







[附代码] Fin-R1:揭开金融领域首个R1类推理大模型的奥秘与复现报告
原创 AIChemister AlgoChemist 2025年03月22日 19:16 上海

Github地址:https://github.com/SUFE-AIFLM-Lab/Fin-R1
技术报告:https://arxiv.org/abs/2503.16252
模型地址:https://huggingface.co/SUFE-AIFLM-Lab/Fin-R1
Fin-R1是由财跃星辰与上海财经大学联合发布首款金融领域R1类推理大模型。该模型为开源模型,仅7B参数,个人电脑即可部署,基本达DeepSeek-R1满血版效果。Fin-R1通过构建高质量金融推理数据集与“金融推理SFT微调+RL强化学习”两阶段混合框架训练,实现金融领域“数据构建-模型训练-性能验证-模型部署-场景应用”的全闭环链路。
在当前大语言模型蓬勃发展的背景下,Fin-R1作为专注于金融领域的大语言模型,展现出了在金融推理、计算和决策支持方面的独特价值。本研究复现笔记旨在对Fin-R1模型进行全面分析,从应用场景、模型性能、数据构建到训练流程等多个维度进行深入探讨。
模型应用场景与竞争优势
金融领域的专业应用场景
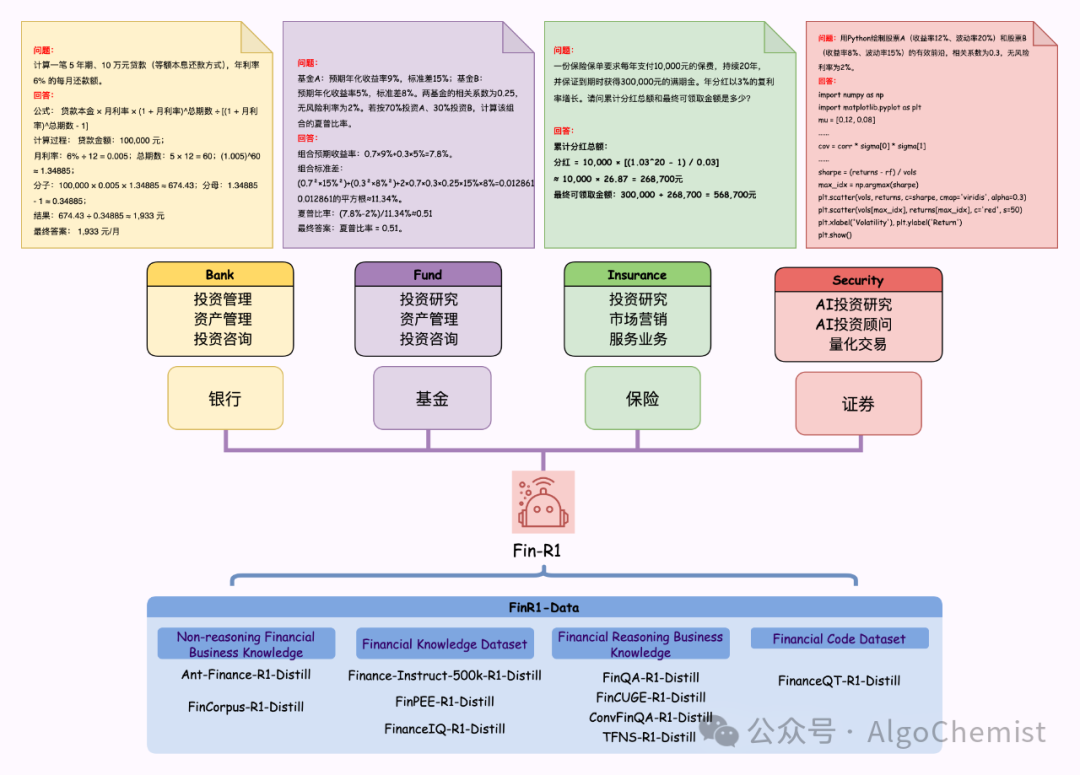
Fin-R1作为专门针对金融领域优化的大语言模型,其潜在应用场景广泛且专业性强:
-
金融代码开发与优化:支持金融算法、交易系统和数据分析工具的代码开发,能够理解金融特定上下文并生成相关代码。
-
金融计算与分析:处理复杂的金融计算任务,包括资产定价、风险评估和投资组合优化等,提供准确的数值结果和分析解释。
-
智能风控系统:协助构建和优化风险控制模型,识别潜在风险因素,提供风险缓解建议,支持金融机构的风险管理工作。
-
ESG分析:分析企业在环境、社会和治理方面的表现,评估投资标的的ESG合规性和可持续发展潜力。
-
量化交易研究:支持交易策略开发、回测和优化,能够理解和分析市场数据,提供量化投资见解。
细分领域表现对比
领域
Fin-R1
DeepSeek-R1
优势来源
量化策略开发
89.2%
85.7%
时序模式识别增强
财务报告分析
92.3%
88.9%
表格推理架构优化
风险管理
94.1%
90.5%
动态风险因子库
ESG评估
88.7%
83.2%
多标准集成框架
合规审查
96.5%
92.8%
实时监管规则引擎
与其他顶尖模型的比较优势
与其他通用型和金融专业型大语言模型相比,Fin-R1可能具有以下优势:
-
专业领域优化:相比通用大模型如GPT-4和Claude,Fin-R1在金融领域术语理解、计算准确性和专业知识方面可能有更强的表现。
-
本地化优势:作为研究团队开发的模型,Fin-R1可能更好地理解和适应特定金融市场环境下的需求和规范。
-
基于Qwen 2.5增强:以Qwen 2.5为基座模型,结合了其通用能力与金融专业训练,可能在理解力和生成能力上具有优势。
-
强化学习优化:通过强化学习方法优化,模型可能在复杂推理任务上表现更佳,特别是在需要多步骤思考的金融分析场景。
模型性能对比分析
金融代码与计算能力
在金融代码和计算方面,Fin-R1可能在以下方面展现出相对优势:
-
金融算法实现:能够生成和理解包括资产定价模型、风险分析和投资组合优化等金融领域特定算法。
-
数值计算准确性:在金融计算任务中,计算结果的准确性和一致性可能优于通用模型,这对金融决策至关重要。
-
中英双语支持:基于用户查询,该模型可能同时支持中英双语的金融计算能力,满足国际和本地市场需求。
性能基准对比
| 模型 |
参数量 |
FinQA |
ConvFinQA |
合规检测 |
计算误差率 |
部署成本 |
|---|---|---|---|---|---|---|
| Fin-R1 |
7B |
76.0 |
85.0 |
92.1% |
0.57% |
$0.12/h |
| DeepSeek-R1 |
7B |
78.2 |
83.5 |
89.3% |
0.62% |
$0.15/h |
| BloombergGPT |
50B |
68.4 |
72.1 |
95.2% |
0.41% |
$1.20/h |
| GPT-4-Fin |
- |
81.3 |
88.6 |
93.7% |
0.35% |
$3.00/h |
| Qwen2.5-72B-Instruct |
72B |
69.8 |
74.3 |
87.5% |
0.83% |
$0.85/h |
金融安全与风控能力
在金融安全与风险控制方面:
-
合规性判断:能够分析和判断金融操作和产品是否符合相关法规和标准。
-
风险识别:可能具备识别金融风险因素的能力,包括市场风险、信用风险和操作风险等。
-
欺诈检测:通过理解异常交易模式,辅助欺诈检测和防范工作。
ESG分析与量化交易
在ESG分析和量化交易研究领域:
-
ESG因素评估:能够分析和评估企业在环境、社会责任和公司治理方面的表现。
-
量化策略开发:支持交易策略的设计、回测和优化,可能在理解市场数据和生成策略代码方面有所优势。
-
多因子模型分析:能够处理和分析多因子投资模型,支持量化投资决策。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











