






Manus和openai都在GAIA上瞎搞....
原创 包包闭关修炼 包包算法笔记 2025年03月15日 20:16 美国
事情的起因是我发现Manus和openai的Deep Reasearch都报告了在GAIA上有很高的分,我翻来翻去也没找到。
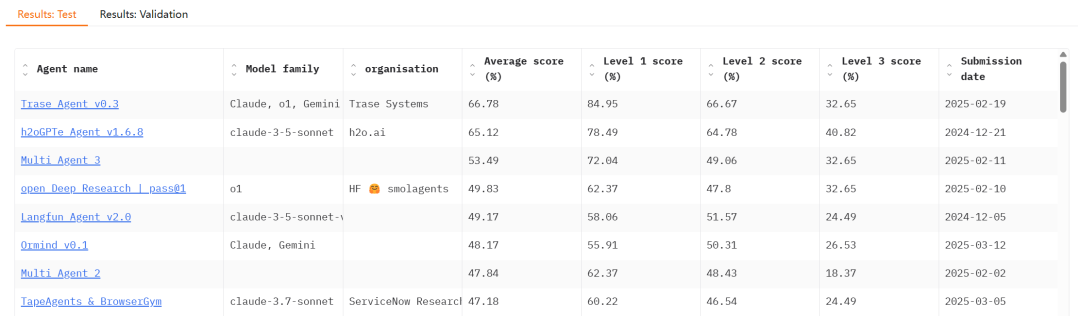
然后我仔细研究发现,manus和openai都在leaderboard上瞎搞....
榜单地址:https://huggingface.co/gaia-benchmark
先回顾下,GAIA是一个评测agent能力的榜单,比如给你一个excel表,让你统计一下三年二班的总分最高分的同学对应的数学分。然后大模型要干的事儿是与调用tool完成任务,给出最终结果。
import pandas as pd
# 读取Excel文件
df = pd.read_excel('test.xlsx')
# 计算每个学生的总分
df['total_score'] = df[['math', 'english', 'chinese', 'physics', 'chemistry']].sum(axis=1)
# 找到总分最高的学生
max_total_score_student = df.loc[df['total_score'].idxmax()]
# 输出该学生的数学分数
math_score_of_max_total_score_student = max_total_score_student['math']
print(f"三年二班总分最高的同学的数学分数是: {math_score_of_max_total_score_student}")
正常的leaderboard都有两部分组成,一部分验证集,一部分测试集。现在比较好的leaderboard都是采用类似Kaggle 比赛的形式,可以交模型、代码、api,测试集数据不可见,所以结果可信度很高。大家可以在本地看valid验证集的分,然后提交到线上看隐藏测试集的分。
但问题就出在GAIA这个,验证集的数据是可以直接下发在本地的,相当于人手一个题目和答案。
然后就有好事者joker提交个满分。
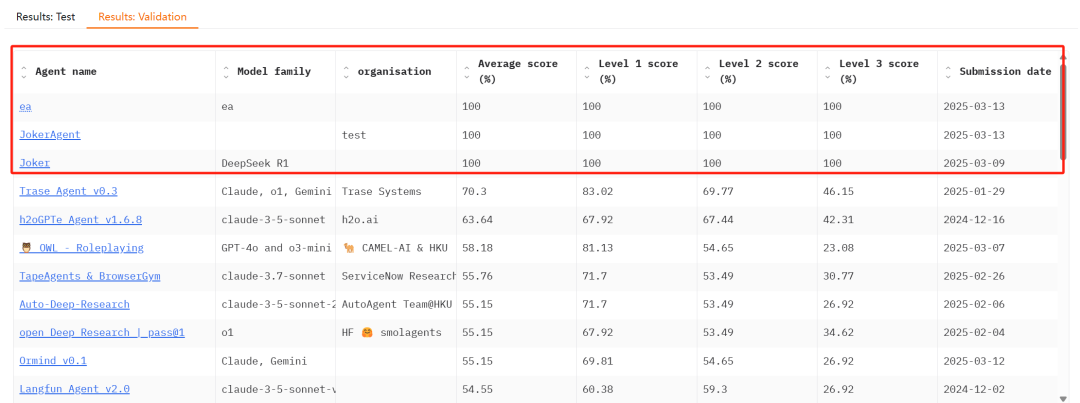
我们仔细看看manus和oepnai报的分数。

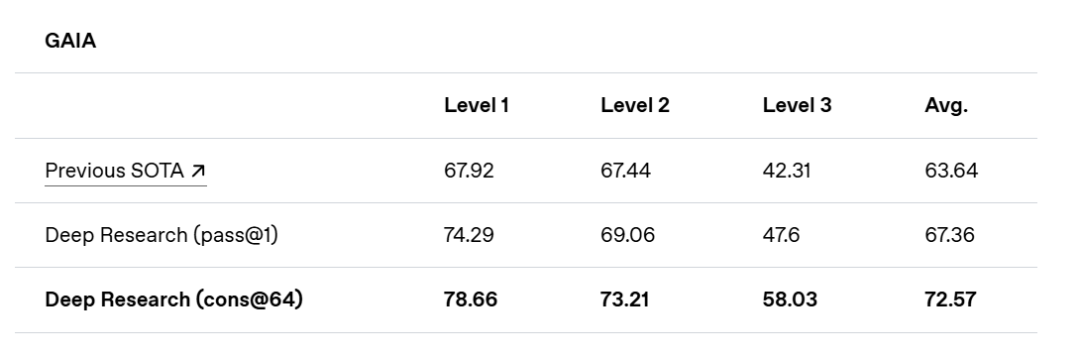
好家伙,敢情是valid上的分数呀?67.92 67.44 42.31都是H2O的验证集分数。
这是非常不专业的行为,这个坏头是openai干的,我建议manus不要学坏。大家都老老实实在test上提交吧。
关于这个,我也找GAIA官方确认了下,老哥也是这猜的。

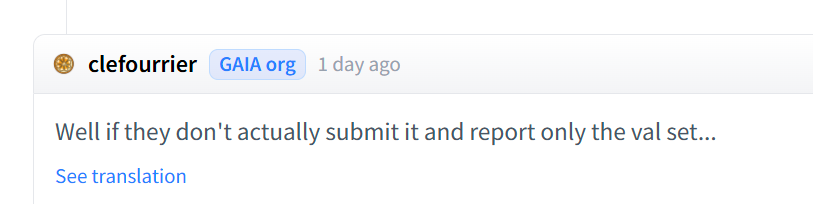
嗯,希望大家不要再瞎搞了...


















 216
216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











