







大模型国产化适配10-快速迁移大模型到昇腾910B保姆级教程(Pytorch版)
原创 吃果冻不吐果冻皮 吃果冻不吐果冻皮 2024年07月02日 09:01 四川
随着 ChatGPT 的现象级走红,引领了AI大模型时代的变革,从而导致 AI 算力日益紧缺。与此同时,中美贸易战以及美国对华进行AI芯片相关的制裁导致 AI 算力的国产化适配势在必行。之前也分享过一些国产 AI 芯片、使用国产 AI 框架 Mindformers 基于昇腾910训练大模型,使用 MindIE 进行大模型服务化。
另外,我撰写的大模型相关的博客及配套代码均整理放置在Github:llm-action,有需要的朋友自取。
而本文将讲述如何快速迁移大模型到昇腾910B,相信很多人入门大模型都是从斯坦福羊驼开始,本文将使用羊驼的训练代码和训练数据集快速将baichuan2-7B/13B、qwen1.5-7B/14B大模型在昇腾910B上面进行训练。之前的文章讲过 从0到1复现斯坦福羊驼(Stanford Alpaca 7B),本文不再赘述,斯坦福羊驼的整体思路如下图所示。
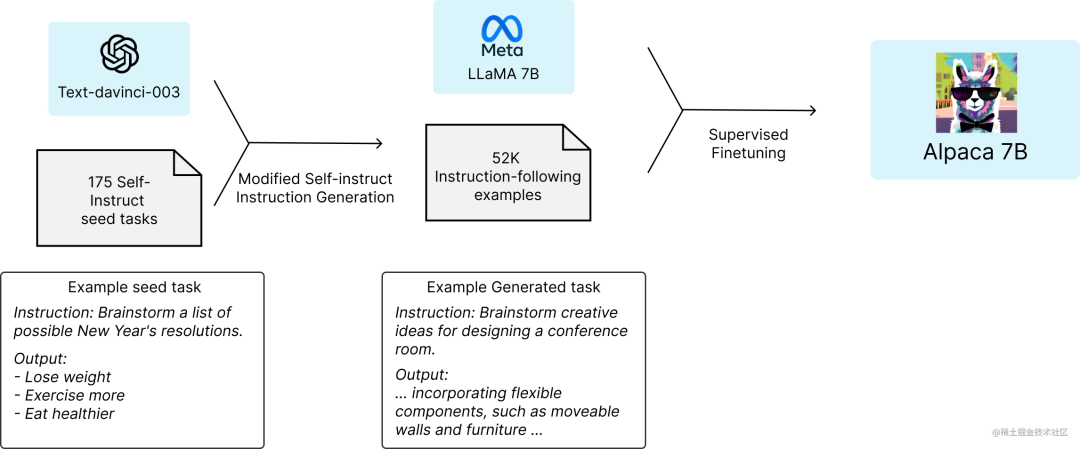
image.png
声明:本次只做训练流程上面的验证,不做loss精度的对齐,不同模型训练的细微差异需视具体情况进行调整。
准备工作
-
操作系统版本/架构:EulerOS 2.0 (SP10)/aarch64
-
NPU:8x 910B 64G
-
Python:3.9
-
NPU 驱动:24.1.rc1,下载
-
NPU 固件:7.1.0.6.220,下载
-
CANN 工具包:7.0.0,下载
-
Pytorch及torch_npu插件:2.1.0,下载
-
Docker镜像环境:ascend-mindspore:23.0.0-A2-ubuntu18.04 ,下载
-
DeepSpeed:0.14.1, 下载
查询所有设备的基本信息。
> npu-smi info
+------------------------------------------------------------------------------------------------+
| npu-smi 24.1.rc1 Version: 24.1.rc1 |
+---------------------------+---------------+----------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) Hugepages-Usage(page)|
| Chip | Bus-Id | AICore(%) Memory-Usage(MB) HBM-Usage(MB) |
+===========================+===============+====================================================+
| 0 910B1 | OK | 95.7 36 0 / 0 |
| 0 | 0000:C1:00.0 | 0 0 / 0 3306 / 65536 |
+===========================+===============+=================================================&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1992
1992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











