




 本文详细介绍了StableDiffusion中各种微调模型的发展历程,包括Checkpoint、Embedding、LoRA、Hypernetworks和LyCORIS,探讨了它们的原理、优势和应用场景,以及AestheticGradients的过时。
本文详细介绍了StableDiffusion中各种微调模型的发展历程,包括Checkpoint、Embedding、LoRA、Hypernetworks和LyCORIS,探讨了它们的原理、优势和应用场景,以及AestheticGradients的过时。
Stable Diffusion高级教程 - 微调模型
前言
这节我们专门介绍 Stable Diffusion 里面各个微调模型。
为什么会有这么多类型的模型?
如果你点开 C 站的过滤器,你会发现模型的类型很多:
除了类型为 Checkpoint 的主模型,以外还有非常多的模型,有些你可能听过有些也是第一次看到,当然,未来还会出现更多类型的这种微调模型。根据我的学习,先解释下为什么会有这么多类型的模型。
这么多模型是模型发展历史的产物。在一开始,Stable Diffusion 是从无到有训练大模型,成本很高。因为训练通用大模型非常烧钱,之前我看其他文章,GPT-3 训练一次的成本约为 140 万美元,对于一些更大的 LLM(大型语言模型),训练成本介于 200 万美元至 1200 万美元之间。除了花钱,也非常耗时间,需要一个专门团队维护。
虽然这种基础模型并没不好用,但是他们打下了很好地基础,之后 Stable Diffusion 所有的模型都是在这种模型基础上微调出来的。不过随着 Stable Diffusion 越来越流行,大模型生成的图越来越不满意不同用户的需求,所以就开始诞生各种调整技术的出现。
一开始是对大模型的参数的训练,这就诞生了在 C 站看到的各个 Checkpoint 类型的模型,这种 Checkpoint 主模型需要的 GPU、时间、人员相对于大模型来说已经非常经济了,但是,Checkpoint 只满足一(多)个类用户的需求,但是细分下去还是细节和准确度不够,也不够灵活,势必出现非常垂直的解决方案。
接着出现了 Embedding 模型,由于它只训练负责的文本理解的模块,体积很小,训练也没什么门槛,效果却不错,逐渐被用户接受。然后相继出现了兼顾效果、文件体积、训练时间、训练难度等方面的 Lora、Hypernetwork。就是这样新模型不断涌现,最近几个月最热门的是 Lora,而最近一个月 Lycoris 效果也非常好。
Textual Inversion 之前已经专门写过一篇,而 Controlnet 之后会专门写,所以这篇仅介绍美学梯度、Lora、Hypernetworks、LyCORIS 这几个模型。
美学梯度 (Aesthetic Gradients)
它的思路是在通过一张或者几张参考图生成一个美学模型,最终对提示词进行调整和加权。
原项目是:GitHub - vicgalle/stable-diffusion-aesthetic-gradients: Personalization for Stable Diffusion via Aesthetic Gradients 🎨,其中 aesthetic_embeddings 目录下有一些准备好的 Embedding。
如果你想要使用它,需要使用GitHub - AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients: Aesthetic gradients extension for web ui这个扩展,这样就可以在「Aesthetic imgs embedding」里面选择对应的 Embedding。
现在它已经是落后的模型方案了,效果相对于其他方案来说比较差,且大模型可能以及集成它的算法,现在已经没什么人用了。
LoRA
LoRA(全称 Low-Rank Adaptation of large language models)直译为大型语言模型的低阶自适应,通过矩阵分解的方式,微调少量参数,并加总在整体参数上,所以它现在主要用来控制很多特定场景的内容生成。
当然我们不需要理解它的算法,你可以简单的认为它是特定概念 (例如画风、动作、特定对象、角色等特征) 图片的训练集即可,他会引导 SD 生成符合训练结果的图片,而不会让 SD 自由发挥。它的模型大小普遍在几十到上百 M,它比较热门的主要原因我觉得是训练难度低且效果非常好。
通过例子看效果,还是用blindbox(大概是盲盒): https://civitai.com/models/25995/blindbox。对比下不用 LoRA 和用 LoRA 的区别:

Hypernetwork
Hypernetwork 是 NovelAI 软件开发员 Kurumuz 在 2021 年创造的一个单独的神经网络模型,它和 LoRA 很类似,它是让梯度作用于模型的扩散 (Diffusion) 过程。扩散过程中的每一步都通过一个额外的小网络来调整去噪过程的结果。这个模型主要用于画风。
通过例子看效果,用InCase style: https://civitai.com/models/5124/incase-style-hypernetwork。对于下不用Hypernetwork和用Hypernetwork的区别:

但是和 Textual Inversion 一样,由于其效果和训练难度的原因(需要设置网络结构、训练参数等),目前并没有成为主流选择。
LyCORIS
LyCORIS (Lora beYond Conventional methods) 是最近开始流行的一种新的模型,如其名字是一种超越传统方法的 Lora,但是要比 LoRA 能够微调的层级多,它的前身是 LoCon (LoRA for convolution layer)。
LoCon 和 LoHA (LoRA with Hadamard Product representation) 都是 LyCORIS 的模型算法,如果 C 站模型下载页面如果明确说是 LoCon 那就是 LoHA
现在 stable-diffusion-webui 还没有自带它,所以需要先安装扩展:GitHub - KohakuBlueleaf/a1111-sd-webui-lycoris: An extension for stable-diffusion-webui to load lycoris models.。 首先点「Extensions」,再点「Install from URL」把地址输入后点「Install」等待提示完成。
注意和其他扩展不同,安装不能点击「Apply and restart UI」不能生效,需要重启 webui 进程。
接着我们去站找个模型,就拿「Miniature world style 微缩世界风格」:https://civitai.com/models/28531/miniature-world-style
➜ wget https://civitai.com/api/download/models/34223 -O ~/workspace/stable-diffusion-webui/models/LyCORIS/miniatureV1.1c21.safetensors |
注意,LyCORIS 有独立的 Tab,没有和 Lora 混在一起,但它的用法和 LoRA 很像:
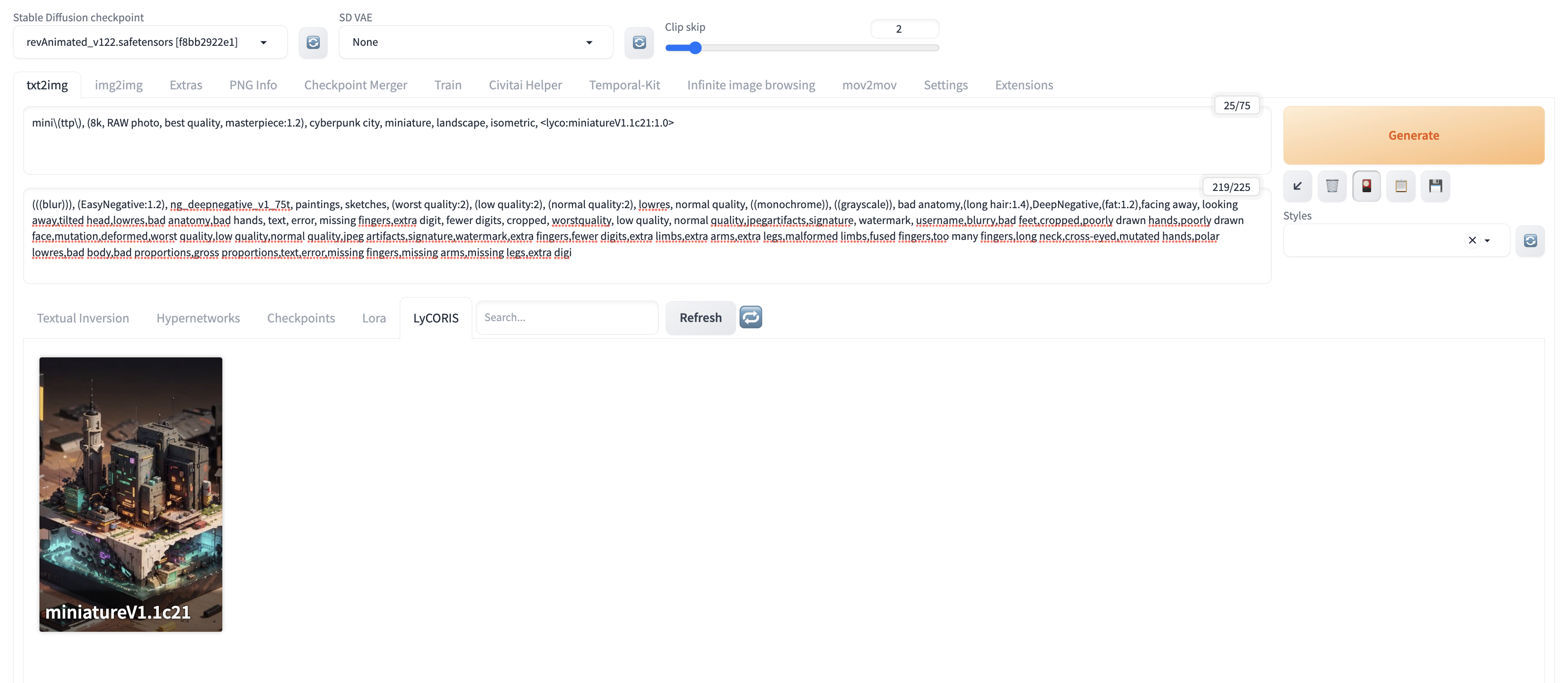
对比下用 LyCORIS 的区别:



















 2809
2809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











