







一起来看看最新的对话状态追踪(DST)模型
任务型对话的模型分为端到端和pipeline两种结构。端到端结构主要使用seq2seq模型。Pipeline结构定义数个模块,分别是语音识别(ASR)、自然语言理解(NLU)、对话管理器(DM)、自然语言生成(NLG)、语音合成(TTS)。NLU→DM→NLG是整个pipeline对话结构中最重要的部分。概括来讲,NLU负责对用户输入进行理解,随后进入DM模块,负责系统状态的追踪以及对话策略的学习,控制系统的下一步动作,而NLG则配合系统将要采取的动作生成合适的对话反馈给用户。
Pipeline结构中的DM模块细分为DST和DPL。DST(对话状态追踪 Dialog State Tracking),负责维护对话系统状态(各个槽对应的值以及相应的概率),并根据当前轮对话更新对话状态。而对话策略DPL根据DST输出的当前系统状态来判断还有哪些槽需要被问及,去生成下一步的系统动作。下图给出一个DST的具体例子,方便读者有个直观的了解。
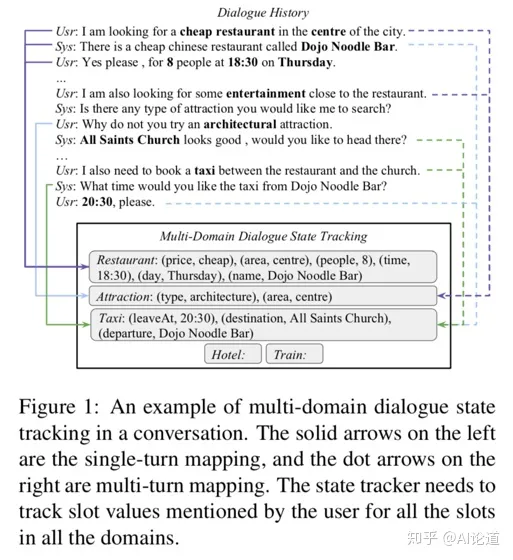
下面我们介绍三篇对话状态追踪的相关论文,分别可以概括为检索式、生成式、生成检索结合,从而了解当前主流的DST模型。
01检索式
SUMBT: Slot-Utterance Matchingfor Universal and Scalable Belief Tracking
论文地址: https://arxiv.org/abs/1907.07421
过去的方法,存在两个问题:
1)domain和slot分开建模,
2)实际场景中出现新的value值时,很难预测。本文将domain和slot一起编码,通过bert学习context和槽值对的内在联系,从而建立一个高效轻便的检索式模型。
具体算法如下:
1)Bert对context,某个domain-slot以及其对应的所有value取值集合分别进行encode,均取encode输出的[CLS]对应位置为隐层表示。
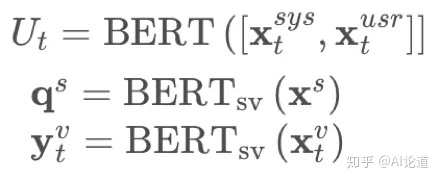
2)d作为距离度量指标,用来判断domain-slot对应值是否为当前value,文中使用欧式距离和负向余弦距离(negative cosine distance)来计算。
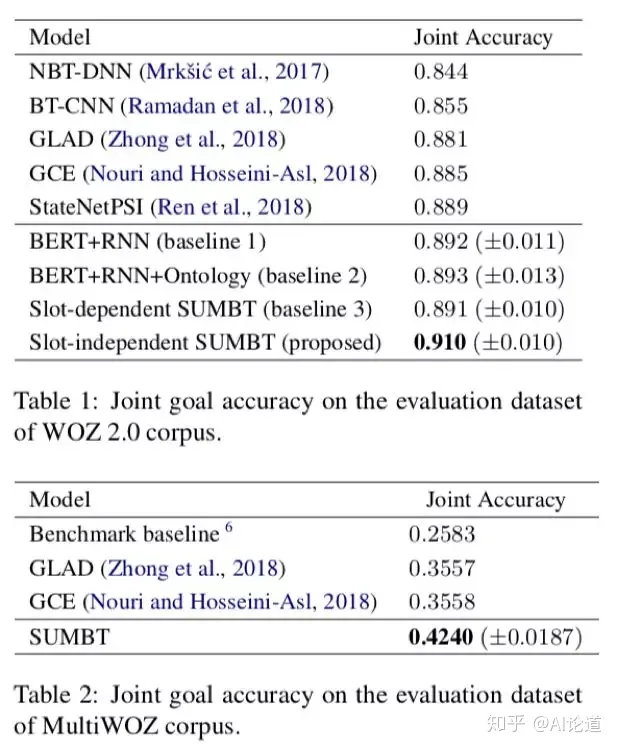
实验结果如下:
02生成式
Efficient Dialogue State Tracking by Selectively Overwriting Memory
论文地址: https://arxiv.org/abs/1911.03906
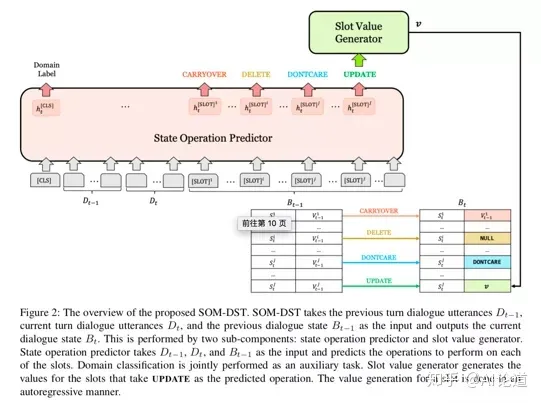
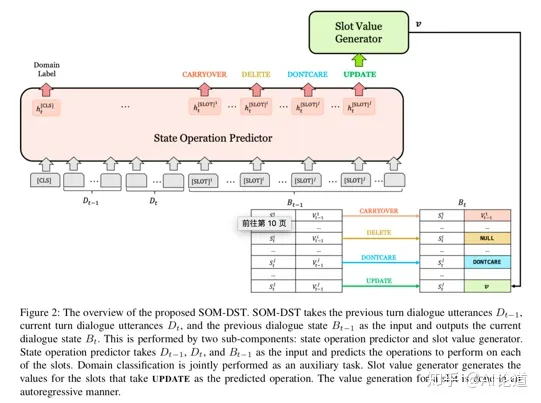
过去的方法,每轮DST预测时,都需要重新输入已发生对话的所有语句,效率较低。本篇论文维护一个状态追踪表,并提出一个选择性重写机制。算法过程可以概括为:
1)预测每个槽值对的状态操作,
2)对需要更新的槽值对进行重写。
状态操作(state operation)分为4类:CARRYOVER, DELETE, DONTCARE, UPDATE。CARRYOVER表示某个槽值对不变,剩余三个操作分别表示: 删除为NULL、槽值对未提及、槽值对更新。模型输入上轮回答、当前问句、上轮对话状态,只有当某个槽值对的状态操作为UPDATE时,模型生成对应的更新值。
具体算法如下:
1)状态操作算法:
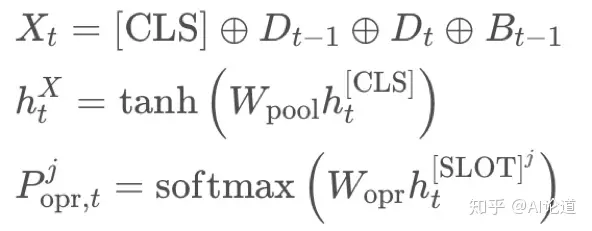
通过bert进行信息编码,输出的首位表示为domain信息,之后为各槽值对的状态操作预测值。
2)槽值对生成算法:
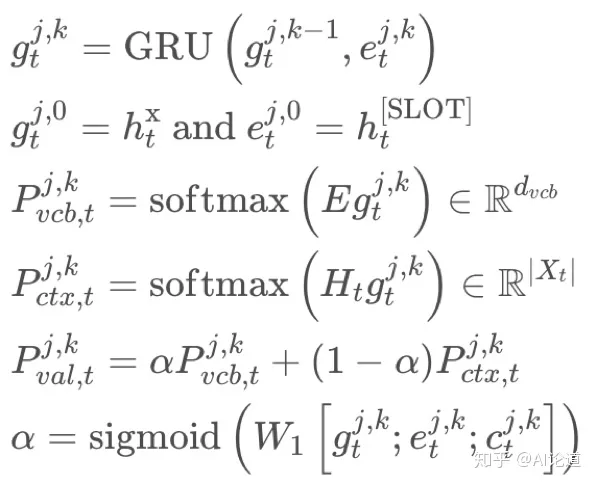
实验结果如下:
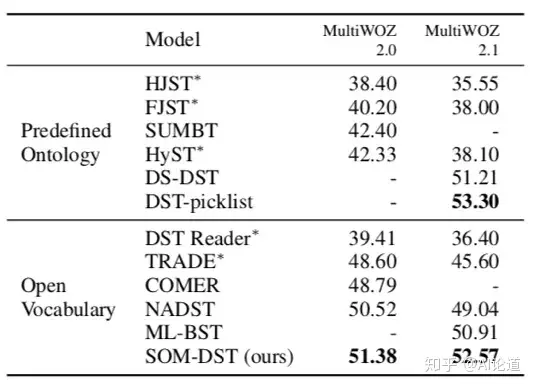
03检索生成结合
Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking
论文地址: https://arxiv.org/abs/1910.03544
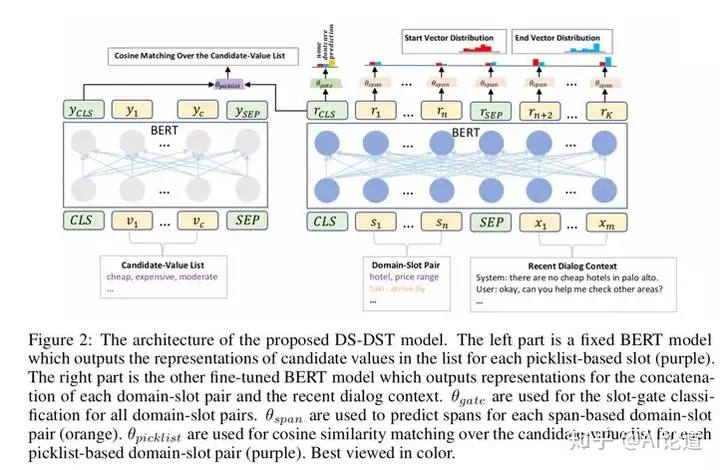
目前DST大致分为两类,检索式(picklist-based)和生成式(span-based)。
检索式方法预定一个所有可能的槽值候选集,使用分类方法确定某个slot对应的value取值。生成式方法中,通过对context进行深度建模分析,找出语句中的value值。两种方法各有利弊,检索式方法高效不易错,但实际应用中构建完整的槽值候选集有较大的难度。生成式方法灵活且不受候选集依赖,但特定value(例如时间地点)较难抽取。
本文将两种方法结合,把所有slots分成两类,对于picklist-based slots使用predefined ontology-based approach,类似上文中的SUMBT ;而对于span-based slots, 使用span extraction-based method,找出某slot的对应value在context中的起止、终止位置。
具体算法如下:
1)Bert编码输入context和domain-slot:
![]()
2)通过slot-gate分类算法判断一个domain-slot是否需要进行状态更新。(一个domain-lost可能对应的所有状态值,none, dontcare, prediction):
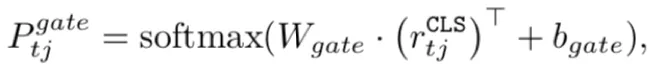
3)对于span-based slots:
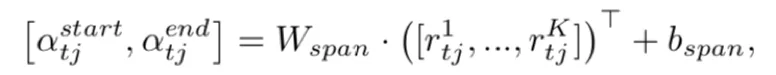
4)对于picklist-based slots:
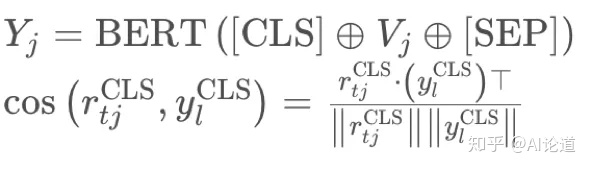
训练时,将2)、3)、4)的loss函数相加作为模型loss。
论文在实验部分详细讨论两类slots的区分方式。比如Threshold-10表示candidate-value lists的长度少于10则划入picklist-based slots,否则划入span-based slots。然而实验表明,基于人工启发法进行区分时,模型性能更好。人工启发法是指把time和number这两种槽位划入span-based slots。
实验结果如下:

“A


















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











