<think>我们正在讨论如何在DB-GPT中使用本地大模型(如ChatGLM)。DB-GPT是一个开源的数据库智能交互系统,它允许用户通过自然语言与数据库进行交互。使用本地大模型可以避免依赖外部API,提高数据隐私性。
步骤:
1. 下载模型:首先需要下载ChatGLM模型的文件(通常包括模型权重和配置文件)。可以从Hugging Face模型库获取。
2. 配置模型路径:在DB-GPT的配置文件中指定模型路径。
3. 修改代码:调整DB-GPT的代码以使用本地模型而不是默认的OpenAI API。
4. 启动服务:运行DB-GPT并验证是否成功加载本地模型。
详细步骤:
### 1. 下载ChatGLM模型
我们可以使用`transformers`库提供的`AutoModel`和`AutoTokenizer`来加载模型。假设你已经下载了模型到本地目录`/path/to/chatglm-6b`。
### 2. 修改DB-GPT的配置文件
DB-GPT通常有一个配置文件(如`configs/model_config.py`或`configs/config.yaml`),我们需要修改该文件以指定使用本地模型。
例如,在`configs/model_config.py`中,我们可以添加如下配置:
```python
# 模型名称
MODEL_NAME = "chatglm-6b"
# 模型路径
MODEL_PATH = "/path/to/chatglm-6b"
# 使用本地模型
USE_LOCAL_MODEL = True
```
### 3. 修改模型加载代码
在DB-GPT中,通常有一个模块负责加载模型(例如`model_adapter.py`或`llm_loader.py`)。我们需要修改这个模块,使其能够加载本地ChatGLM模型。
假设原本使用的是OpenAI的API,现在我们要替换为本地ChatGLM。我们可以创建一个新的模型适配器:
```python
from transformers import AutoTokenizer, AutoModel
import torch
class ChatGLMModelAdapter:
def __init__(self, model_path):
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
self.model.eval()
def generate(self, prompt, **kwargs):
response, _ = self.model.chat(self.tokenizer, prompt, history=[], **kwargs)
return response
```
然后在DB-GPT的主逻辑中,我们使用这个适配器:
```python
# 根据配置加载模型
if config.USE_LOCAL_MODEL:
from .chatglm_adapter import ChatGLMModelAdapter
model_adapter = ChatGLMModelAdapter(config.MODEL_PATH)
else:
# 否则使用OpenAI等
pass
```
### 4. 修改对话处理逻辑
在DB-GPT中,处理用户查询的部分(可能在一个名为`dbgpt/app/llm_chat.py`的文件中)需要调用我们新创建的适配器。
例如,将原来的OpenAI调用:
```python
response = openai.ChatCompletion.create(...)
```
替换为:
```python
response = model_adapter.generate(prompt, max_length=4096, temperature=0.7)
```
### 5. 注意事项
- 确保有足够的GPU内存(ChatGLM-6B大约需要13GB GPU内存)。
- 如果内存不足,可以考虑使用量化版本(如`model = AutoModel.from_pretrained(model_path, trust_remote_code=True).quantize(8).half().cuda()`)或者使用CPU(但速度会慢很多)。
- 在启动时,模型加载可能需要几分钟。
### 6. 完整示例代码
下面是一个简化的示例,展示如何在DB-GPT中集成ChatGLM:
`chatglm_adapter.py`:
```python
from transformers import AutoTokenizer, AutoModel
class ChatGLMModelAdapter:
def __init__(self, model_path, device='cuda'):
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to(device)
self.model.eval()
def generate(self, prompt, history=None, max_length=4096, temperature=0.7, top_p=0.9, **kwargs):
if history is None:
history = []
response, updated_history = self.model.chat(
self.tokenizer,
prompt,
history=history,
max_length=max_length,
temperature=temperature,
top_p=top_p
)
return response
```
在主要服务文件中(如`llm_service.py`):
```python
from configs.model_config import MODEL_PATH, USE_LOCAL_MODEL
from .chatglm_adapter import ChatGLMModelAdapter
if USE_LOCAL_MODEL:
model_adapter = ChatGLMModelAdapter(MODEL_PATH)
else:
# 其他模型适配器
pass
def handle_query(query):
response = model_adapter.generate(query)
return response
```
### 7. 运行和测试
启动DB-GPT服务,然后使用自然语言进行查询,观察是否使用本地模型进行响应。
### 8. 可能遇到的问题及解决
- **问题:缺少`cuda`或`torch`相关错误**:确保安装了正确版本的PyTorch(支持GPU的版本)。
- **问题:模型加载慢**:第一次加载需要下载模型文件(如果未提前下载),建议提前下载好模型。
- **问题:显存不足**:尝试使用量化(如8位或4位量化)或使用更小的模型。
通过以上步骤,你应该能够在DB-GPT中成功使用本地ChatGLM模型。
---
### §§相关问题§§:
1. 如何对ChatGLM模型进行量化以降低显存占用?
2. 如何在DB-GPT中集成其他本地大模型(如LLaMA、Baichuan)?
3. 如何在CPU上运行ChatGLM模型?
4. 如何优化DB-GPT的响应速度?</think>## 在 DB-GPT 中使用本地大模型(如 ChatGLM)的完整指南
在 DB-GPT 中使用本地大模型(如 ChatGLM)需要配置模型路径、加载方式和推理引擎。以下是详细步骤和代码实现:
### 一、核心配置步骤
#### 1. 修改配置文件 `configs/model_config.py`
```python
# 模型配置示例
MODEL_CONFIG = {
"chatglm-6b": {
"model_name": "chatglm-6b",
"model_path": "/path/to/your/chatglm-6b", # 本地模型路径
"device": "cuda", # 或 "cpu"
"precision": "fp16", # fp16/fp32/int8/int4
"max_length": 4096,
"temperature": 0.7,
"top_p": 0.9,
"use_local": True # 关键:使用本地模型
},
# 其他模型配置...
}
# 设置默认模型
LLM_MODEL = "chatglm-6b"
```
#### 2. 修改模型加载器 `model/loader.py`
```python
from transformers import AutoModel, AutoTokenizer
def load_local_model(model_config):
"""加载本地模型"""
model_path = model_config["model_path"]
device = model_config["device"]
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# 加载模型
model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
device_map=device,
torch_dtype=torch.float16 if model_config["precision"] == "fp16" else torch.float32
)
# 量化配置(可选)
if model_config["precision"] == "int8":
model = model.quantize(8)
elif model_config["precision"] == "int4":
model = model.quantize(4)
return model, tokenizer
```
### 二、完整集成代码示例
#### 1. 创建模型适配器 `model/chatglm_adapter.py`
```python
import torch
from transformers import AutoModel, AutoTokenizer
class ChatGLMAdapter:
def __init__(self, model_path, device="cuda", precision="fp16"):
self.device = device
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# 加载模型
torch_dtype = torch.float16 if precision == "fp16" else torch.float32
self.model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
device_map=device,
torch_dtype=torch_dtype
).eval()
def generate(self, prompt, max_length=4096, temperature=0.7, top_p=0.9):
"""生成响应"""
inputs = self.tokenizer(
prompt,
return_tensors="pt"
).to(self.device)
outputs = self.model.generate(
**inputs,
max_length=max_length,
temperature=temperature,
top_p=top_p,
do_sample=True
)
response = self.tokenizer.decode(
outputs[0],
skip_special_tokens=True
)
return response[len(prompt):] # 返回生成的文本部分
```
#### 2. 在主服务中集成 `app/main.py`
```python
from model.chatglm_adapter import ChatGLMAdapter
from configs import model_config
# 初始化本地模型
chatglm_adapter = ChatGLMAdapter(
model_path=model_config.MODEL_CONFIG["chatglm-6b"]["model_path"],
device=model_config.MODEL_CONFIG["chatglm-6b"]["device"],
precision=model_config.MODEL_CONFIG["chatglm-6b"]["precision"]
)
def handle_query(query):
"""处理用户查询"""
# 1. 生成SQL
prompt = f"作为数据库专家,请为以下查询生成SQL: {query}"
sql = chatglm_adapter.generate(prompt)
# 2. 执行SQL
# ...(数据库连接和执行代码)
# 3. 解释结果
explanation_prompt = f"用自然语言解释以下SQL结果: {sql_result}"
explanation = chatglm_adapter.generate(explanation_prompt)
return sql, explanation
```
### 三、关键优化技巧
#### 1. 量化模型减少显存占用(4位量化)
```python
# 修改模型加载部分
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModel.from_pretrained(
model_path,
quantization_config=quant_config,
device_map="auto"
)
```
#### 2. 使用 vLLM 加速推理
```python
from vllm import LLM, SamplingParams
class ChatGLMvLLMAdapter:
def __init__(self, model_path):
self.llm = LLM(
model=model_path,
tensor_parallel_size=2, # GPU数量
dtype="half" # 半精度
)
self.sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=4096
)
def generate(self, prompt):
outputs = self.llm.generate([prompt], self.sampling_params)
return outputs[0].outputs[0].text
```
### 四、常见问题解决
1. **模型加载失败**:
- 确保模型路径正确
- 检查文件权限 `ls -l /path/to/model`
- 验证模型完整性(检查文件大小)
2. **显存不足**:
```bash
# 使用CPU卸载
model = AutoModel.from_pretrained(..., device_map="auto", offload_folder="offload")
# 或使用4位量化
model = AutoModel.from_pretrained(..., load_in_4bit=True)
```
3. **推理速度慢**:
- 使用 vLLM 或 Text Generation Inference (TGI)
- 启用连续批处理
- 使用 FlashAttention
### 五、部署建议
1. **使用 Docker 部署**:
```Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY . .
RUN pip install -r requirements.txt
CMD ["python", "app/main.py"]
```
2. **启动脚本**:
```bash
# 启动服务
python -m app.main \
--model_path /models/chatglm-6b \
--device cuda \
--precision int4
```
---
###








 超级会员免费看
超级会员免费看
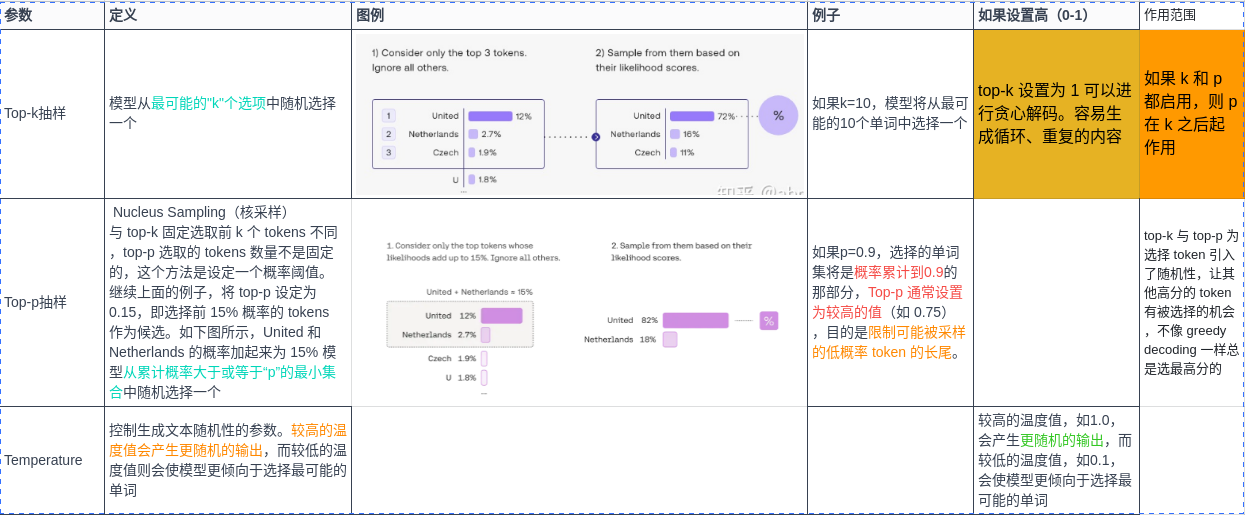
 文章介绍了LLM(大型语言模型)中的关键参数temperature、top-k和top-p的作用。temperature控制输出的随机性,temperature值越大,输出越随机;top-k从最可能的k个选项中随机选择,而top-p基于累计概率动态选择。这两种采样策略与greedydecoding相比,引入了更多的随机性,避免过度依赖最高概率的单词,优化了生成文本的多样性。
文章介绍了LLM(大型语言模型)中的关键参数temperature、top-k和top-p的作用。temperature控制输出的随机性,temperature值越大,输出越随机;top-k从最可能的k个选项中随机选择,而top-p基于累计概率动态选择。这两种采样策略与greedydecoding相比,引入了更多的随机性,避免过度依赖最高概率的单词,优化了生成文本的多样性。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











