






全文总结
这篇论文介绍了一个名为DanZero+的AI系统,旨在通过强化学习技术解决复杂的牌类游戏GuanDan中的挑战。
研究背景
- 背景介绍: 这篇文章的研究背景是人工智能(AI)在扑克、麻将和德州扑克等复杂卡牌游戏中取得了显著进展。然而,GuanDan作为一种在中国非常流行的四人卡牌游戏,由于其庞大的状态和动作空间、长游戏过程以及复杂的规则,仍然是一个未解决的挑战。
- 研究内容: 该问题的研究内容包括开发一个AI程序来应对GuanDan游戏的复杂性,特别是其庞大的状态和动作空间、长游戏过程以及玩家数量的变化。
- 文献综述: 该问题的相关工作主要集中在使用启发式规则和CFR方法来构建GuanDan的AI。现有的AI程序在处理复杂的状态和动作空间时表现不佳,而强化学习技术在处理大规模游戏方面显示出潜力。
研究方法
这篇论文提出了使用强化学习技术来解决GuanDan游戏的复杂性。具体来说,
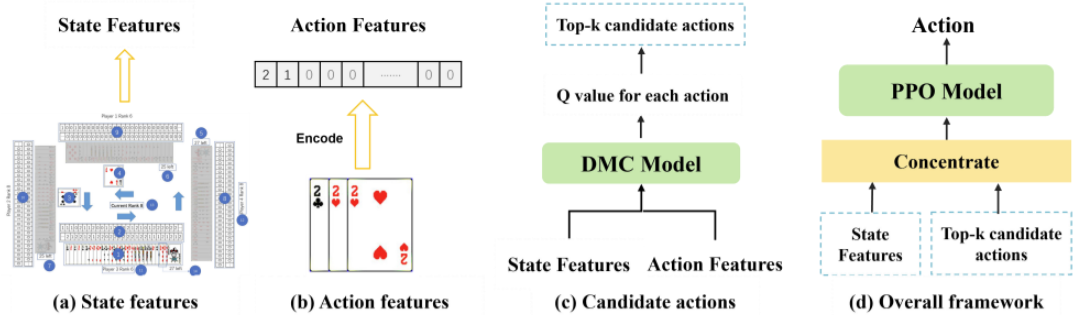
- Deep Monte Carlo (DMC): 该方法利用深度神经网络来近似值函数和策略,通过分析与环境交互的经验来获取知识。DMC方法适用于具有有限长度的离散任务,通过在每个回合结束时更新值和策略来进行训练。
- Proximal Policy Optimization (PPO): 为了进一步提升AI的能力,论文采用了PPO算法。PPO通过引入裁剪方法和优势函数的广义优势估计(GAE)来优化策略,避免策略退化的问题。PPO算法在多种环境和任务中表现出色,适合处理大规模游戏。
实验设计
- 实验设置: 论文通过基准测试评估AI系统的性能,使用中国人工智能GuanDan竞赛中的前8名规则基代理作为对手。实验在一个包含4个Intel Xeon Gold 6252 CPU和GeForce RTX 3070 GPU的服务器上进行。
- 数据收集: AI系统通过分布式自玩框架进行训练,每个演员进程维护四个代理与游戏核心交互,生成数据样本。
- 参数配置: DMC模型的超参数包括随机探索概率、内存池大小、批量大小、训练频率、学习率等。PPO模型的超参数包括候选动作数量、GAE的gamma和lambda值、学习率、优化器等。
结果与分析
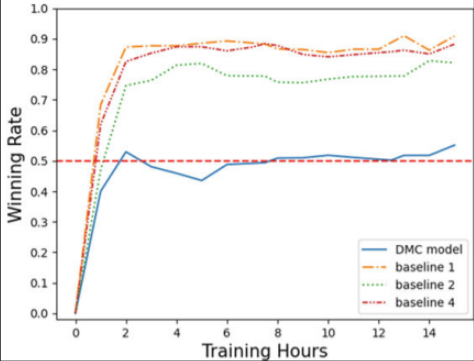
- DMC模型表现: DMC模型在与规则基代理的对战中表现出色,胜率显著高于其他代理。实验结果显示,DMC模型在训练足够的情况下,胜率达到80%。
- 人类玩家对比: 在与人类玩家的比赛中,AI系统在100场比赛中赢得了71场,显示出良好的决策能力。
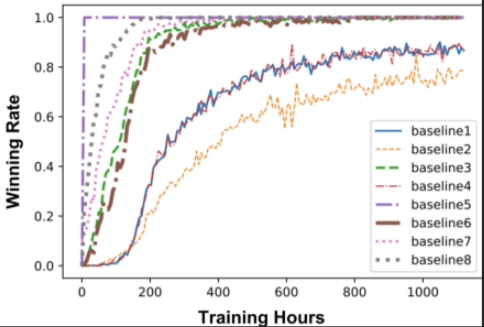
- PPO增强模型: PPO模型在候选动作数量为2的情况下,胜率进一步提升。实验结果表明,PPO模型在处理复杂的动作空间时表现出色,能够更好地适应不同的场景。
结论
这篇论文提出了一种用于GuanDan游戏的AI系统,通过结合Deep Monte Carlo和Proximal Policy Optimization算法,显著提升了AI的性能。实验结果验证了该方法的有效性,表明其在处理复杂卡牌游戏方面的潜力。论文的贡献为后续研究提供了基准,并为进一步改进GuanDan AI奠定了基础。
这篇论文展示了在复杂卡牌游戏中应用强化学习技术的成功案例,具有重要的理论和实践意义。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在一款名为关丹(GuanDan)的复杂卡牌游戏中开发一个AI程序。关丹游戏涉及四个玩家在长时间的游戏过程中进行竞争和合作,以提升自己的等级,这对AI来说是一个巨大的挑战,因为它具有庞大的状态空间和动作空间,较长的剧集长度以及复杂的规则。
- 研究难点:该问题的研究难点包括:
-
关丹游戏的状态空间和动作空间非常大,使用两副扑克牌,并且牌的花色在组合中起重要作用。
-
-
每局游戏的剧集较长,每个代理在每个剧集中需要做出超过100个决策。
-
游戏过程中玩家数量可能会变化,增加了游戏的复杂性。
-
在某些状态下合法动作的数量不确定,最多可达5000个,但在游戏过程中会迅速减少。
-
- 相关工作:该问题的研究相关工作包括:
- 现有的AI程序主要依赖于启发式规则和CFR方法。
- 之前尝试使用UCT算法开发的AI程序表现仅略优于随机代理。
- 传统的基于价值的强化学习算法如DQN在处理大范围动作空间时会遇到过估计问题。
- 策略梯度方法如A3C在面对大范围动作空间时表现不佳。
研究方法
这篇论文提出了一种基于深度蒙特卡罗(DMC)和分布式训练框架的强化学习方法,用于解决关丹游戏中的AI问题。具体来说,
- 深度蒙特卡罗(DMC):DMC方法利用深度神经网络进行函数逼近,能够在不需要偏置的情况下近似真实值。DMC适用于 episodic 任务,通过分析在与环境交互过程中采样的状态、动作和奖励来获取价值函数和最优策略。每个剧集结束时,观察到的回报用于策略评估,从而在剧集访问的状态下增强策略。
- 近端策略优化(PPO):PPO是一种著名的策略梯度演员-评论家算法,旨在解决vanilla Policy Gradient(VPG)方法中的优化过程不稳定问题。PPO通过引入替代优化函数来替换VPG中的优化目标:
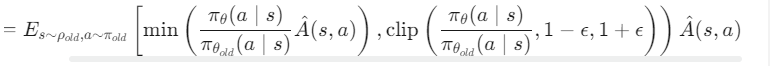 Lclipped=Es∼ρold,a∼πold[min(πθold(a∣s)πθ(a∣s)A^(s,a)),clip(πθold(a∣s)πθ(a∣s),1−ϵ,1+ϵ))A^(s,a)其中,ρold 表示旧策略下的状态分布,A^ 是估计的优势。PPO通过剪辑方法来限制更新后策略与旧策略之间的差异,从而有效防止策略在训练过程中恶化。
Lclipped=Es∼ρold,a∼πold[min(πθold(a∣s)πθ(a∣s)A^(s,a)),clip(πθold(a∣s)πθ(a∣s),1−ϵ,1+ϵ))A^(s,a)其中,ρold 表示旧策略下的状态分布,A^ 是估计的优势。PPO通过剪辑方法来限制更新后策略与旧策略之间的差异,从而有效防止策略在训练过程中恶化。- 分布式训练框架:框架分为演员和学习者两个部分。演员负责进行游戏模拟和数据样本收集,每个演员维护四个代理与环境交互。学习者负责更新网络参数,从演员收集的数据样本中学习。分布式训练框架允许多个演员并行执行,从而高效地收集数据样本并减少方差。
实验设计
- 数据收集:实验在服务器上进行,服务器配备4个Intel Xeon Gold 6252 CPU @ 2.10GHz和一块GeForce RTX 3070 GPU,运行在Ubuntu 16.04系统上。
- 实验设置:为了评估AI系统的有效性,进行了基准测试,将模型与各种基线算法进行比较。两个代理使用模型,对方团队使用基线算法。DMC模型的检查点在每24小时保存一次,而PPO模型的检查点每小时保存一次。
- 样本选择:每个剧集结束时,根据剧集结果为每一样本分配一个值。胜利团队的轨迹样本值分别为+3、+2和+1,失败团队则为相应的负值。最终,如果团队赢得剧集,则在轨迹样本中额外添加+1的值。
- 参数配置:DMC模型的超参数包括:探索概率ϵ=0.01,记忆池大小65536,批量大小32768,训练频率250,剪辑范围0.65,学习率0.001,优化器RMS。PPO增强模型的超参数包括:记忆池大小2048,批量大小2048,训练频率13,GAE的γ和λ分别为0.99和0.95,学习率0.0001,优化器Adam,候选动作数2,剪辑比例0.2,损失权重1, 0.5, 0.05。
结果与分析
-
DMC模型与基线算法的比较:DMC模型在1000局游戏中对基线算法的平均胜率表明,AI系统一致性地优于基线算法。经过充分训练后,AI系统除了对基线1、基线2和基线4外,对其他基线算法均有绝对优势。
-
-
人类评估:在100局人类与AI的对局中,AI系统取得了71次胜利。案例研究表明,AI程序展示了良好的决策能力,能够根据不同的游戏情境做出合理的决策。
-
-
PPO增强模型的性能:尽管简化了动作空间,PPO增强模型仍然表现出优于基线算法的性能。实验结果表明,PPO算法显著提高了AI系统的适应性和决策能力。
-
候选动作数量的影响:在不同候选动作数量的PPO模型中,选择两个候选动作的PPO模型在1000局游戏中对基线算法的胜率最高,证明了该方法的有效性。
总体结论
本文提出了一种基于深度蒙特卡罗(DMC)和分布式训练框架的强化学习方法,用于解决关丹游戏中的AI问题。通过实验验证,所提出的AI系统(DanZero+)在性能上显著优于现有的基线算法,并且在面对复杂的游戏环境和大规模动作空间时表现出强大的适应性和决策能力。本文的贡献为关丹游戏AI的研究提供了新的思路和基准,并为后续研究奠定了基础。
论文评价
优点与创新
- 提出了一种新的AI系统:论文提出了一个名为DanZero的AI程序,专门用于解决复杂且流行的卡牌游戏关丹(GuanDan)。
- 采用深度蒙特卡罗(DMC)方法:利用深度神经网络进行函数逼近,能够在没有偏差的情况下近似真实值,适用于 episodic 和奖励稀疏的任务。
- 分布式训练框架:通过并行演员执行,高效地收集数据样本,减少方差。
- 引入预训练模型:使用DMC方法训练的模型提供候选动作,显著降低了计算复杂度。
- 应用近端策略优化(PPO)算法:通过引入额外的正则化项,解决了传统策略梯度方法中的不稳定问题,提高了模型的鲁棒性和适应性。
- 人类评估:通过与人类玩家的对比评估,展示了AI系统在实际游戏中的决策能力。
不足与反思
- 初始手牌分布的影响:实验结果表明,初始手牌分布对游戏结果有很大影响,增加了结果的方差。
- 候选动作数量的限制:在增强AI系统的实验中,将候选动作数量限制为2,虽然简化了问题,但仍不足以应对游戏的复杂性。
- 计算资源需求:使用预训练模型和PPO算法增加了计算资源的需求,特别是在处理大规模动作空间时。
- 下一步工作:论文提到,尽管PPO算法在大多数情况下表现良好,但在某些特定场景下仍需进一步优化和调整。
关键问题及回答
问题1:在关丹游戏中,DMC方法和PPO算法是如何结合使用的?它们各自在AI系统中的作用是什么?
-
DMC方法:DMC方法利用深度神经网络进行函数逼近,能够在不需要偏置的情况下近似真实值。它适用于 episodic 任务,通过分析在与环境交互过程中采样的状态、动作和奖励来获取价值函数和最优策略。每个剧集结束时,观察到的回报用于策略评估,从而在剧集访问的状态下增强策略。DMC方法在AI系统中的作用主要是通过深度神经网络来高效地估计价值函数,为后续的策略优化提供基础。
-
PPO算法:PPO是一种著名的策略梯度演员-评论家算法,旨在解决vanilla Policy Gradient(VPG)方法中的优化过程不稳定问题。PPO通过引入替代优化函数来替换VPG中的优化目标,并通过剪辑方法来限制更新后策略与旧策略之间的差异,从而有效防止策略在训练过程中恶化。PPO在AI系统中的作用是通过细粒度的策略更新来提高AI系统的适应性和决策能力,特别是在面对大规模动作空间时表现尤为出色。
-
结合使用:在AI系统中,DMC方法和PPO算法结合使用,首先使用DMC方法通过深度神经网络高效地估计价值函数,然后利用PPO算法对策略进行精细调整。具体来说,DMC方法提供一个初始的策略估计,PPO算法在此基础上进行进一步的优化,确保策略在复杂的游戏环境中能够快速适应和做出合理的决策。
问题2:在分布式训练框架中,演员和学习者的角色分别是什么?它们如何协同工作?
在分布式训练框架中,演员和学习者各自承担不同的角色,并协同工作以实现高效的训练。
-
演员(Actor):演员的主要职责是进行游戏模拟和数据样本收集。具体来说,每个演员维护四个代理,这些代理与环境交互,生成数据样本。在每个迭代过程中,演员从学习者处获取最新的模型参数,并在环境中启动新的一集。演员通过与环境交互,收集状态、动作和奖励数据,并将这些数据样本传递给学习者进行模型训练。
-
学习者(Learner):学习者的主要责任是更新网络参数。它从演员收集的数据样本中学习,通过优化算法来改进模型的性能。具体来说,学习者接收演员传递的数据样本,计算损失函数,并使用优化算法更新模型参数。学习者的更新过程是基于批处理的,能够高效地处理大量数据样本。
-
协同工作:演员和学习者在分布式训练框架中协同工作,形成一个高效的数据收集和模型更新的循环。演员通过模拟游戏生成数据样本,并将这些样本传递给学习者;学习者则利用这些数据进行模型训练,并将更新后的模型参数返回给演员。这种分工合作的机制使得整个训练过程能够高效地进行,并且能够处理大规模的数据样本和复杂的计算任务。
问题3:实验结果表明,DMC模型和PPO增强模型在关丹游戏中的表现如何?它们与传统基线算法相比有哪些优势?
-
DMC模型:DMC模型在1000局游戏中对基线算法的平均胜率表明,AI系统一致性地优于基线算法。经过充分训练后,AI系统除了对基线1、基线2和基线4外,对其他基线算法均有绝对优势。这表明DMC模型在处理关丹游戏的复杂环境和大规模动作空间时表现出色,能够有效地估计价值函数并制定合理的策略。
-
PPO增强模型:尽管简化了动作空间,PPO增强模型仍然表现出优于基线算法的性能。实验结果表明,PPO算法显著提高了AI系统的适应性和决策能力。PPO增强模型在1000局游戏中对基线算法的胜率最高,进一步证明了该方法的有效性。
-
优势:DMC模型和PPO增强模型相比传统基线算法有以下几个主要优势:
- 高效的价值估计:DMC方法利用深度神经网络进行函数逼近,能够在不需要偏置的情况下近似真实值,提高了价值估计的准确性。
- 细粒度的策略优化:PPO算法通过引入替代优化函数和剪辑方法,能够在细粒度上调整策略,提高了策略的适应性和稳定性。
- 大规模数据处理能力:分布式训练框架使得AI系统能够高效地处理大规模的数据样本和复杂的计算任务,加快了模型的训练速度。
- 强大的适应性:PPO算法在处理大规模动作空间时表现尤为出色,能够快速适应不同的游戏环境和对手策略。
综上所述,DMC模型和PPO增强模型在关丹游戏中表现出色,显著优于传统的基线算法,展现了强大的适应性和决策能力。


















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











