四种类型的房间:普通房、高级房、专家房和凤凰房。在这些房间中,输掉游戏的惩罚(即负的排名积分)是相同的,但赢得游戏的奖励(即正的排名积分)则不同。排名系统的设计是为了惩罚输掉游戏的等级高的玩家:高等级的玩家在第四名会失去比低等级玩家更多的分数,例如,十段玩家为-180分,而六段玩家为-120分。
当玩家进行游戏时,他/她会从游戏中赢得/失去一些排名积分,总排名积分会发生变化。如果总排名积分增加并达到下一级别的所需分数,他/她的等级会增加1级;如果总排名积分减少至0,他/她的等级会降低1级。当他/她的等级发生变化时,他/她将在新级别获得初始排名积分。不同房间和级别的排名积分详情列在表6中。因此,玩家的等级并不稳定,经常随时间变化。我们使用历史最高等级来表示玩家在天凤曾经达到的最高等级。
附录C:稳定等级
天凤使用稳定等级来评估玩家的长期平均表现。专家房的稳定等级按以下方式计算。21
设 n1 表示一个玩家获得最高累计轮次得分的比赛次数,n4 表示他/她获得最低累计轮次得分的比赛次数,n2 和 n3 分别表示获得第二/第三高累计轮次得分的比赛次数。那么该玩家在段位方面的稳定排名是
n45×n1+2×n2−2
由于游戏的累计回合分数不仅取决于玩家的技巧,还取决于四位玩家的私密牌和墙牌,因此由于隐藏信息的随机性,稳定的段位可能会有很大的波动。此外,在玩天凤时,对手由天凤系统随机分配,这引入了额外的随机性。因此,对于天凤的玩家来说,通常假设至少需要几千场比赛才能获得一个相对可靠的稳定段位。


















 5165
5165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











