







超越ASR+LLM+TTS,最强端到端语音对话模型GLM-4-Voice部署
原创 jasonkit 杰说新技术 2024年11月04日 06:00 广东
GLM-4-Voice是由智谱公司开发的一款端到端的情感语音模型。
GLM-4-Voice由三个部分组成,包括Tokenizer、Decoder和9B模型,其中Tokenizer负责将连续语音转换为离散token,Decoder将token转换回连续语音输出,而9B模型则基于GLM-4-9B进行预训练和对齐,理解和生成离散化的语音。
GLM-4-Voice能够模拟不同的情感和语调,如高兴、悲伤、生气、害怕等情绪,并用合适的情绪语气进行回复,这使得它在情感表达上比传统的TTS技术更加自然和细腻。
GLM-4-Voice支持中英文语音以及多种中国方言,尤其擅长北京话、重庆话和粤语。
GLM-4-Voice还支持用户随时打断语音输出,并输入新的指令来调整对话内容,这使得对话更加灵活和符合日常交流的习惯。
GLM-4-Voice可以应用于客服系统、虚拟助手、教育软件等多个场景,提供更为人性化的服务体验。
github项目地址:https://github.com/THUDM/GLM-4-Voice。
一、环境安装
1、python环境
建议安装python版本在3.10以上。
2、pip库安装
pip install torch==2.3.0+cu118 torchvision==0.18.0+cu118 torchaudio==2.3.0 --extra-index-url https://download.pytorch.org/whl/cu118pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3、glm-4-voice-9b模型下载:
git lfs installgit clone https://modelscope.cn/models/ZhipuAI/glm-4-voice-9b
4、glm-4-voice-tokenizer模型下载:
git lfs installgit clone https://modelscope.cn/models/ZhipuAI/glm-4-voice-tokenizer
5、glm-4-voice-decoder模型下载:
git lfs installgit clone https://modelscope.cn/models/ZhipuAI/glm-4-voice-decoder
二、功能测试
1、运行测试:
(1)python代码调用测试
import argparseimport jsonfrom fastapi import FastAPI, Requestfrom fastapi.responses import StreamingResponsefrom transformers import AutoModel, AutoTokenizerimport torchimport uvicornfrom threading import Threadfrom queue import Queueclass TokenStreamer:def __init__(self, skip_prompt: bool = False, timeout=None):self.skip_prompt = skip_promptself.token_queue = Queue()self.stop_signal = object()self.next_tokens_are_prompt = Trueself.timeout = timeoutdef put(self, value):if value.dim() > 1:value = value.squeeze(0)if self.skip_prompt and self.next_tokens_are_prompt:self.next_tokens_are_prompt = Falsereturnfor token in value.tolist():self.token_queue.put(token)def end(self):self.token_queue.put(self.stop_signal)def __iter__(self):return selfdef __next__(self):value = self.token_queue.get(timeout=self.timeout)if value is self.stop_signal:raise StopIterationreturn valueclass ModelWorker:def __init__(self, model_path, device='cuda'):self.device = deviceself.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(device).eval()@torch.inference_mode()def generate_stream(self, params):prompt = params["prompt"]temperature = float(params.get("temperature", 1.0))top_p = float(params.get("top_p", 1.0))max_new_tokens = int(params.get("max_new_tokens", 256))inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)streamer = TokenStreamer(skip_prompt=True)thread = Thread(target=self.model.generate, kwargs={'inputs': inputs,'max_new_tokens': max_new_tokens,'temperature': temperature,'top_p': top_p,'streamer': streamer})thread.start()for token_id in streamer:yield json.dumps({"token_id": token_id, "error_code": 0}) + "\n"def generate_stream_gate(self, params):try:yield from self.generate_stream(params)except Exception as e:print("Caught Unknown Error:", e)yield json.dumps({"text": "Server Error", "error_code": 1}) + "\n"app = FastAPI()@app.post("/generate_stream")async def generate_stream_endpoint(request: Request):params = await request.json()return StreamingResponse(worker.generate_stream_gate(params), media_type="application/json")if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--host", type=str, default="localhost")parser.add_argument("--port", type=int, default=10000)parser.add_argument("--model-path", type=str, default="glm-4-voice-9b")args = parser.parse_args()worker = ModelWorker(args.model_path, device='cuda')uvicorn.run(app, host=args.host, port=args.port, log_level="info")
(2)web端测试
import osimport sysimport jsonimport uuidimport tempfileimport requestsimport reimport torchimport torchaudioimport gradio as grfrom argparse import ArgumentParserfrom transformers import WhisperFeatureExtractor, AutoTokenizerfrom speech_tokenizer.modeling_whisper import WhisperVQEncoderfrom flow_inference import AudioDecoderfrom speech_tokenizer.utils import extract_speech_token# Pathssys.path.insert(0, "./cosyvoice")sys.path.insert(0, "./third_party/Matcha-TTS")# ConstantsAUDIO_TOKEN_PATTERN = re.compile(r"<\|audio_(\d+)\|>")# Initializationdevice = "cuda"audio_decoder, whisper_model, feature_extractor, glm_tokenizer = None, None, None, Nonedef initialize(args):"""Initialize models and load configurations."""global audio_decoder, feature_extractor, whisper_model, glm_tokenizerif audio_decoder is not None:return# Load tokenizerglm_tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)# Load audio decoderaudio_decoder = AudioDecoder(config_path=os.path.join(args.flow_path, "config.yaml"),flow_ckpt_path=os.path.join(args.flow_path, 'flow.pt'),hift_ckpt_path=os.path.join(args.flow_path, 'hift.pt'),device=device)# Load speech tokenizerwhisper_model = WhisperVQEncoder.from_pretrained(args.tokenizer_path).eval().to(device)feature_extractor = WhisperFeatureExtractor.from_pretrained(args.tokenizer_path)def clear_fn():"""Clear history and reset states."""return [], [], '', '', '', None, Nonedef generate_response(args, temperature, top_p, max_new_token, input_mode, audio_path, input_text, history, previous_input_tokens, previous_completion_tokens):"""Generate audio response based on user input (either text or audio)."""if input_mode == "audio":assert audio_path is not Noneaudio_tokens = extract_speech_token(whisper_model, feature_extractor, [audio_path])[0]audio_tokens = "<|begin_of_audio|>" + "".join(f"<|audio_{x}|>" for x in audio_tokens) + "<|end_of_audio|>"user_input, system_prompt = audio_tokens, "User will provide you with a speech instruction. Respond with interleaved text and audio tokens."else:assert input_text is not Noneuser_input, system_prompt = input_text, "User will provide you with a text instruction. Respond with interleaved text and audio tokens."history.append({"role": "user", "content": {"path": audio_path} if input_mode == "audio" else input_text})# Prepare inputinputs = previous_input_tokens.strip() + previous_completion_tokens.strip()if "<|system|>" not in inputs:inputs += f"<|system|>\n{system_prompt}"inputs += f"<|user|>\n{user_input}<|assistant|>streaming_transcription\n"# Request generationresponse = requests.post("http://localhost:10000/generate_stream",data=json.dumps({"prompt": inputs, "temperature": temperature, "top_p": top_p, "max_new_tokens": max_new_token}),stream=True)audio_offset = glm_tokenizer.convert_tokens_to_ids('<|audio_0|>')end_token_id = glm_tokenizer.convert_tokens_to_ids('<|user|>')text_tokens, audio_tokens, complete_tokens = [], [], []prompt_speech_feat, flow_prompt_speech_token = torch.zeros(1, 0, 80).to(device), torch.zeros(1, 0, dtype=torch.int64).to(device)prev_mel, is_finalize, tts_speechs, tts_mels = None, False, [], []block_size, this_uuid = 10, str(uuid.uuid4())with torch.no_grad():for chunk in response.iter_lines():token_id = json.loads(chunk)["token_id"]if token_id == end_token_id:is_finalize = Trueif len(audio_tokens) >= block_size or (is_finalize and audio_tokens):block_size = 20tts_token = torch.tensor(audio_tokens, device=device).unsqueeze(0)if prev_mel is not None:prompt_speech_feat = torch.cat(tts_mels, dim=-1).transpose(1, 2)tts_speech, tts_mel = audio_decoder.token2wav(tts_token, uuid=this_uuid, prompt_token=flow_prompt_speech_token.to(device),prompt_feat=prompt_speech_feat.to(device), finalize=is_finalize)prev_mel = tts_meltts_speechs.append(tts_speech.squeeze())tts_mels.append(tts_mel)yield history, inputs, '', '', (22050, tts_speech.squeeze().cpu().numpy()), Noneflow_prompt_speech_token = torch.cat((flow_prompt_speech_token, tts_token), dim=-1)audio_tokens = []if not is_finalize:complete_tokens.append(token_id)if token_id >= audio_offset:audio_tokens.append(token_id - audio_offset)else:text_tokens.append(token_id)tts_speech = torch.cat(tts_speechs, dim=-1).cpu()complete_text = glm_tokenizer.decode(complete_tokens, spaces_between_special_tokens=False)with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:torchaudio.save(f, tts_speech.unsqueeze(0), 22050, format="wav")history.append({"role": "assistant", "content": {"path": f.name, "type": "audio/wav"}})history.append({"role": "assistant", "content": glm_tokenizer.decode(text_tokens, ignore_special_tokens=False)})yield history, inputs, complete_text, '', None, (22050, tts_speech.numpy())def update_interface(input_mode):"""Update interface elements based on input mode."""return [gr.update(visible=input_mode == "audio"), gr.update(visible=input_mode == "text")]def main():parser = ArgumentParser()parser.add_argument("--host", type=str, default="0.0.0.0")parser.add_argument("--port", type=int, default="8888")parser.add_argument("--flow-path", type=str, default="glm-4-voice-decoder")parser.add_argument("--model-path", type=str, default="glm-4-voice-9b")parser.add_argument("--tokenizer-path", type=str, default="glm-4-voice-tokenizer")args = parser.parse_args()initialize(args)# Gradio Interfacewith gr.Blocks(title="GLM-4-Voice Demo", fill_height=True) as demo:temperature = gr.Number(label="Temperature", value=0.2)top_p = gr.Number(label="Top p", value=0.8)max_new_token = gr.Number(label="Max new tokens", value=2000)chatbot = gr.Chatbot(elem_id="chatbot", bubble_full_width=False, type="messages", scale=1)history_state = gr.State([])input_mode = gr.Radio(["audio", "text"], label="Input Mode", value="audio")audio = gr.Audio(label="Input audio", type='filepath', show_download_button=True, visible=True)text_input = gr.Textbox(label="Input text", placeholder="Enter your text here...", lines=2, visible=False)submit_btn = gr.Button("Submit")reset_btn = gr.Button("Clear")output_audio = gr.Audio(label="Play", streaming=True, autoplay=True, show_download_button=False)complete_audio = gr.Audio(label="Last Output Audio (If Any)", show_download_button=True)gr.Markdown("## Debug Info")input_tokens = gr.Textbox(label="Input Tokens", interactive=False)completion_tokens = gr.Textbox(label="Completion Tokens", interactive=False)detailed_error = gr.Textbox(label="Detailed Error", interactive=False)response = submit_btn.click(generate_response,inputs=[args, temperature, top_p, max_new_token, input_mode, audio, text_input, history_state, input_tokens, completion_tokens],outputs=[history_state, input_tokens, completion_tokens, detailed_error, output_audio, complete_audio])response.then(lambda s: s, [history_state], chatbot)reset_btn.click(clear_fn, outputs=[chatbot, history_state, input_tokens, completion_tokens, detailed_error, output_audio, complete_audio])input_mode.input(clear_fn, outputs=[chatbot, history_state, input_tokens, completion_tokens, detailed_error, output_audio, complete_audio]).then(update_interface, inputs=[input_mode], outputs=[audio, text_input])demo.launch(server_port=args.port, server_name=args.host)if __name__ == "__main__":main()
2、测试结果
(1)测试1
输入:
用轻柔的声音引导我放松
输出:
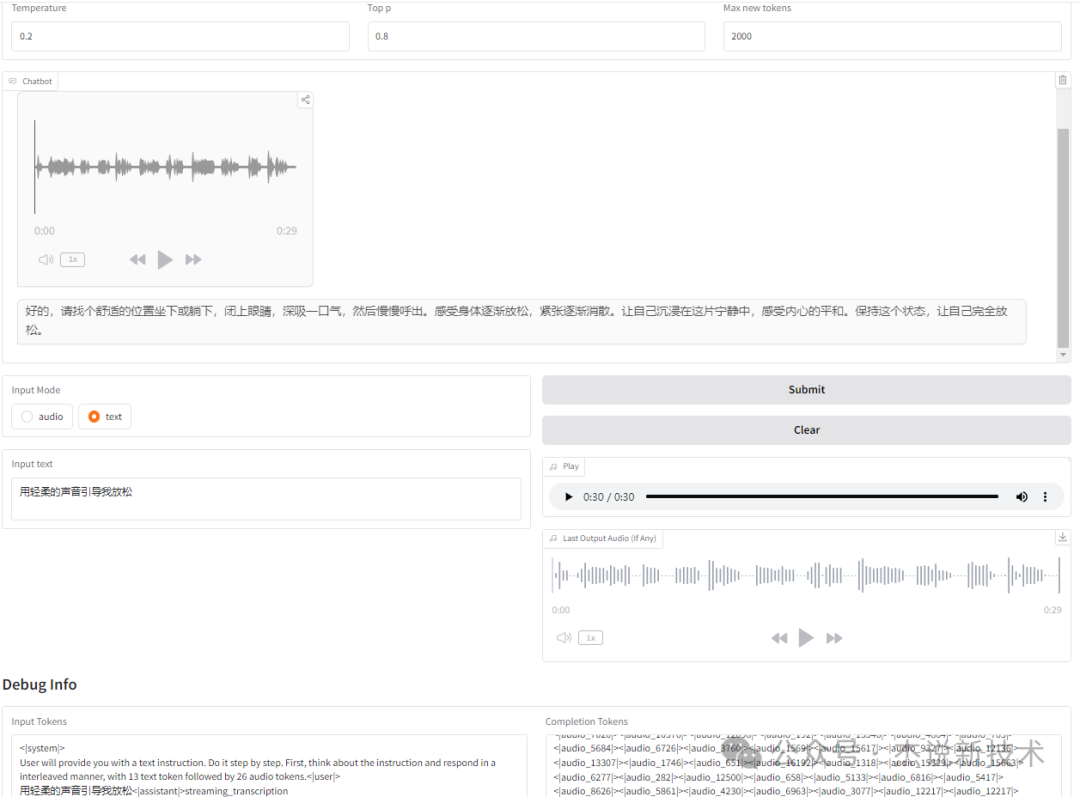
GLM-4-Voice1,杰说新技术00:0000:27/00:0000:28进度条 99%
(2)测试2
输入:
用激动的声音解说排球比赛
输出:
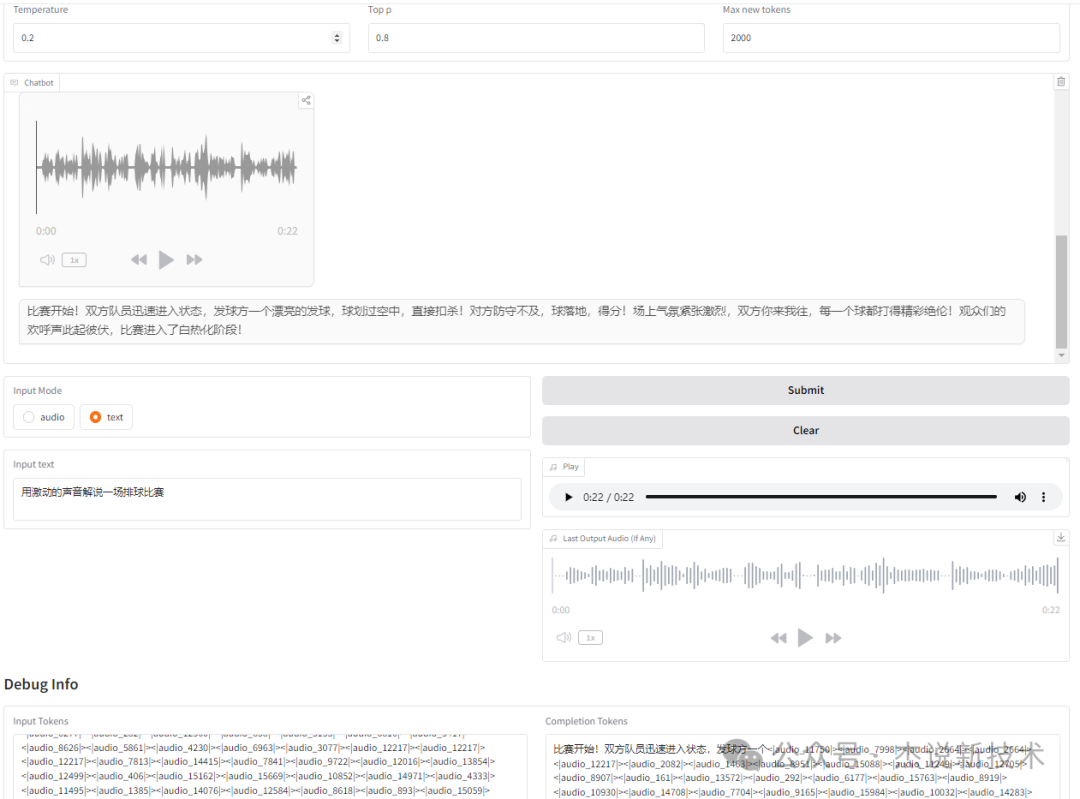
GLM-4-Voice2,杰说新技术,21秒
(3)测试3
输入:
用东北话讲一个冷笑话
输出:
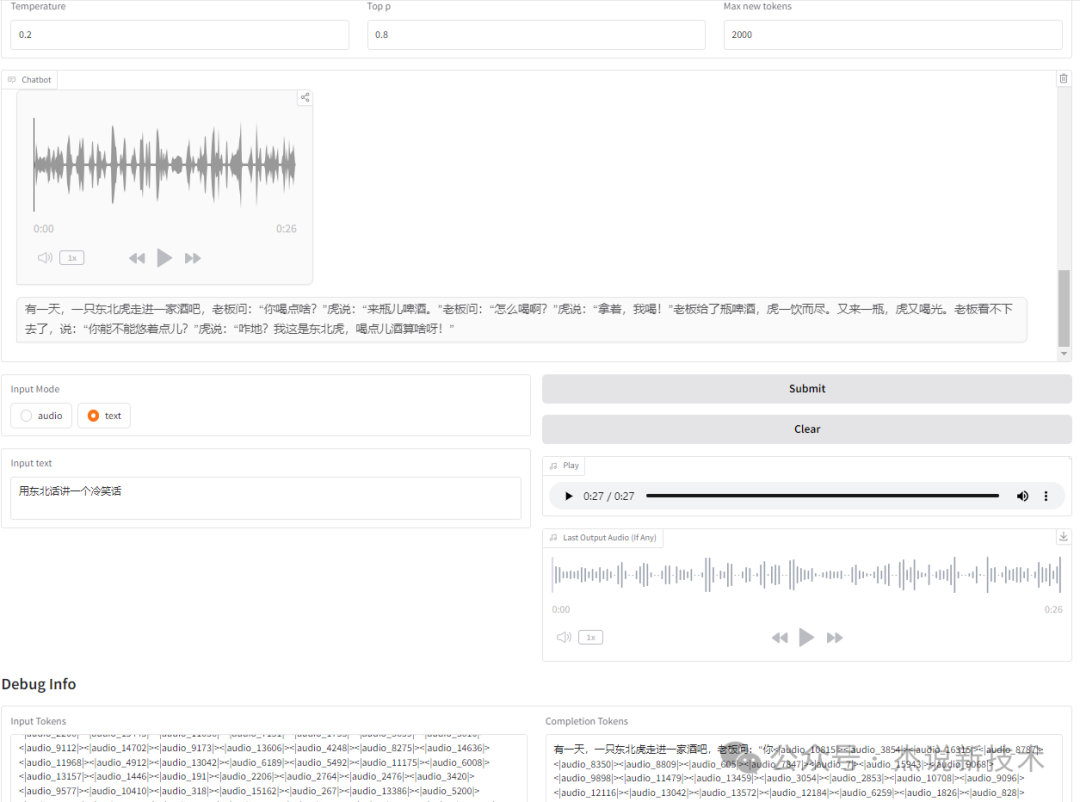
GLM-4-Voice3,杰说新技术,25秒
(4)测试4
输入:
用北京话念一下绕口令
输出:
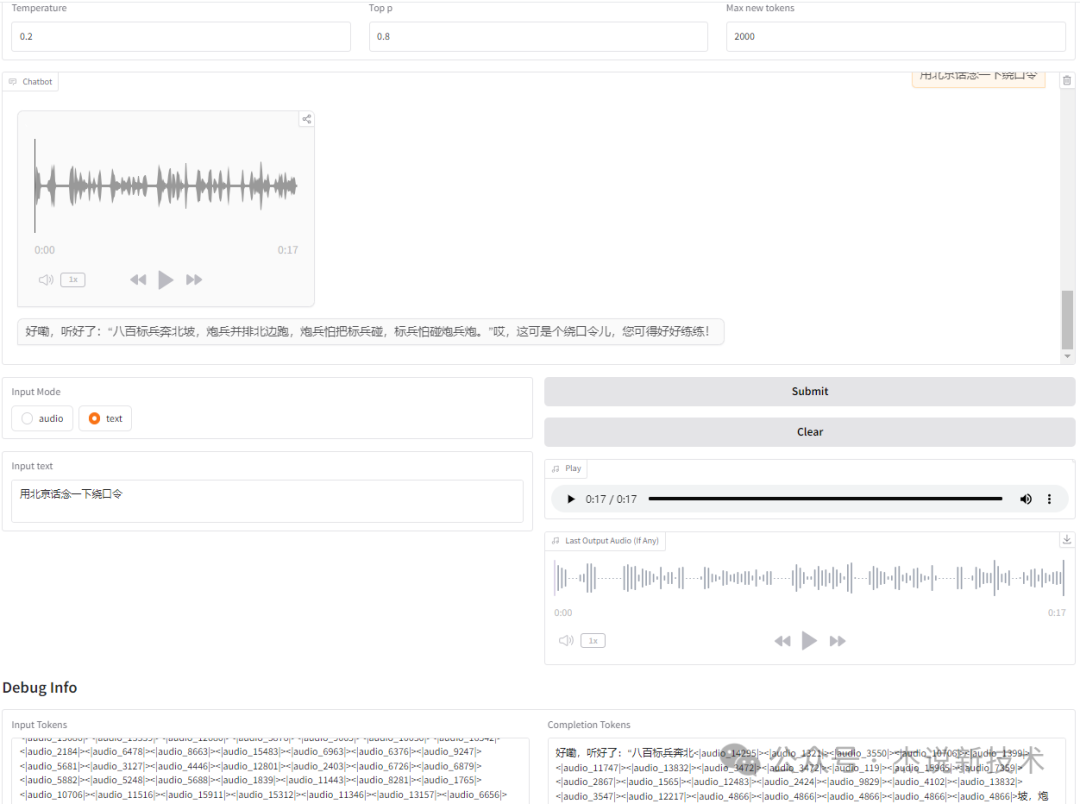
GLM-4-Voice4,杰说新技术,16秒
(5)测试5
输入:
用粤语讲一个儿童故事
输出:
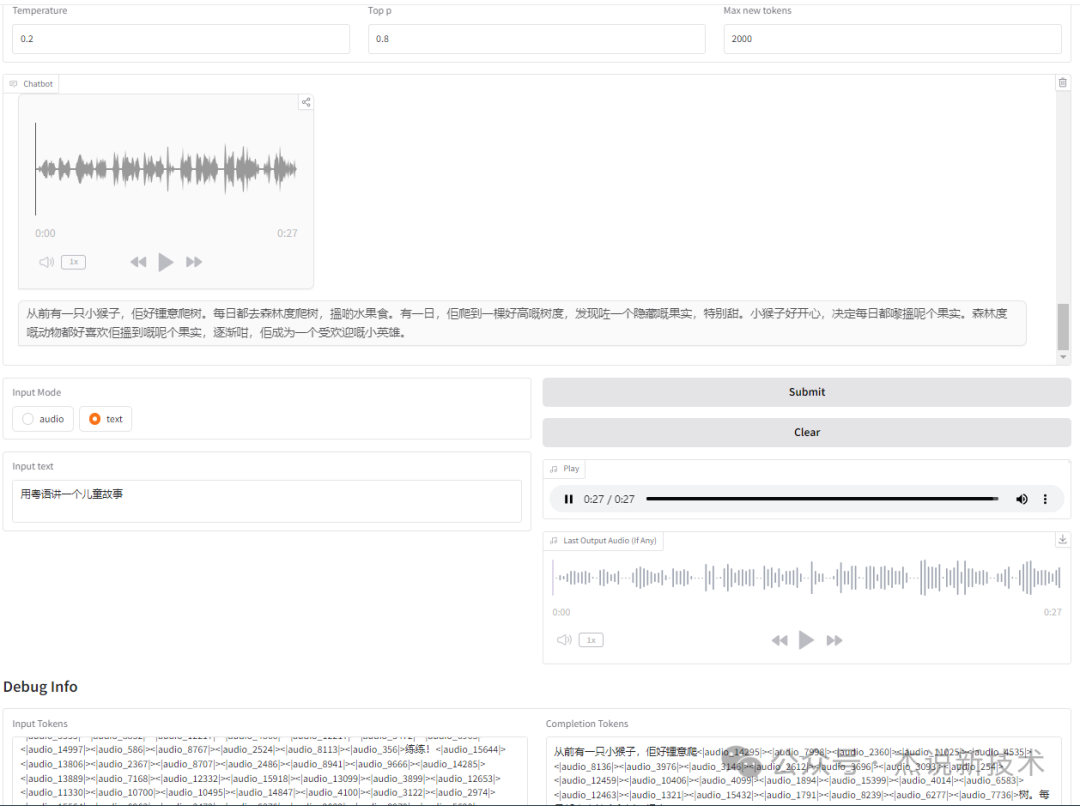
GLM-4-Voice5,杰说新技术,27秒
(6)测试6
输入:
用英语做一个自我介绍
输出:
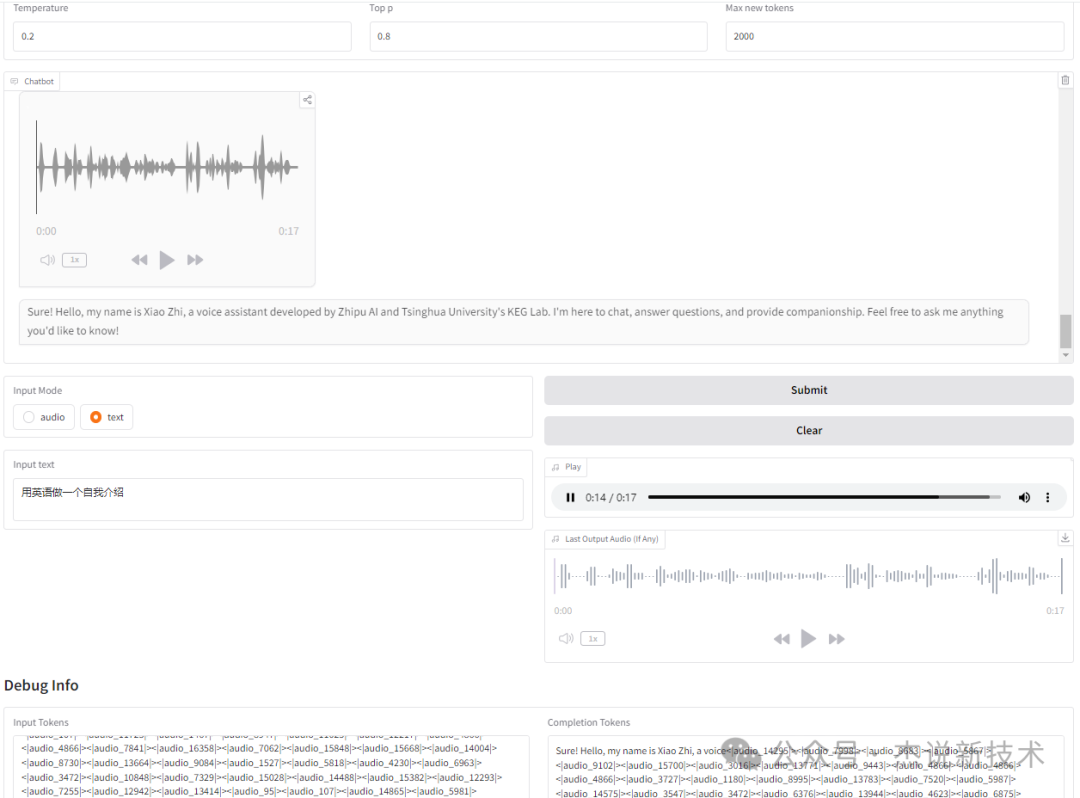
GLM-4-Voice6,杰说新技术16秒
三、总结
GLM-4-Voice是智谱AI推出的一款端到端情感语音模型,它具备直接理解和生成中英文语音的能力,支持实时语音对话,并能根据用户的指令灵活调整语音的情感、语调、语速和方言等特征。
GLM-4-Voice模型由GLM-4-Voice-Tokenizer、GLM-4-Voice-9B和GLM-4-Voice-Decoder三个部分组成,实现了音频的输入和输出的端到端建模。
GLM-4-Voice能够模拟不同的情感和语调,如高兴、悲伤、生气、害怕等,用合适的情绪语气进行回复,提升了语音交互的自然度和流畅性。
与传统的ASR+LLM+TTS的级联方案相比,GLM-4-Voice以音频token的形式直接建模语音,在一个模型里面同时完成语音的理解和生成,避免了信息损失,并解锁了更高的能力上限。
GLM-4-Voice的应用场景包括智能助手、客户服务、教育和学习、娱乐和媒体、新闻和播报等,未来可能会进一步扩展到更多领域。


















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











