







 超级会员免费看
超级会员免费看
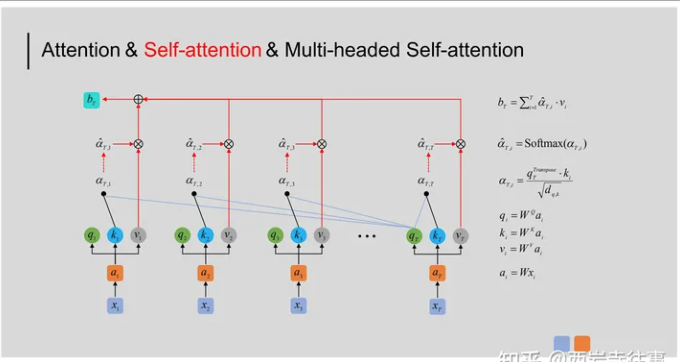
对于输入的序列 ![]() 来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对
来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对![]() 进行计算,这大大提高了对
进行计算,这大大提高了对![]() 特征进行提取(即获得
特征进行提取(即获得![]() )的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:
)的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:
对于输入的序列 ![]() 来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对
来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对![]() 进行计算,这大大提高了对
进行计算,这大大提高了对![]() 特征进行提取(即获得
特征进行提取(即获得![]() )的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:
)的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:
 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























