







从零开始的大模型强化学习框架verl解析
作者:Nasusu(已授权)
链接:https://zhuanlan.zhihu.com/p/30876678559
之前在职的时候给一些算法的同学讲解过verl的框架设计、实现细节以及超参配置,写这篇文章姑且作为离职修养这段时期的复健。
本文中提到的做法和思路可能随着时间推移有变化,或者是思想迪化,仅代表个人理解。如果有错漏的地方还请指出。
现在知乎上已有若干verl的使用相关文章了,覆盖了整体架构和快速的使用方法。本文将尝试从整体设计思路出发,致力于帮助不熟悉infra相关知识的算法同学快速理解整体框架,能自己上手魔改,并且知道各个超参的原理。
本文将尽量覆盖verl各模块的技术细节,但会排除SFT部分——当前社区已有充足的SFT框架方案可供选择。
本文中会掺杂一些算法同学可能会比较confusing的llm infra概念介绍,这里的讨论不会过于深入细节,诸如tp的横切/纵切,pp怎么消bubble,排出九文大钱讨论sequence parallel的4种写法,这些在知乎上都有非常好的文章讨论过了。这里的讨论仅旨在保持文章整体逻辑的完整性。
文中给了一些code example,应该会对部分概念和写法的理解有所帮助。
Get started without Ray
让我们不妨从sft出发,当你的上两级ld找到你,语重心长地说,小x啊,sft做不动,我们该rl了,组织已经研究决定,由你来踩这个坑,你环顾四周也实在没有谦虚的空间,接下了这个活。
此时你想的是什么,当然是从现有的sft的框架出发,看能不能魔改一下就能跑rl了。
众所周知,传统的RLHF使用的PPO,有actor/critic/reward/ref四个模块,按照如图所示的工作流迭代模型
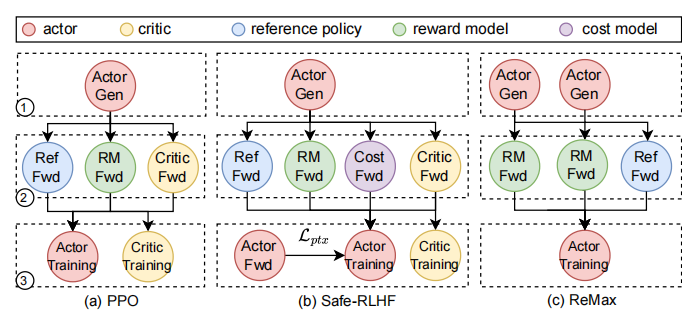
出自HybridFlow论文的rlhf流程图
这里参考HybridFlow论文中伪代码的写法,用batch指代过程中所有变量组成的dict。
for prompts in dataloader:
# Stage 1: response生成
batch = actor.generate_sequences(prompts)
# Stage 2: 训练数据准备
batch = critic.compute_values(batch)
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch)
batch = compute_advantages(batch)
# Stage 3: actor和critic训练
critic_metrics = critic.update_critic(batch)
actor_metrics = actor.update_actor(batch)
整体流程的这三部分相信大家已经很熟了。可以观察到参数迭代仅发生在stage3(模型训练),而前两个阶段均为模型推理过程。
那么很自然地,一个很简单的魔改思路就是,我们可以把它们各自init,再各自用deepspeed.initialize()/FSDP()包一下,然后重新写一遍训练流就好了。至于megatron,在我们这种跑起来就能交差的场景先不考虑。
这个思路很朴素,但确实是大部分早期rlhf训练的雏形,例如trl这个框架。无它,心智成本低,方便看懂,符合sft时的使用习惯。
但是问题也很明显,当模型和序列长度开始scale up之后,哪怕是仅仅是7b以上的量级,已经慢慢出现在单机8*80g机器上运行困难,可能爆显存的问题了。
平时碰到模型跑不起来的问题,常规的做法是把zero_stage开高,从zero1到zero2往往没什么问题,但是当我们试图从zero2到zero3的时候,往往速度一下会慢几个量级。(这往往是算法同学开始向框架求援的契机)
所以我们也就从这里开始,介绍我们后面会用到的infra知识。
parallelism &SPMD
parallelism
让我们从sft出发,先介绍一些parallelism的基础知识。
简单来说,目前parallelism解决的主要问题是,在多卡场景下如何做到:
-
提升多卡训练效率,最好2卡是1卡训练速度的两倍。
-
突破单卡显存限制以支持更大模型
标准训练流程包含三个核心环节:
-
模型forward,计算loss,保存中间激活值
-
模型backward,通过中间激活值计算gradient
-
模型update,把gradient传给optimizer,更新模型weight。
我们简单地把模型看成是Y=XW的矩阵乘法。将模型抽象为Y=XW的矩阵运算时,参数切分存在两种基本策略:
-
输入切分(X维度):对应Data Parallel/Sequence Parallel
-
权重切分(W维度):对应Tensor Parallel/Pipeline Parallel/Expert Parallel
在这里,切分X要比切分W简单的多。因为我们的模型输入往往是一个或多个规整的tensor,在batch维度可以很容易地做切分。大不了就把原始数据均分放到若干个文件夹里,每一块gpu从一个文件夹里读自己的数据就好了嘛。
而切分W就要头疼得多了,一旦出现诸如诸如卷积这种非典型矩阵计算,或者unet这种前后复杂的依赖关系,都要经过精心设计才行。
举个例子来说明这两种切分方式的区别,典中典的python爬虫任务,数据并行相当于将目标URL均分给各进程独立抓取,而模型并行则类似将使用多进程,将抓取流程分段执行。前者实现成本显著低于后者。
考虑整个训练流程,如果要和单卡保持一样的batch size(bs),我们需要让每张卡拿到自己的bs/n条数据。
在step1和step2都不需要做通信,也就是每张卡算自己loss和gradient即可,并不会有什么影响。
而在step3之前,我们需要把各卡的梯度放在一起求平均,保证得到正确的完整bs的梯度,而这个操作也就是all-reduce通信。
聪明的你已经想到了,这整个流程实际上就是分布式的gradient accumulation。
让我们把目光从X上离开,重新看W部分。在目前这种朴素的data parallel策略下,每块卡都拥有完整的model weight/gradient/optimizer,尺寸和单卡训练无异。
而deepspeed使用的zero stage即是对这部分显存占用的优化。具体细节在这里不表,好的文章已经很多了。从结论来说是
-
zero1中,每张卡只需要保留1/n的optimizer参数,通信量保持不变
-
zero2在zero1的基础上,每张卡只需要保留1/n的graident,通信量保持不变
-
zero3在zero2的基础上,每张卡只需要保留1/n的model weight,通信量变为1.5倍。
其中,zero1和zero2影响的分别是optimizer和graident,对应的是后两步,并没有影响forward部分
而Zero3模式下的训练流程演进为:
1. Forward阶段:all-gather获取完整参数→计算loss→释放参数→保存中间激活
2. Backward阶段:all-gather获取完整参数→计算梯度→释放参数
3. Update阶段:reduce-scatter获取梯度切片→优化器更新局部参数"
要注意的是,zero123本质仍然属于data parallel,不属于model parallel的范畴,尽管zero3看起来做了模型参数的切分,但实际上计算时会先做all gather得到完整的模型参数,计算时使用的也是完整的参数和切分后的输入。
对比tp/pp,它们从头到尾都只存模型参数的一部分,计算时使用的是切分后的参数和完整的输入。
-
对于dp,通信的是模型参数,也就是W和它对应的weight/optimizer
-
对于tp/pp,通信的是中间激活值,例如PP需要将上一个rank计算得到的中间结果传给下一个rank继续计算。
SPMD
在典型的多卡训练场景中(如使用torchrun或accelerate launch),通过nvidia-smi可观察到每块GPU对应独立进程,这种模式本质源于SPMD(Single Program Multiple Data)架构。
那么问题来了,是torchrun之类的启动脚本把它们“分配”到每张卡上的吗?实际上并不是。主流并行框架(DDP/DeepSpeed/Megatron)均基于SPMD范式:所有进程执行相同代码逻辑,通过环境变量差异自主确定行为模式,无需中心调度节点。
一段经典的PyTorch分布式训练初始化的代码
import torch
import os
print(os.environ['RANK'], os.environ['WORLD_SIZE'], os.environ['MASTER_ADDR'], os.environ['MASTER_PORT'])
torch.distributed.init_process_group(backend="nccl")
torch.cuda.set_device(torch.distributed.get_rank())
当我们使用torchrun启动这段代码后,会启动多个进程,每个进程有着不同的环境变量,标识它们属于哪一台机器和端口,是第几个进程和进程总数。
之后torch.distributed.init_process_group会根据这些环境变量构建通信组,这是一个阻塞操作,所有进程都要完成init_process_group后才会继续往下走。
最后set_device将当前进程绑定到一块gpu上,对于RANK=0的进程绑定在0号卡,RANK=1的进程绑定在1号卡,以此类推,不存在一个进程去调度安排它们的行为,它们运行的是完全相同的代码,只是用不同的rank区分开他们的行为。
以SPMD的思维模式去思考代码的写法,就像是思考在没有老师的班级里,学生们应该怎样才能过有序的校园生活。
-
学生们报道后首先拿到自己的学号(torchrun拿到每个进程的rank),确认自己是班级的多少号,坐在第几排第几列,这一排的同学和这一列的同学都有谁(init_process_group),然后找到自己对应的座位坐下(set_device);
-
奇数学号去一食堂,偶数学号去二食堂;
-
坐在第一排的同学负责收作业,坐在后面的同学把作业往前传;
-
即使是算班级各科平均分也不用老师来计算和公布,而是大家把自己的成绩写小纸条上传两圈,每个人就都知道班级平均分了。
以naive dp为例,会发现在训练过程中并不存在各个dp rank之间对齐参数的行为,这是因为只要保证各个rank初始化时的模型参数保持一致,之后每个step的gradient一致,从而optimizer对模型参数的更新是一致的,自然每个rank的模型就是一致的。
这也就引出了一个问题,SPMD的编程模式心智负担较重,相信写过Megatron的朋友都有感受,当逻辑复杂以后要考虑不同rank之间的不同行为和通信,以及避免corner case造成的stuck,一写一个不吱声,都是容易掉头发的环节。
总结来说,SPMD由于没有中心控制器,在运行时更为高效,完全由worker自驱。但由于在编程模式上需要各worker运行相同的程序,灵活性不如single-controller模式。
我们会在后续ray相关的部分做更详细的阐述。
接下来,我们通过介绍TP来进一步理解SPMD的编程模式。不论是使用Megatron进行训练,亦或是使用vLLM做推理,tp都是绕不过去的内容。这里不会介绍tp的更多使用细节,仅从一个简单的例子出发。
# 我们用torchrun启动这段代码
import torch
import torch.nn as nn
torch.distributed.init_process_group(backend="nccl")
torch.cuda.set_device(int(os.environ['RANK']))
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
# 构建一个从column维度切分的linear layer
class ColumnTPLayer(torch.nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.layer = nn.Linear(input_size, output_size // int(os.environ['WORLD_SIZE']), bias=False).to(device='cuda')
def forward(self, x):
ret = self.layer(x.to(device='cuda'))
output_tensor = torch.zeros(size=(int(os.environ['WORLD_SIZE']), ret.shape[0], ret.shape[1]), dtype=ret.dtype, device=ret.device)
torch.distributed.all_gather_into_tensor(output_tensor, ret, async_op=False)
output_tensor = torch.cat(output_tensor.unbind(dim=0), dim=-1)
return output_tensor
def load_weights(self, weight):
rank = int(os.environ['RANK'])
world_size = int(os.environ['WORLD_SIZE'])
dim_per_rank = weight.shape[0] // world_size
self.layer.weight.data.copy_(weight[rank*dim_per_rank: (rank+1)*dim_per_rank, :])
batch_size = 10
input_data = torch.randn(batch_size, 2)
# init一个PyTorch的linear layer,并让我们构建的layer和它保持参数一致。
full_layer = torch.nn.Linear(2, 6, bias=False)
weight = full_layer.state_dict()['weight']
tp_layer = ColumnTPLayer(2, 6)
tp_layer.load_weights(weight)
tp_ret = tp_layer(input_data).cpu()
fl_ret = full_layer(input_data).cpu()
torch.testing.assert_close(tp_ret, fl_ret)
这是一个2GPU的column tensor parallel的例子。在这段示例代码里,我们先做了分布式的初始化。然后构建了ColumnTPLayer,最后将它和完整的原始linear计算结果比较。
从这段代码里我们可以观察到TP和DP的差别
**Tensor Parallel (TP)**:
-
同组内各rank接收相同输入/输出
-
权重矩阵被切分存储(如列切分)
-
每个TP组构成完整模型副本(如TP=2时,2个GPU组成1个副本)
**Data Parallel (DP)**:
-
同组内各rank处理不同数据分片
-
保持完整权重复制
-
DP数量直接对应模型副本数(如DP=4即4个完整副本)
回想TP和zero3的区别,zero3在每次计算前会先gather完整的参数,计算后释放;而tp则是在计算前后对输入和计算结果做通信。
可以看出zero3的中间激活值是完整的,tp则是切分过的,在例子中仅是为了演示结果才立刻做了all_gather,实际上可以把两个linear层组合在一起,在入口和出口处才做通信,中间激活值的size减少为1/n。
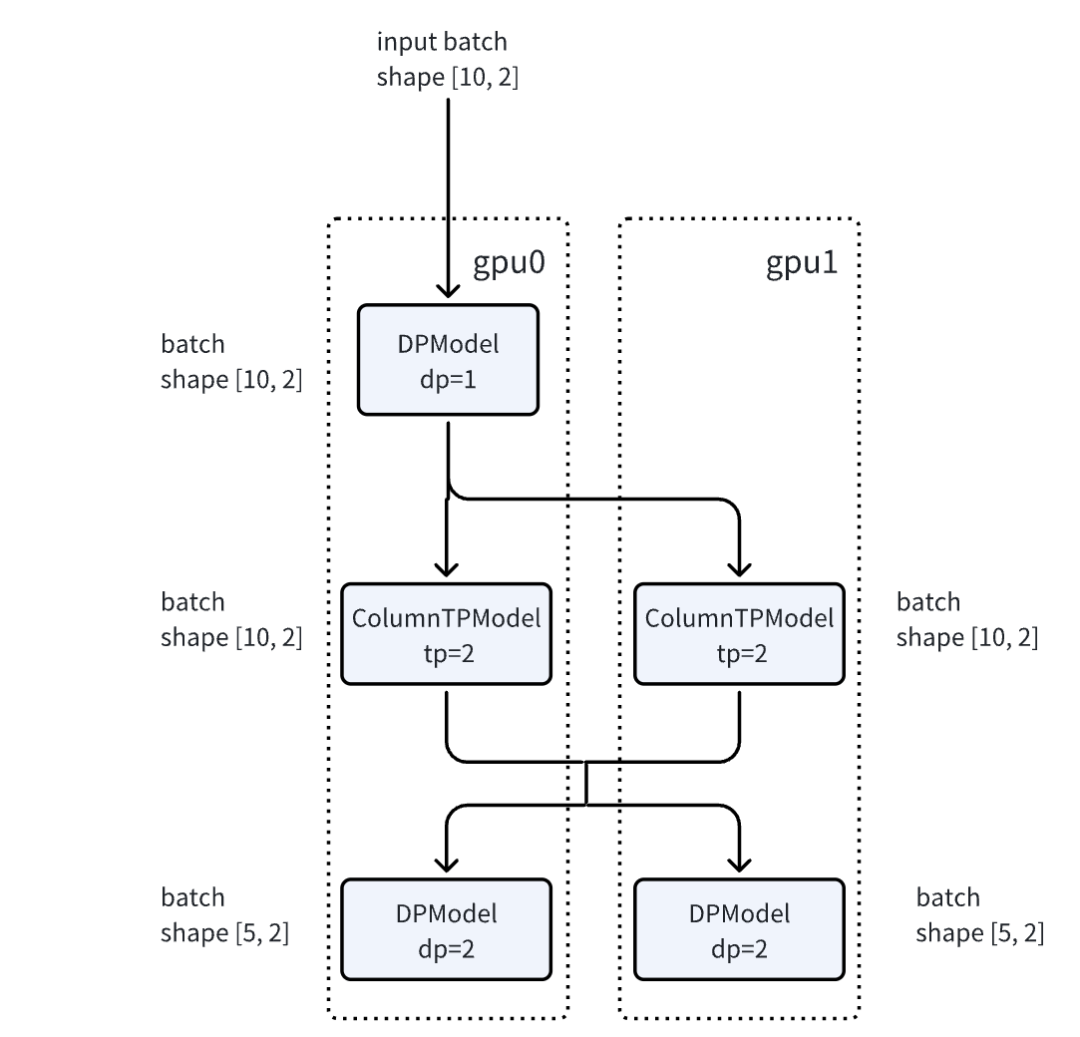
在verl里一个很通用的场景是dp和tp互转,假设在world_size=8的集群里,整体pipeline上有三个模型,model1和model3没有做切分,使用的是dp=8;而model2使用的是tp=8的切分。
此时要如何安排数据流呢。
首先model1的输出结果在各个rank上是内容不同的tensor [bs, d],不能直接用于tp切分的model2的计算,需要经过all gather操作,使得各个rank得到一个内容相同的tensor [8*bs, d],作为model2的输入;
而model2的输出在各个rank上是一个内容相同的[8*bs, d]的tensor,固然可以直接给model3做计算,但显然是重复计算的,每个rank上的model是一个完整模型,可以接收不同的输入。所以在这里把[8*bs, d]的结果切回到各个rank上[bs, d]的形式,做model3的计算。
DP阶段 → TP阶段转换:
-
原始输入:[bs, d](各rank独立)
-
通过all-gather沿batch维度拼接 → [8bs, d](全局统一)
TP阶段计算:
-
每个rank维护1/8模型参数
-
执行分片矩阵运算
TP阶段 → DP阶段还原:
-
输出结果沿batch维度切分 → [bs, d]
-
避免DP阶段重复计算
我们再举一个llava的例子。对于llava这种模型,本质是视觉部分产出一个vision embedding,文本部分出一个text embedding,把它们拼在一起,放进transformers里面开始计算。
一个非常常见的场景是,视觉部分的模型很小,大概3b以下,而文本部分的模型很大,可能要到30b。这种情况下我们一般不会对vit部分做切分,而是对llm部分用tp切一下。这样改起来成本比较低,vit太小没必要切,而且把tp塞进去也要掉一点头发;而llm的切分比较成熟。
这种时候我们就可以动一点心思了,假设world_size=2,tp=2,vit不切,则共有两份完整的vit模型,即vit部分dp=2。
因此,对于一个batch我们可以切成两份,分别送给vit拿到vision embedding,再gather起来,避免重复计算。 然后文本部分由于tp=2,就正常做vocab embedding的切分,正常做transformer的计算。当然可以在vision embedding通信的时候async执行vocab embedding的计算,算是可以做一下overlap。
牢记tp group的输入需要保持一致,而dp group的输入不一致,就足以理解verl的数据流处理代码了。
rollout优化
好了,让我们回到之前的问题,为什么naive的方式难以scale up。首先最大的问题就是transformers原生的generate在zero3时表现拙劣,而不用zero3又会OOM。
Zero3模式下,每次前向计算都需通过all-gather获取完整模型参数。在自回归生成场景下,每个token的生成都触发独立的前向传播,导致通信量与模型参数量呈线性增长关系。对于更大的模型,这种通信模式将产生难以承受的带宽压力。
而stage3的actor model training部分,由于只需要做一次forward,耗时上升不那么明显。
TRL框架对此的优化策略是通过deepspeed.zero.GatheredParameters上下文管理器。
with deepspeed.zero.GatheredParameters(model.parameters()):
outputs = model.generate(...)
该方案将原本逐token的all-gather操作转换为单次全局参数收集,显著降低通信频率。但生成期间需持续占用完整参数显
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











