






目前最强的2个代码生成 AI 模型
原创 川后静波 吴建明利驰数字 2025年04月12日 18:38 陕西
Google 在 3 月 26 日正式推出了 Gemini 2.5 Pro,官方宣称在编程、推理以及整体能力上都是目前最强的模型。但我们更关心的是:它和 Claude 3.7 Sonnet(thinking) 相比,谁才是当前最强的编程模型?
Claude 3.7 是今年 2 月底发布的,使用体验一直非常棒。这里[1]将通过多项编程任务对这两款模型进行对比,看看它们在实际应用中的表现。
TL;DR
如果你只想看结论:可以直接选择 Gemini 2.5 Pro。
它在编程方面表现更强,支持高达 100 万 tokens 的上下文窗口(而 Claude 是 20 万),而且——它是免费的!。虽然 Claude 3.7 Sonnet 的表现也很优秀,但相比之下,现在已经没什么理由再坚持用它了。
Gemini 2.5 Pro 简介
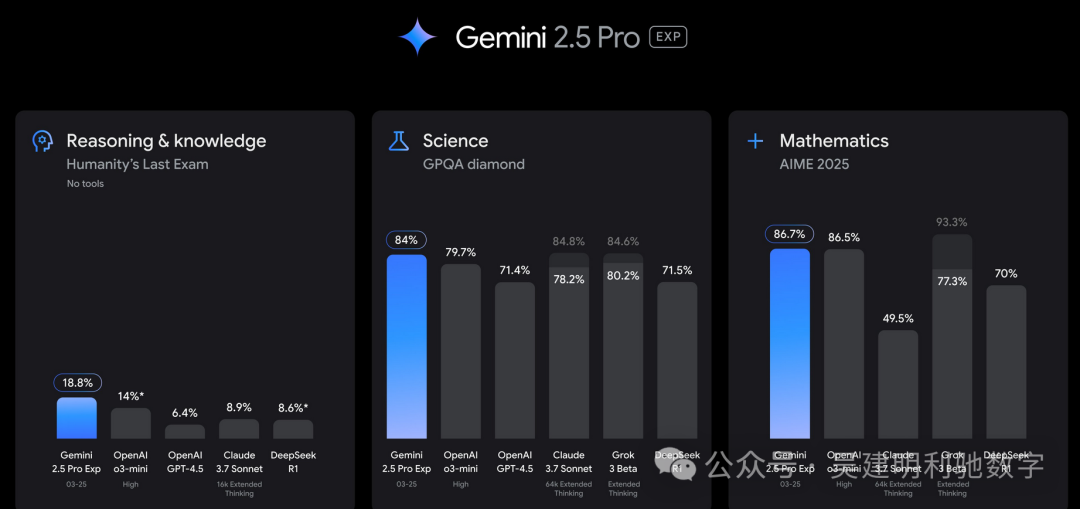
Gemini 2.5 Pro 是Google推出的最新一代“思维型模型”。这款模型上线不到一周,便迅速登上了 LMArena 排行榜的第一名,表明其在编程、数学、科学推理等领域的强大能力。
其最大的亮点之一是 100 万 tokens 的上下文窗口,让其能够处理更长的文本,更加适合进行复杂的编程任务。

关键亮点:
-
• 支持 100 万 tokens 的上下文窗口,能够处理大量文本;
-
• 在编程、数学、推理等领域有着出色的表现;
-
• 提供快速的基准测试成绩,能够在多个任务中取得较高准确率, 63.8%。
而之前的王者——Claude 3.7 Sonnet,在同一测试中的准确率是 62.3%。虽然差距看起来不大,但在这个级别的模型比拼中,每提高一个百分点都意味着巨大的突破。

谷歌还放出了一段快速演示视频,展示如何用这个模型构建一个恐龙小游戏:
,时长00:44
同时,官方还给出了该模型在推理、数学和科学等方面的基准测试成绩——这也进一步说明,它不仅擅长编程,还能胜任其他各种任务。官方直接宣称它是“全能选手”。🤷♂️
编程实测:谁才是最强编程模型?
为了全面评估这两款模型在编程领域的表现,本文准备了四道实际的编程题,涉及 Web 开发、动画效果以及 LeetCode 难度较高的问题。
以下是对比结果:
1. 飞行模拟器
提示词:
使用 JavaScript 创建一个简单的飞行模拟器。该模拟器应具备以下功能:
• 一个基础的飞机模型,能够从一条平坦的跑道上起飞;
• 飞机的移动应通过简单的键盘输入进行控制(例如,方向键或 WASD 键);
• 同时生成一个基础的城市景观,使用类似于《Minecraft》风格的方块结构来构建城市。
Gemini 2.5 Pro:成功生成了完整的飞行模拟器代码,控制效果平稳,飞行过程中城市景观正常显示。
,时长01:18
Claude 3.7 Sonnet:也生成了代码,但飞行模拟器的控制不如 Gemini 2.5 Pro 稳定,飞机控制时出现轻微抖动。
,时长00:52
结论: Gemini 2.5 Pro 在这道题上表现更佳,代码稳定且效果更理想。
2. 魔方求解器
提示词:
用 JavaScript(结合 Three.js)制作一个 3D 魔方可视化工具 + 求解器,要求如下:
• 魔方是标准的 3×3 结构,颜色标准;
• 有一个 “打乱” 按钮,点击后随机打乱魔方;
• 有一个 “求解” 功能,点击后能一步步动画还原魔方;
• 支持基础的鼠标旋转视角。
Gemini 2.5 Pro:成功实现了魔方的交互式可视化,打乱和求解功能正常。
,时长00:34
Claude 3.7 Sonnet:虽然实现了部分功能,但在求解算法和动画效果方面存在明显不足。
,时长00:52
结论: Gemini 2.5 Pro 能够更准确地完成任务,特别是在动画和算法部分。
3. 球在旋转的 4D 超立方体内弹跳
提示词:
创建一个简单的 JavaScript 脚本,用于可视化一个球在旋转的四维超立方体(Tesseract)内部弹跳的过程。当球碰撞到某一面时,需高亮显示该面以表示发生了撞击。
Gemini 2.5 Pro:生成的代码运行顺畅,球体与碰撞的物理反应精准。
,时长00:20
Claude 3.7 Sonnet:尽管实现了基本功能,但在碰撞效果和高亮显示方面略显逊色。
,时长00:20
结论: Gemini 2.5 Pro 在处理高维度问题时表现更为精准。
4. LeetCode 高难度问题
题目要求: 解答一个 LeetCode 上的高难度问题,接受率仅为 14.9%。
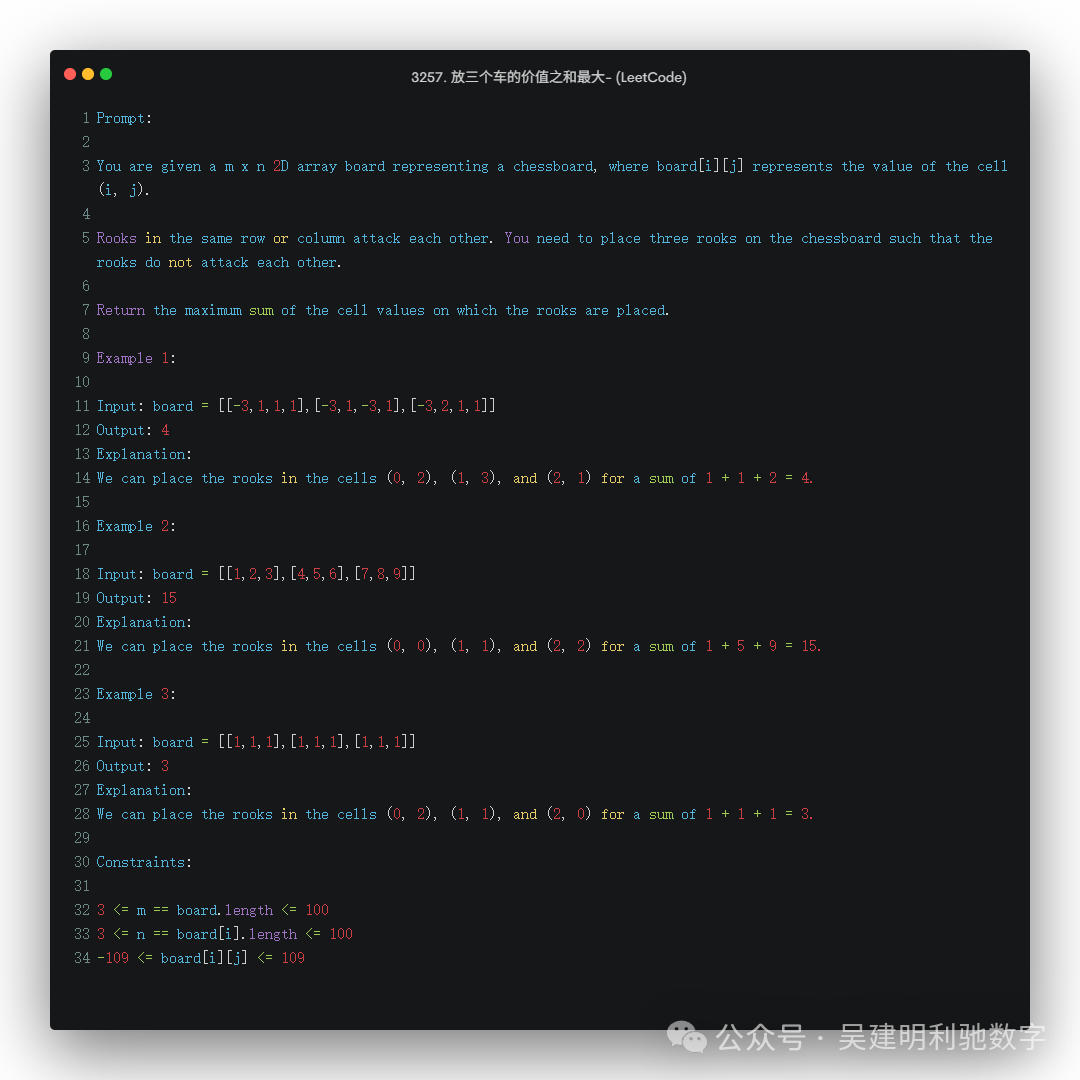
Gemini 2.5 Pro:成功解答了该问题,并且代码实现相对复杂。
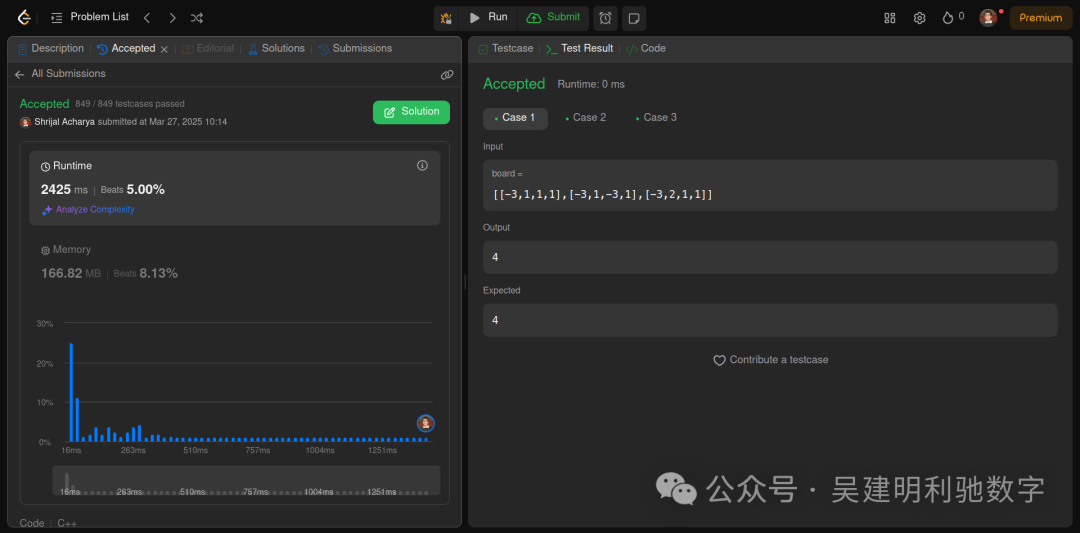
Claude 3.7 Sonnet:同样成功解答,但提供的代码更加简洁。
结论: Claude 3.7 Sonnet 在简洁性方面表现更好,但 Gemini 2.5 Pro 的代码复杂性略高,适用于更为复杂的任务。
总结
通过以上对比测试,可以得出结论:Gemini 2.5 Pro 在绝大多数编程任务中都表现出色,尤其在处理复杂任务时具有明显的优势。
其 100 万 tokens 的上下文窗口使其能够处理更大范围的数据,适合我们进行长文本的编程任务。而 Claude 3.7 Sonnet 虽然在某些任务中表现得不错,但在面对更复杂的编程问题时,其优势相对较小。
引用链接
[1] https://www.ruanyifeng.com/blog/2025/04/weekly-issue-344.html


















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











