






不要做RAG,CAG足以应对所有知识任务!
原创 极客见识 GeekSavvy 2025年01月17日 17:10 广东
近年来,大语言模型(LLM)在基于知识的任务中取得了巨大进展,传统的检索增强生成(RAG)方法能够通过向大语言模型输入外部知识源,从而生成更好的答案,弥补了信息孤岛和信息时效性问题。
不过,RAG 也有弊端,就是受到信息检索延迟和选择错误的限制。康奈尔大学提出来一种新的方法,缓存增强生成 (CAG)。
康奈尔提出新方法 CAG
基于以后 LLM 在上下文窗口的显著提升情况下,康奈尔大学提出了一种替代范式,即绕过实时检索的缓存增强生成 (CAG)。
CAG 方法包括将所有相关资源(尤其是当用于检索的文档或知识的大小有限且可管理时)预加载到 LLM 的扩展上下文中,并缓存其运行时参数。在推理过程中,模型利用这些预加载的参数来回答查询,而无需额外的检索步骤。
比较分析表明,CAG 消除了检索延迟并最大限度地减少了检索错误,同时保持了上下文相关性。跨多个基准的性能评估突出了长上下文 LLM 优于传统 RAG 管道或补充传统 RAG 管道的场景。这些发现表明,对于某些应用程序,特别是那些知识库受限的应用程序,CAG 提供了一种简化且高效的 RAG 替代方案,以降低复杂性获得可比或卓越的结果。
现在,缓存增强生成(CAG) 能让具有长上下文窗口的模型预先加载所有信息。
01 CAG 的优势
-
更快的响应时间
-
降低错误风险
-
越来越简单的架构
02 CAG 理论
LLM 具有特定的上下文窗口。此窗口确定可以同时提供给模型的最大信息量。CAG 提前将所有必要的信息加载到上下文窗口中。因此,模型不需要在查询期间动态获取单独的信息源。
关键在于 Key-Value 键值 (KV) 缓存。
LLM 中的标准 KV 缓存
通常在 transformer 模型中,每个 input token 都通过自我注意机制与其他 token 相关联。
在此过程中:
-
Key: 表示标记含义的向量。它确定如何与其他标记关联。
-
Value:令牌中包含的信息向量。这是在响应生成期间考虑的“实际内容”。
比如:
“I eat an apple.”单词 'apple' 的键表示它如何适应句子中其他单词的上下文。该值带有单词 “apple” 的含义。
这种机制允许模型为每个 token 计算它与所有其他 token 的交互方式。这在处理长文本或经常需要相同信息时特别有用。
CAG 中的 KV 缓存略有不同
在 CAG 中,整个知识库作为 KV 缓存加载到模型中。也就是说,知识库中文档的所有 KV 值都是预先计算和存储的。
当查询传入时,模型会立即使用此缓存进行响应,而不是从外部系统获取信息。这可以防止对每个查询一遍又一遍地执行相同的计算。它还可以在查询之间创建一致的上下文。
这是因为存储在缓存中的信息将作为一个整体加载到模型的上下文窗口中。这提高了答案的准确性。
这种方式的优势:
-
减少时间损失
-
减少携带虚假文件的可能性
-
确保速度和效率
-
节省内存和处理能力
-
更一致的上下文工作
-
提供系统架构的简单性
这里的一个重要点就是硬件。在处理大型知识库时,GPU 内存和 RAM 至关重要。KV 缓存需要时间和处理能力来对知识库进行初始编码。但是,一旦完成此操作,就不需要重新计算。
03 RAG 与 CAG
RAG 方法独立于模型动态检索信息源,并在响应生成中使用此信息。但是,RAG 存在延迟、文档选择不正确和系统复杂性等缺点。
相反,CAG 通过将所有相关信息预加载到模型的扩展上下文窗口中,消除了实时信息检索的需要。

下表给出了研究人员用实验方法测试 RAG 和 CAG 之间差异的结果。实验结果表明,所提出的 CAG 方法与传统 RAG 系统之间存在明显差异。
CAG 通过提供更快、更准确的答案来胜过 RAG,尤其是在知识库大小有限的情况下。
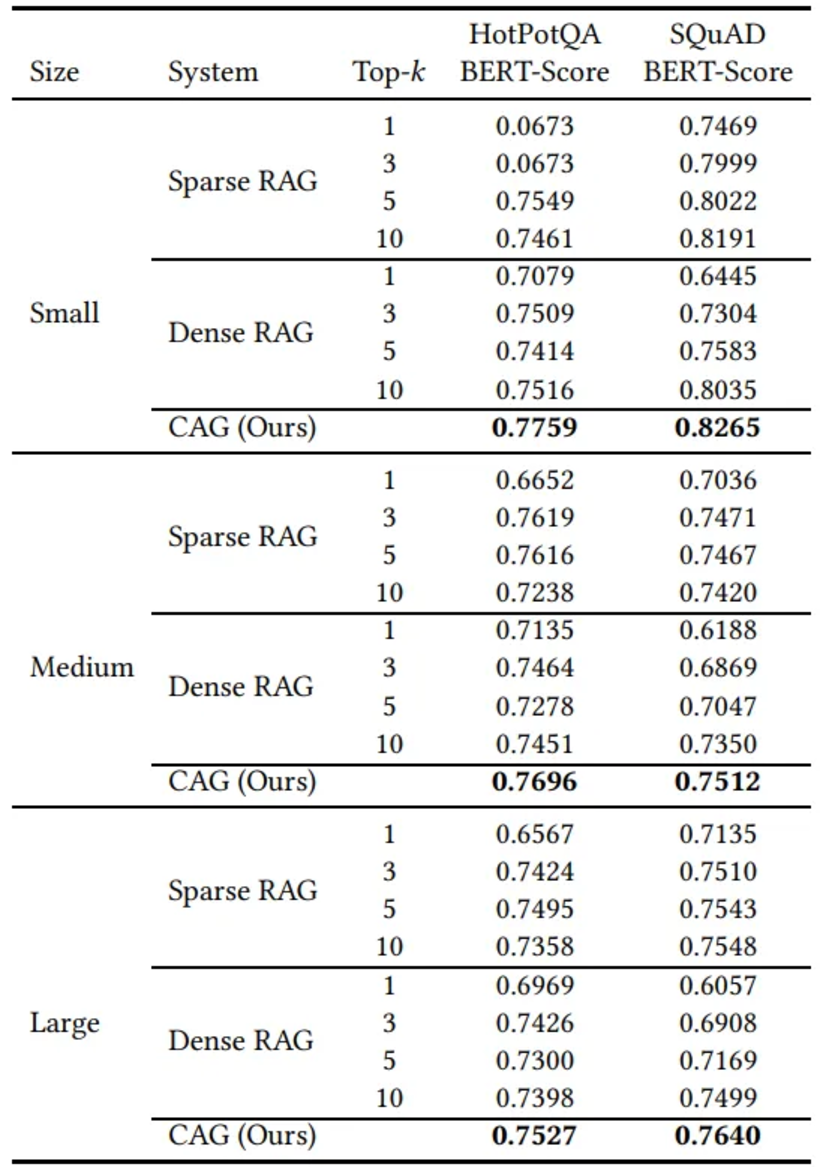
实验结果
04 CAG 可以在所有情况下使用吗
CAG 受模型上下文窗口大小的限制。假如,一个模型可以处理多达 128,000 tokens 的上下文,那么知识库就需要是这个规模。例如:
我们有 100 个文档,每个文档超过 150 页。
假设每页平均包含 300-500 tokens,则150页的文档大约有 45,000-75,000 个tokens。
对于 100 个文档,这意味着总共有 450 w - 750 w tokens。
但是,一个高达 450 w — 750 w tokens 的知识库:
-
无法一次缓存所有信息,因为它超出了上下文限制。这会导致内存问题。
-
KV 缓存的大小会增加内存消耗,这需要更大的 GPU/CPU 资源。
解决方案:
a. 分割与动态 CAG:
可以将知识库划分为更小、易于管理的子组。例如,让每个子组包含 10 份文档(约 450,000 - 750,000 tkoens)。
根据用户查询的范围,只预加载相关的子组。
b. 混合方法(CAG + RAG)
可以缓存基本的知识库,并使用 CAG 加载常用信息。
对于不常用或边缘情况,可以使用 RAG 进行实时检索。
混合模型兼具高速度和灵活性。
c. 预筛选或过滤
如果你的查询经常集中在文档的特定部分,可以设计一个预筛选机制,只加载那些部分。
例如,当收到用户查询时,可以使用快速分类器来确定相关的文档或部分。
d. 更大的模型和资源
如果有技术手段,可以使用支持更长上下文窗口的模型或专门的基础设施(例如,使用多个 GPU 进行并行上下文处理)。
结论
实验证明,CAG 的性能优于 RAG,尤其是在知识库大小可控的情况下。未来,随着模型的上下文窗口容量的增加,CAG 的使用可能会进一步扩展。
如果我们需要为知识密集型任务寻找更快、更准确、更轻松的解决方案,CAG 可能更好的选择。
论文地址:
https://arxiv.org/abs/2412.15605v1


















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











