






R1复现:拒绝采样微调加速RL收敛及模型遗忘问题探究
原创 战士金 炼钢AI 2025年03月10日 10:06 北京
前言
上学时候做过一段时间强化学习(非LLM强化学习,而是和环境交互的经典深度强化学习),我导当时还想让我把强化学习当作毕业课题,被我婉言拒绝了,因为真的是太太太难做了。和LLM强化学习相比,经典深度强化学习,尤其是有实际应用场景而不是简单的玩2D游戏的任务,收敛会难很多,你还需要对实际场景有深入的洞察,设计中间过程奖励函数(纯靠模型探索几乎不可能拿到最后任务完成的奖励)。一顿操作下来就会发现,模型真聪明啊,hack reward技术一流......
进入到LLM时代,就没咋再做过强化学习了,LLM初期阶段,强化学习通常是作为对齐人类价值观的一种手段,对模型能力提升有限,笔者对这貌似并不是很感兴趣。直到Deepseek-R1爆火,才打算重新捡起强化学习这块东西。
我的最终目标是借助强化学习技术,提升此前开源的 Steel-LLM 的数学运算能力。Steel-LLM模型比较小,数据里代码/数学数据又不多,之前测gsm8k只有惨淡的个位数分值。。。直接拿来强化学习必然拿不到啥好的效果。开始打算的先增强一波Steel-LLM的数序能力再做强化学习,但是这样的话拿到强化学习相关结论的周期有点长。因此先打算在Qwen2.5-1.5B-Instruct上做一些实验,拿到一些在小模型上的结论与认知。所有实验代码已上传到Steel-LLM仓库的r1/ablation_gsm8k目录下:
https://github.com/zhanshijinwat/Steel-LLM实验
在讲解实验结果前先声明一下,在1.5B模型上得到的结论不一定能泛化到更大/更小的模型上,同时任务难度也会影响实验结论(但我觉的大部分实验结论还是能迁移的)。
1
实验设置
-
主要是在gsm8k的训练集上训练,然后在gsm8k测试集上评估。同时,也会在非数学benchmark(mmlu/ceval)上进行评估,考察模型对于其他任务的遗忘情况。
-
训练框架使用的是字节开源的VeRL,VeRL提供了gsm8k的reward函数(答对为0答错为1)。需要注意的是,调用哪个奖励函数是根据你处理数据里边的data_source字段决定的,看下VeRL项目的verl/utils/reward_score/__init__.py目录,就会发现默认只有data_source设置为openai/gsm8k时,才会调用gsm8k的奖励函数,data_source不能随便填或者改下代码也行。
-
在做评估时,会评估若干个训练step的checkpoint,避免模型训练过拟合/欠拟影响实验结论。
-
SFT和RL统一使用如下prompt:
"{query} Let's think step by step and output the final answer after \"####\"."其实没必要非得按照R1那样用把思维过程包裹起来,因为也没打算提取思维过程。而且instruct模型本身也能遵循在####后输出答案的指令,也没设置格式奖励。没有必要的话尽量不要限制模型自由发挥。
2
太长不看版
开头先给出一些实验结论/推论:
-
未微调的Qwen2.5-1.5B-Instruct本身就有一定的COT能力,不只是在做数学题时,通用问题上也会出现。
-
直接只用开源数学题数据进行SFT很容易让模型能力全面降低。
-
在gsm8k上对模型进行RL训练,不仅准确率能稳定上升,其他通用能力也不容易下降。GRPO增大rollout num有一定收益。
-
拒绝采样微调可视为一种能够加快RL收敛的方式。
-
仅有数学数据的拒绝采样微调并不会把模型训崩。
-
对同样数据的多阶段拒绝采样微调+RL用处不大,可能是因为后边阶段拒绝采样时数据多样性会下降。
-
网红微调数据集在小模型上不work,微调步数少了模型很容易停不下来。
3
baseline1:未微调的Qwen2.5-1.5B-Inst
先直接测一波没经过sft/rl训练过的qwen2.5-1.5B能力。
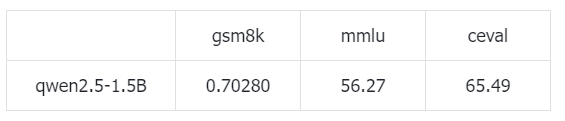
翻了一下推理gsm8k的结果,不微调的模型已经有比较好的COT能力了。笔者还发现在回答中文通用问题时候(ceval)模型更倾向于直接给出答案,回答英文通用(mmlu)时则更倾向于先给出一段解释,最后在给出答案。猜测可能是在同语言下COT能力更容易泛化?
4
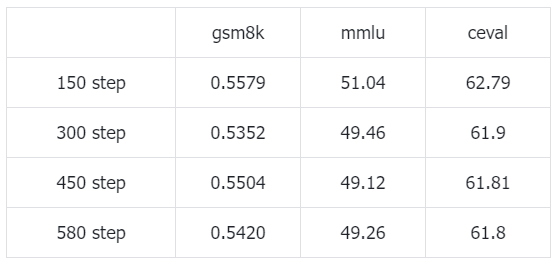
实验2:baseline2:在gsm8k训练集上sft
直接在gsm8k训练集上训练10个epoch,可以发现不管是数学能力还是非数学能力都不如微调前的模型。这是因为sft阶段只有数学数据,和源模型的训练数据分布差异太大了,导致遗忘严重。数学能力下降的是最多的(0.70->0.55),大概也能说明单纯微调数学任务比通用任务相对难些,sft数据配比还是十分重要的。《How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition》这篇文章提到SFT时数学能力会随着数学数据量的增大而提升,但是他也是糅合着通用数据训练的而且最小的模型也有7B。小模型用纯的数学数据sft性能会全面劣化。
5
GRPO训练:rollout num=8 vs 16
GRPO对于每个query都会采样出若干个(rollout num)答案,然后取均值当作baseline,如果算力允许,rollout多一些会比较好,一是sample出正确答案的概率会大一些,二是归一化reward时候的均值/标准差会更准,从实验结果中也能看出rollout num多一点会更好。和实验2直接SFT模型相比,gsm8k指标稳定提升,更重要的是在非数学的mmlu/ceval benchmark上几乎没有遗忘的问题。RL训练和SFT相比是一种更“柔和”的后训练方式,并不要求模型去强置拟合答案,遗忘自然会少一些。那之后如果模型想刷榜,是不是可以先暂时少关心数学/代码能力,猛猛提升一波通用benchmark指标,最后再用RL增强数学/代码能力?
(评估mmlu的时间太久,后边就没测mmlu了,只从ceval也能反映出对于通用能力的遗忘程度)
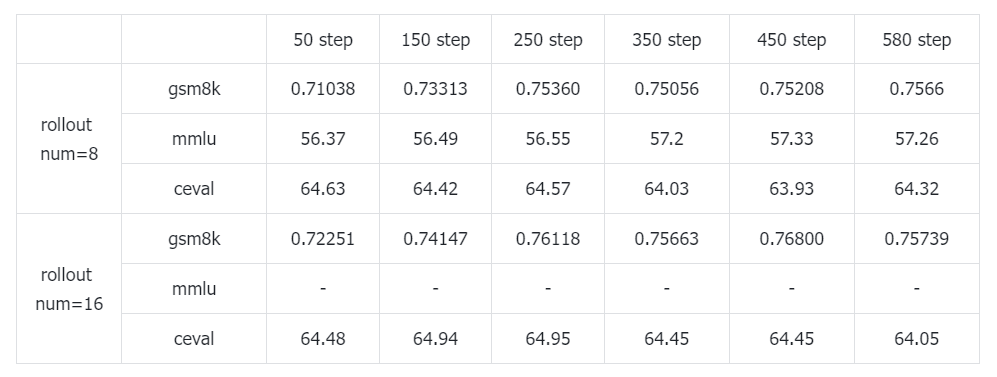
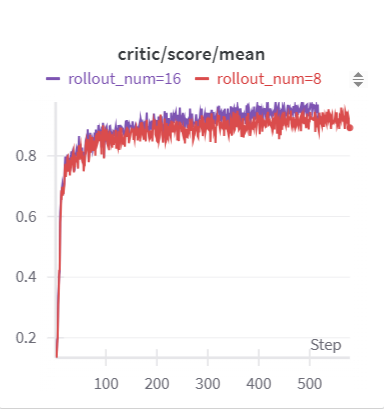
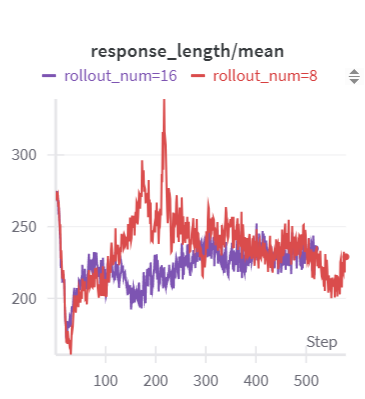
给出rollout num=8/16情况的reward变化曲线,rollout num=16 能拿到更高的训练集reward分值(roll num=16最多平均94%正确率,roll num=8最多平均92%正确率):
回答长度和其他博主复现的情况一样,也有一个先短后长的过程。回答变短的过程个人理解是在变换回答风格,变长是在增加思考提高回答质量。gsm8k任务比较简单,回答长度增长速度还是比较快的,训练100个step以后就不咋大涨了,题容易也没必要思考特别多。
6
实验4:拒绝采样微调
使用实验3中rollout=16情况下强化学习训练出来的模型对gsm8k训练集问题进行推理,每个问题rollout 5个答案,使用math_verify过滤掉回答错误的QA对,最终得到35497条样本(一共rollout了37865次)。然后用这些带解题过程的数据对原始的Qwen2.5-1.5B-Instruct进行SFT(其实就是deepseek-r1类似的操作,用deepseek-zero rollout出来的样本,对deepseek-base进行SFT)。
我们可以发现,使用实验3模型(Qwen2.5-1.5B-Instruct+RL)rollout出来的数据去微调Qwen2.5-1.5B-Instruct(注意,微调对象是没有经过RL训练的)并没有让模型训崩,而且能得到和RL训练出来的模型一样好的gsm8k分数!反观实验2(直接用原始gsm8k数据微调)gsm8k分数全面崩溃,说明并不是SFT不行,而是数据不行。rollout出来的数据分布更符合Qwen2.5-1.5B-Instruct的内在分布,因此能训出来更好的结果。我理解用别的模型rollout出来的数据(比如从deepseek-r1蒸馏出来的数据)去微调Qwen2.5-1.5B-Instruct,未必能拿到同样高的分数。虽SFT的gsm8k分数能和RL的gsm8k分数持平,但是ceval分值确是逐渐降低的,说明对训练任务以外的任务遗忘情况不是很友好(RL不存在这个问题)。
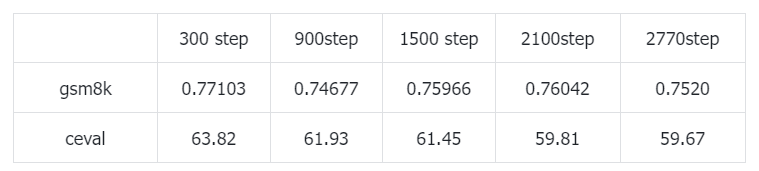
还有一个现象值得分享,rollout出来数据在SFT时初始loss比原始gsm8k训练集loss要低很多。进一步能说明RL的过程对原始模型内在分布影响不大,泛化性更强。
使用rollout数据做sft第10、20、30、40、50个step的loss:
0.1316->0.091->0.093->0.0899->0.0888使用gsm8k原始训练数据做sft第10、20、30、40、50个step的loss:
0.4255->0.3635->0.3548->0.3492->0.34457
实验5:基于实验4 SFT后的模型做RL
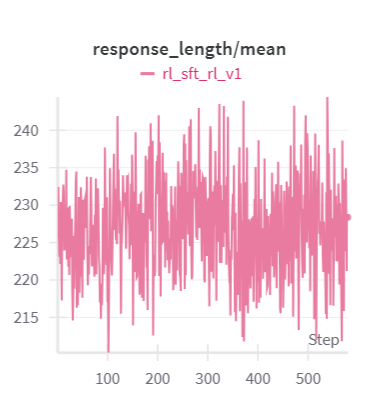
参考deepseek-R1的训练流程,顺理成章的就尝试一下在实验4 SFT出来的模型基础上进一步做RL(roll num=16)。可以发现和实验3的模型(直接在原始qwen模型上做RL,最多有76.8%的正确率)相比,gsm8k能够达到更高的分数,并且训练初期分数就比较高了。能否理解为使用自蒸馏的数据做SFT是一种加速RL收敛的方法呢?举个例子,假设我们在基础模型上单纯使用一阶段RL需要训练1000个step拿到测试集上90%的正确率,但是使用1阶段RL训练500个step+自蒸馏数据SFT+2阶段RL训练100个step也能拿到90%的正确率。SFT的训练效率可是比RL训练效率高多了。
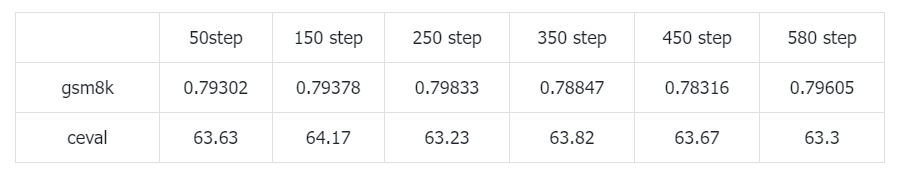
查看reward曲线,训练初期就能拿到90%+的正确率,通过SFT的方式完美继承了之前在RL上的作题能力。并且随着训练还能够进一步提高reward分值。
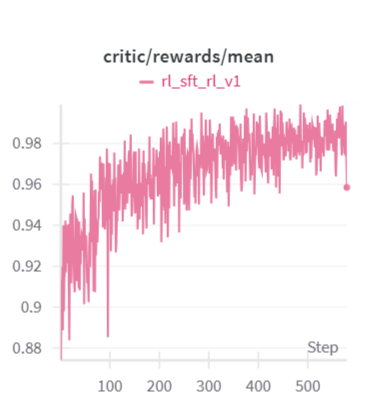
回答长度上也继承了上一阶段RL的结果。
8
实验6:二阶段进行拒绝采样微调->RL
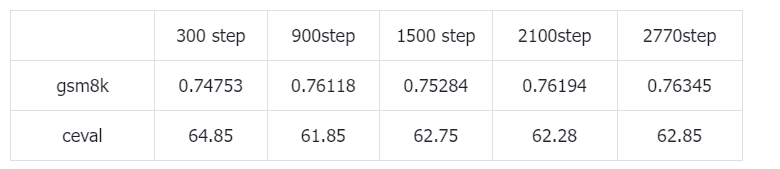
借鉴deepseek-R1的思路,进行二阶段的拒绝采样微调+RL,拒绝采样的模型为实验5进行强化学习之后的模型。微调对象是原始的Qwen2.5-1.5B-Instruct。可以发现模型效果没有一阶段拒绝采样微调+RL好,可能是因为实验5产出的模型训练的步数比较多之后,采样出来的数据多样性比较差给SFT带来了负面影响。张俊林老师之前的文章提到,有个可能是更多阶段的拒绝采样微调+RL能不断提高产出COT数据的质量。但实际上可能是后边阶段拒绝采样时多样性不断降低,模型效果也不会再提高。RL的上限还是要看预训练的水平的。
二阶段拒绝采样微调后的结果:
二阶段强化学习后的结果:

9
实验7:使用网红数据集进行微调
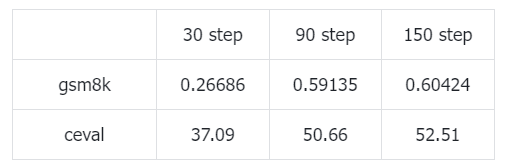
s1、LIMO等数据集之前也火了一把,用少量的高质量SFT也能激发模型的复杂推理。我也在1.5B的小模型上微调LIMO试了下,共计30个epoch。可以看到微调初期效果极差。原因是1.5B的模型训练少量step后,进行推理时很难在推理时停下来,车轱辘话来回说,虽然微调的是数学数据集,但是在ceval上也会有这种现象。随着训练步数增加才有所缓解,最后也没能恢复到未微调时候的水平。
后续会尝试一些在通用能力上的提升实验。


















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











