







 本文详细解读了vLLM的源码,介绍了核心模块如Sequence、SequenceGroup、SamplingParams等,展示了大模型推理如何通过多GPU并行处理和调度机制实现高效计算,适用于AutoML和机器学习任务。
本文详细解读了vLLM的源码,介绍了核心模块如Sequence、SequenceGroup、SamplingParams等,展示了大模型推理如何通过多GPU并行处理和调度机制实现高效计算,适用于AutoML和机器学习任务。
大模型推理框架 vLLM 源码解析(一)
原创 marsggbo AutoML机器学习 2024-02-04 18:13
1. Quick Start
创建如下代码,命名为 run.py
from vllm import LLM, SamplingParams
prompts = [
"Have you followed marsggbo in Zhihu?",
"你一键三连了吗?"
] # 输入prompts
sampling_params = SamplingParams(temperature=0.8, top_k=50) # 采样策略
llm = LLM(model="facebook/opt-125m", tensor_parallel_size=2) # 初始化 LLM
outputs = llm.generate(prompts, sampling_params) # 完成推理
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
执行命令:python run.py。该脚本会自动将模型以张量并行的方式在两个 GPU 上进行推理计算。
整个推理过程大大致流程如下图所示,即 1 给定一定数量的 prompts(字符串数组) 2. vllm 会使用 Scheduler 模块自动对需要推理句子进行调度
3. 根据调度的结果,使用 tokenizer 将字符串转换成 prompt id,然后喂给 model 进行计算得到 logits 预测结果 4. 根据 logits 预测结果和提前设置好的采样策略对结果进行采样得到新的 token id 5. 将采样结果保存到 output

inferencce pipeline
2. 整体核心模块
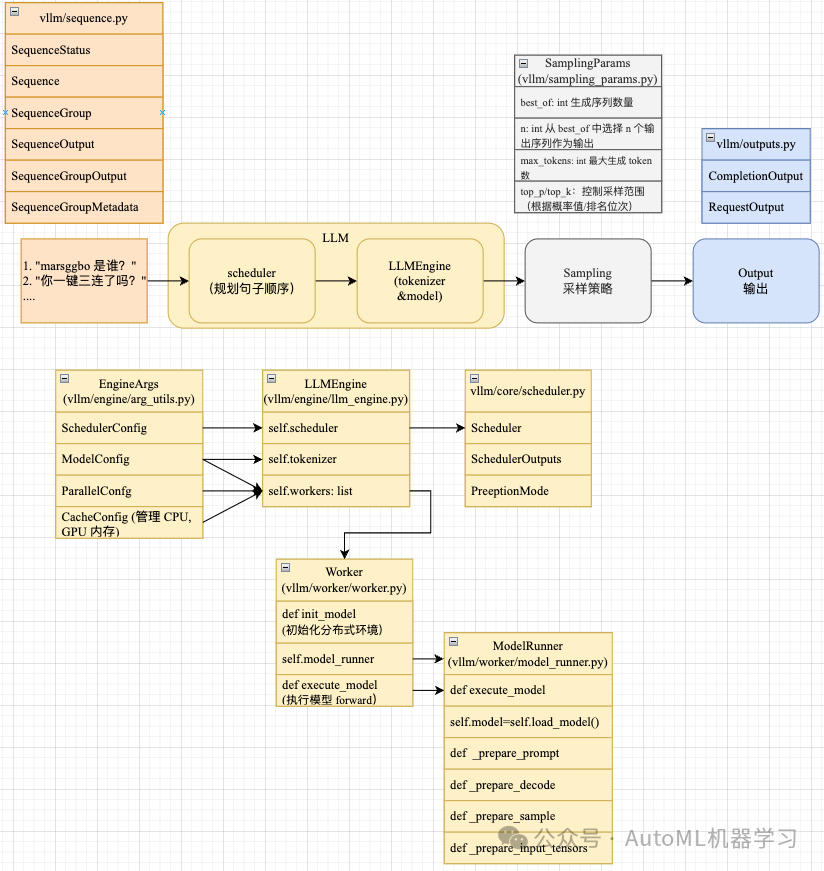
上图给出了 vLLM 核心模块之间的结构关系。接下来我们从简单的模块(即输入、采样和输出)开始介绍,最后详细介绍 LLM 模块。
3. Sequence

如上图我们可以看到 vLLM 为输入的句子设计了很多子模块,这些模块的用处各不相同,但是有彼此之间有关系,下面分别详细介绍一下。
3.1 SequenceStatus
首先看到 SequenceStatus,其源代码如下:
class SequenceStatus(enum.Enum):
"""Status of a sequence."""
WAITING = enum.auto() # 等待中,句子还没开始推理,或者推理还未结束
RUNNING = enum.auto() # 运行中
SWAPPED = enum.auto() # 已交换
FINISHED_STOPPED = enum.auto() # 已停止
FINISHED_LENGTH_CAPPED = enum.auto() # 已长度限制
FINISHED_ABORTED = enum.auto() # 已中止
FINISHED_IGNORED = enum.auto() # 已忽略
@staticmethod
def is_finished(status: "SequenceStatus") -> bool:
# 判断状态是否为已停止、已长度限制、已中止或已忽略
return status in [
SequenceStatus.FINISHED_STOPPED,
SequenceStatus.FINISHED_LENGTH_CAPPED,
SequenceStatus.FINISHED_ABORTED,
SequenceStatus.FINISHED_IGNORED,
]
3.2 SequenceData
SequenceData 用于存储与序列相关的数据。这个类有三个属性:prompt_token_ids(提示词的标记ID)、output_token_ids(生成文本的标记ID)和cumulative_logprob(累计对数概率)。
class SequenceData:
def __init__(
self,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3989
3989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











