









论文推荐|近端策略优化算法(PPO)
原创 韧性城市研究中心 浙江大学韧性城市研究中心 2024年05月21日 10:53 浙江
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov OpenAI

(论文链接:https://arxiv.org/abs/1707.06347)
近端策略优化算法(Proximal Policy Optimization Algorithms,PPO)是OpenAI于2017年提出的一种基于策略的强化算法,同时也是一种高效、稳定、强大的算法框架,具备为应急智能决策提供支撑的巨大潜力。
1
研究背景
随着深度学习的发展,许多学者提出了利用神经网络进行函数近似的强化学习优秀算法,如DQN、“vanilla”等。作者认为这些算法在处理大规模问题、数据利用效率、算法稳定性方面还有较大的改善空间。为此,作者对其本人曾提出的TRPO进行了改进,进而提出了PPO算法。
2
算法原理
PPO算法搭建在Actor-Critic框架上,其优化的重点是Actor网络,也就是更新策略梯度。通过利用重要性采样技术解决了传统策略梯度算法采样数据只能更新一次策略梯度的局限,提高了样本数据利用率,实现了算法由on-policy到off-policy的改进,其目标函数如图1中所示。
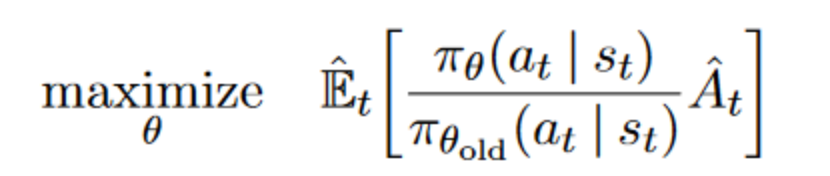
图1
为了在使用重要性采样时目标策略分布(图1中的分子)与样本策略分布(图1中的分母)差距不能太大,需要设置KL散度作为约束,作者将约束作为惩罚项建立目标函数,形成了TRPO算法,如图2公式所示。
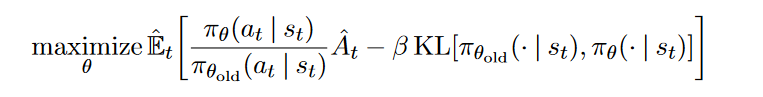
图2
但在实际运用中,作者发现惩罚项的系数β(超参数)是一个较难确定的值,在不同的环境中有不同的选择。对此作者提出了两种解决方案:
一是PPO-Penalty,通过设置目标散度dtarg的方式实现惩罚项的系数β的自适应,如图3所示。

图3
二是PPO-Clip,直接采取简单有效的方法进行约束——截断,即将比值限制在一个[1-ε,1+ε]的范围,如图4所示。
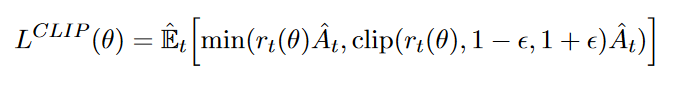
图4
在连续动作的策略优化实验中对比上述4种算法发现:PPO-Clip算法(ε=0.2)表现最优(具体对比结果如图5表格所示)。
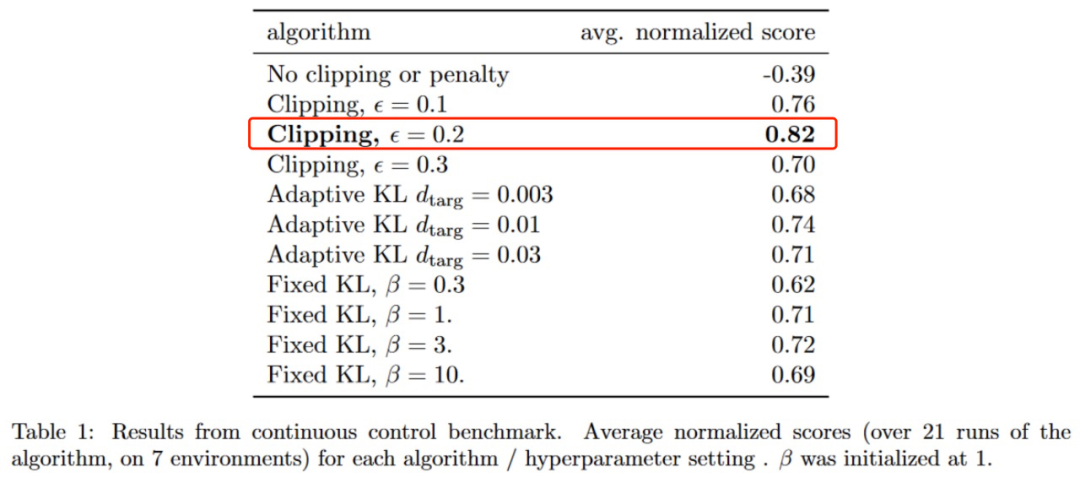
图5
3
结论
经过不断的优化迭代,PPO算法已经成为强化学习领域最主流的算法之一,相较于其他基于策略的强化学习算法,其在样本复杂度、简洁性和计算时间之间取得了很好的平衡(如图6所示,PPO-Clip在多个MuJoCo环境中都取得了较好的表现)。同时,为了检验算法在高维连续控制问题的表现,作者使用3D人形控制任务进行验证,该算法表现优异,为大规模应急智能决策的研究提供了有力可行方案。
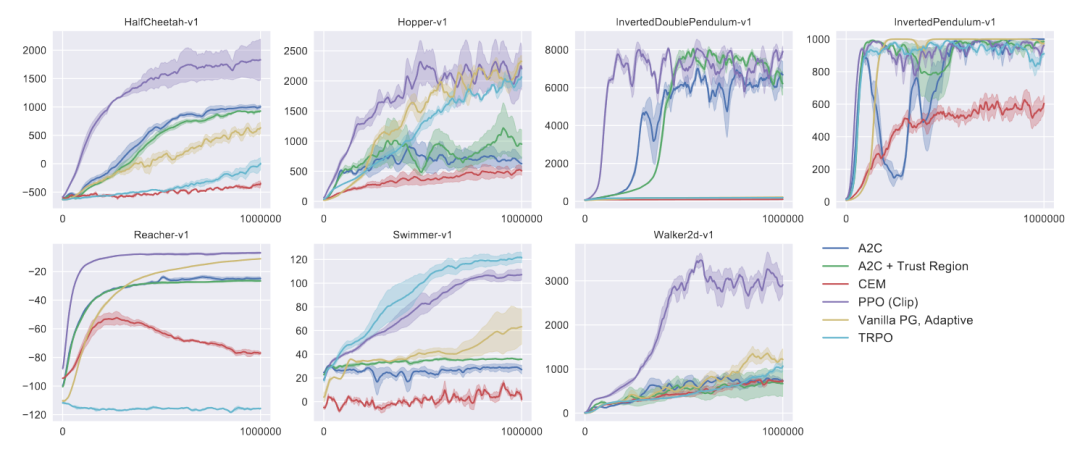
图6
引用格式:(GB/T 7714-2015)
SCHULMAN J, WOLSKI F, DHARIWAL P, 等. Proximal Policy Optimization Algorithms[M/OL]. arXiv, 2017[2024-04-07].
https://arxiv.org/abs/1707.06347
浙江大学韧性城市研究中心致力于探索各类自然灾害下我国城乡建成环境和经济社会之间的时空复杂关联机制以及应对策略,践行科学化、数字化、智慧化的城乡防灾减灾研究与实践。

联系我们
邮件:ren_city@zju.edu.cn
网址:http://www.rencity.zju.edu.cn
地址:浙江大学紫金港校区安中大楼B座515
文字:晏铁
校对:石祎林
排版:侯本鑫


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











