







个性化大语言模型LLM的最全综述
原创 方方不吃糖 方方的算法花园 2025年01月09日 09:42 北京
点击蓝字关注我们
写在前面
1. 论文标题:《Personalization of Large Language Models: A Survey》
个性化LLM:综述
2. 论文链接:https://arxiv.org/pdf/2411.00027
3. 作者所在机构:Dartmouth College、Adobe Research、Stanford University、University of Massachusetts Amherst、Pattern Data、Vanderbilt University、 Dolby Research、 University of California San Diego、Cisco Research、University of Oregon
4.一句话概括该论文:论文通过提出个性化大语言模型(LLM)使用的分类法,总结关键差异和挑战,对个性化 LLM 进行了形式化定义,统一了不同领域的文献,涵盖个性化粒度、技术、数据集、评估方法和应用等方面,并指出了未来研究面临的挑战和问题,为相关研究和实践提供了全面指导。
Part.01
背景
将 LLMs 适应于用户特定背景的个性化需求日益增长。个性化可使模型生成符合用户或用户群体独特需求和偏好的响应,在客户支持、教育、医疗等领域至关重要,能提高用户满意度,增强应用效果。
现有关于个性化 LLMs 的研究主要分为个性化文本生成和在下游个性化任务中的应用两类,且各自独立发展,缺乏统一视角。该论文通过提出分类法统一不同领域文献,包括对个性化 LLM 使用的分类、形式化定义、个性化粒度、技术、评估、数据集和应用的分类分析,还指出了未来研究面临的挑战和问题,为研究人员和从业者提供全面指导。
Part.02
LLM个性化-工作分类
论文提出了一个直观的分类法将个性化的LLM工作分为两个主要类别:直接个性化文本生成和间接下游任务个性化。
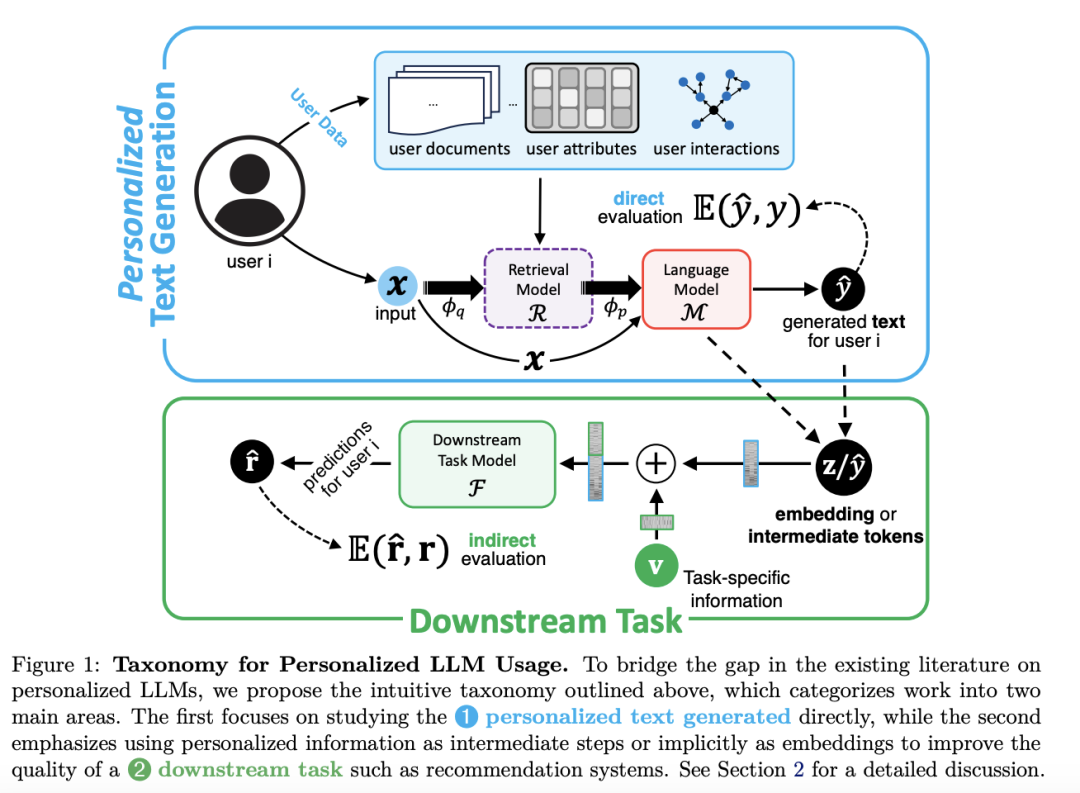
1. 直接个性化文本生成(personalized text generated)
在个性化文本生成中,目标是直接生成与个人或群体偏好一致的文本,如个性化心理健康聊天机器人需根据用户之前的对话生成共情回应,通过人类评估或基于文本的指标(如 ROUGE 等)直接评估生成文本的质量,将其与用户实际书写的真实文本进行对比。
以基于检索增强生成(RAG)的框架为例说明。对于用户 i,结合用户文档、属性、交互等信息,通过查询生成函数和检索模型获取与用户相关的 top-k 数据,再利用个性化提示生成函数将其与用户输入文本组合成个性化输入,最后由 LLM 生成个性化文本。部分研究专注于生成此类文本并与用户真实文本对比评估,但由于高质量用户标注数据集稀缺,该研究方向关注度有限,更多研究倾向于间接利用个性化文本来改进下游任务。
2. 间接下游任务个性化(downstream task)
下游任务个性化则是利用个性化信息作为中间步骤或隐式嵌入来改进下游任务(如推荐系统)的质量,例如 LLM 增强的电影推荐系统通过分析用户观看历史等生成中间token或embedding,以提升推荐性能,其性能通过推荐准确性等特定任务指标评估,重点在于改进任务结果而非文本生成过程。
许多工作致力于利用个性化文本或其embedding来增强下游任务,如推荐任务。通常将用户特定embedding或中间文本与其他任务相关信息结合,形成统一表示后输入下游任务模型,从而产生预测结果。
虽然直接文本生成和下游任务个性化看似不同,但它们共享一些组件和机制,如都涉及用户数据检索与利用、构建个性化元素以增强模型输出等,只是在数据集和评估方法上有所区别,且两者可相互补充,共同推动个性化 LLM 的发展。
Part.03
LLM个性化-理论基础
个性化的定义
个性化是指根据用户特定的数据、历史交互以及上下文信息来调整 LLMs 的输出,使得输出能够满足用户个体或者特定用户群体的偏好、需求以及特征。这种调整的目的是提升用户满意度并且增强内容与用户的相关性。
1. 用户偏好(User Preferences):用户偏好包含用户在内容风格、主题、语气等诸多方面的喜好。通过捕捉和利用用户偏好,LLMs 可以生成更贴合用户需求的输出。
2. 个性化大语言模型(Personalized LLMs):经过个性化调整后的 LLMs。这种调整可以通过多种方式实现,比如在预训练模型的基础上,利用用户特定的数据进行微调,或者在生成过程中动态地结合用户信息。
3. 用户文档(User Documents):用户自己创作的各种文本,如笔记、评论、博客文章等。这些用户文档蕴含了丰富的用户信息,例如用户的知识领域、观点、写作风格等。例如,从用户的学术笔记中可以了解到用户的专业领域,从用户的影评中可以推断出用户对电影类型的偏好。
4. 用户属性(User Attributes):用户相对稳定的特征,如年龄、性别、地理位置、职业等。这些属性可以为个性化提供长期的参考。例如,根据用户的地理位置,可以为其推荐当地的新闻或者活动;根据用户的职业,可能为其提供相关行业的资讯。
5. 用户交互(User Interactions):主要包括用户与 LLMs 之间的对话、用户对推荐内容的反馈(如点击、点赞、评论等)等。这些交互记录是动态的,能够实时反映用户的兴趣变化。例如,在对话过程中,用户对某个话题表现出浓厚的兴趣,那么后续的输出就可以更多地围绕这个话题展开。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











