






LLM 研究精选:从MOE混合专家到DPO近端策略优化,2024 年值得关注的 AI 论文

今天分享来自 Sebastian 博士整理的 2024 年值得关注的 AI 研究论文,它涵盖了各种主题,从混合专家模型到 LLM Scaling Laws 定律。
在本文中,将分享我认为有趣、有影响力或两者兼而有之的研究论文。本文只是第一部分,重点关注 2024 年上半年,即 1 月至 6 月。第二部分涵盖 7 月至 12 月,将于 1 月晚些时候分享。

2024年LLM论文列表
Sebastian 博士团队开源了《构建大型语言模型(从头开始) 》一书,包含开发、预训练和微调类似 GPT 的 LLM 的代码,官方代码仓库:
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code>官方仓库:<span style="color:#dd1144">https:</span>/<span style="color:#ca7d37">/github.com/rasbt/LLMs-from-scratch</span></code><code>百篇论文列表:https:/<span style="color:#ca7d37">/magazine.sebastianraschka.com/p/llm-research-papers-the-2024-list</span></code></span></span>1. 一月:Mixtral 的专家混合方法
2024 年 1 月仅几天,Mistral AI 团队就分享了Mixtral of Experts论文(2024 年 1 月 8 日),其中描述了 Mixtral 8x7B,一种稀疏混合专家 (SMoE) 模型,它在各种基准测试中都优于 Llama 2 70B 和 GPT-3.5。
1.1 理解 MoE 模型
MoE(即混合专家)是一种集成模型,它将几个较小的“专家”子网络组合在类似 GPT 的解码器架构中。据说每个子网络负责处理不同类型的任务,或者更具体地说,处理 token。这里的理念是,通过使用多个较小的子网络而不是一个大型网络,MoE 旨在更有效地分配计算资源。
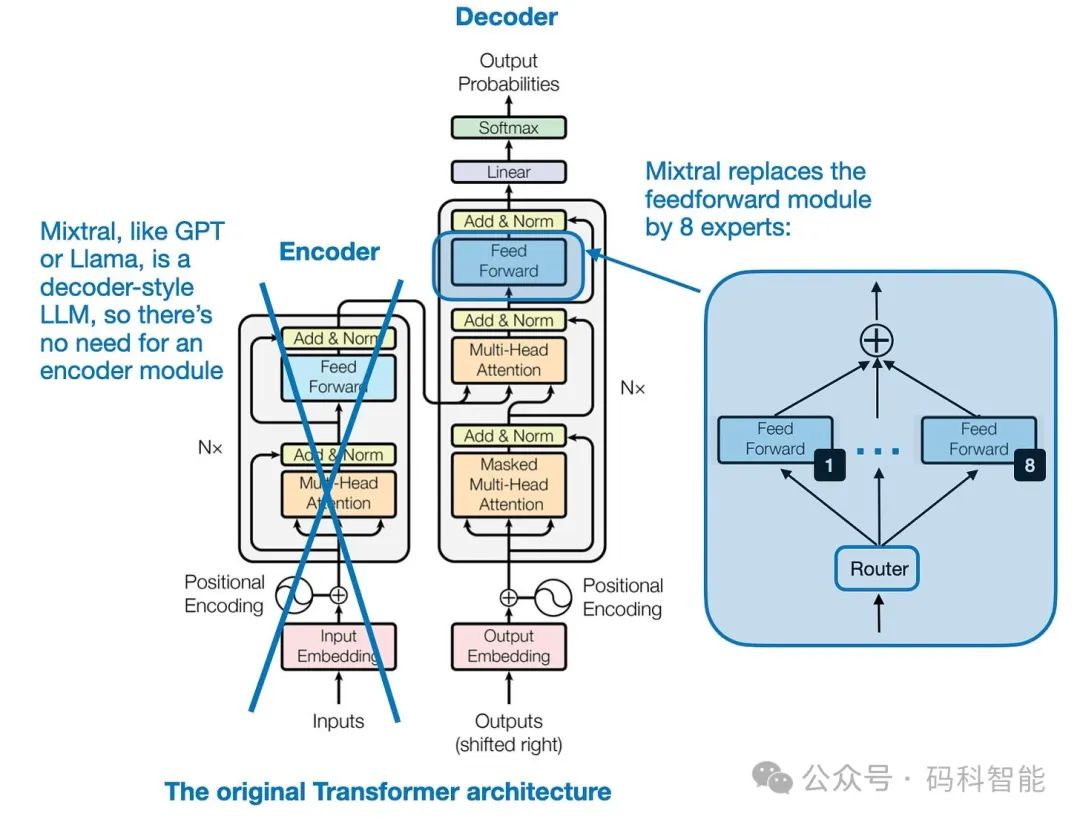
如上图所示,在 Mixtral 8x7B 中,用 8 个专家层替换Transformer架构中的每个前馈模块,子网络取代了 LLM 中的前馈模块。前馈模块本质上是一个多层感知器。在类似 PyTorch 的伪代码中,它基本上看起来像这样:
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code><span style="color:#ca7d37">class</span> <span style="color:#dd1144">FeedForward</span>(torch.nn.<span style="color:#dd1144">Module</span>): </code><code> <span style="color:#ca7d37">def</span> <span style="color:#dd1144">__init__</span>(<span style="color:#0e9ce5">self</span>, embed_dim, coef): </code><code> <span style="color:#0e9ce5">super</span>().__init__() </code><code> <span style="color:#0e9ce5">self</span>.layers = nn.<span style="color:#dd1144">Sequential</span>( </code><code> torch.nn.<span style="color:#dd1144">Linear</span>(embed_dim, coef*embed_dim),</code><code> torch.nn.<span style="color:#dd1144">Re</span>LU(), </code><code> torch.nn.<span style="color:#dd1144">Linear</span>(coef*n_embed, embed_dim),</code><code> torch.nn.<span style="color:#dd1144">Dropout</span>(dropout)</code><code> )</code><code> </code><code> <span style="color:#ca7d37">def</span> <span style="color:#dd1144">forward</span>(<span style="color:#0e9ce5">self</span>, x): </code><code> <span style="color:#ca7d37">return</span> <span style="color:#0e9ce5">self</span>.layers(x)</code></span></span>1.2 MOE模型的当今意义
今年年初,我本以为开放权重的 MoE 模型会比现在更受欢迎、应用更广泛。虽然它们并非无关紧要,但许多最先进的模型仍然依赖于密集(传统)LLM 而不是 MoE,例如 Llama 3、Qwen 2.5、Gemma 2 等。顺便说一句,前两天全网爆火的DeepSeek-V3模型采用了 MoE 架构。所以,MoE 仍然非常重要!
2. 二月:权重分解的 LoRA
如果你正在对开源权重 LLM 进行微调,那么很有可能你在某个时候使用过低秩自适应 (LoRA),这是一种参数高效的 LLM 微调方法。
如果你是 LoRA 新手,我之前写过一篇关于大模型实战:使用 LoRA(低阶适应)微调 LLM 可能会对你有所帮助。
2.1 LoRA 回顾
在介绍 DoRA 之前,我们先来快速回顾一下 LoRA:
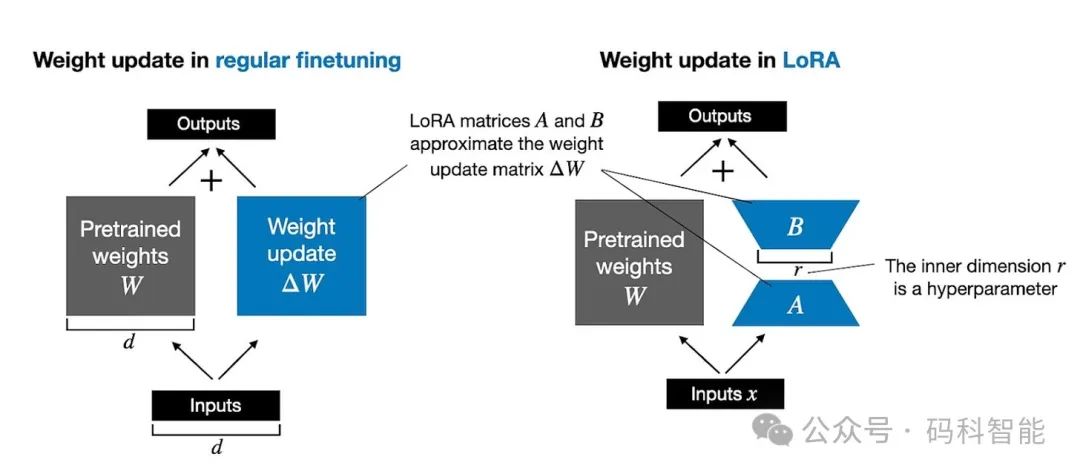
完全微调通过计算较大的权重更新矩阵ΔW来更新LLM 中的每个大权重矩阵W。LoRA将ΔW近似为两个较小矩阵A和B的乘积。因此,我们得到的不是 W + ΔW ,而是W + AB 。这大大减少了计算和内存开销。
下图并排说明了完全微调(左)和 LoRA(右)的对比。
2.2 从 LoRA 到 DoRA
《DoRA:权重分解低秩自适应》(2024 年 2 月)中,首先将预训练的权重矩阵分解为两部分,从而扩展了 LoRA:幅度向量 m 和方向矩阵V。这种分解的根源在于任何向量都可以用其长度(幅度)和方向(方向)表示的想法,在这里我们将其应用于权重矩阵的每个列向量。一旦我们有了 m 和 V ,DoRA 就会仅将 LoRA 样式的低秩更新应用于方向矩阵V ,同时允许单独训练幅度向量 m。
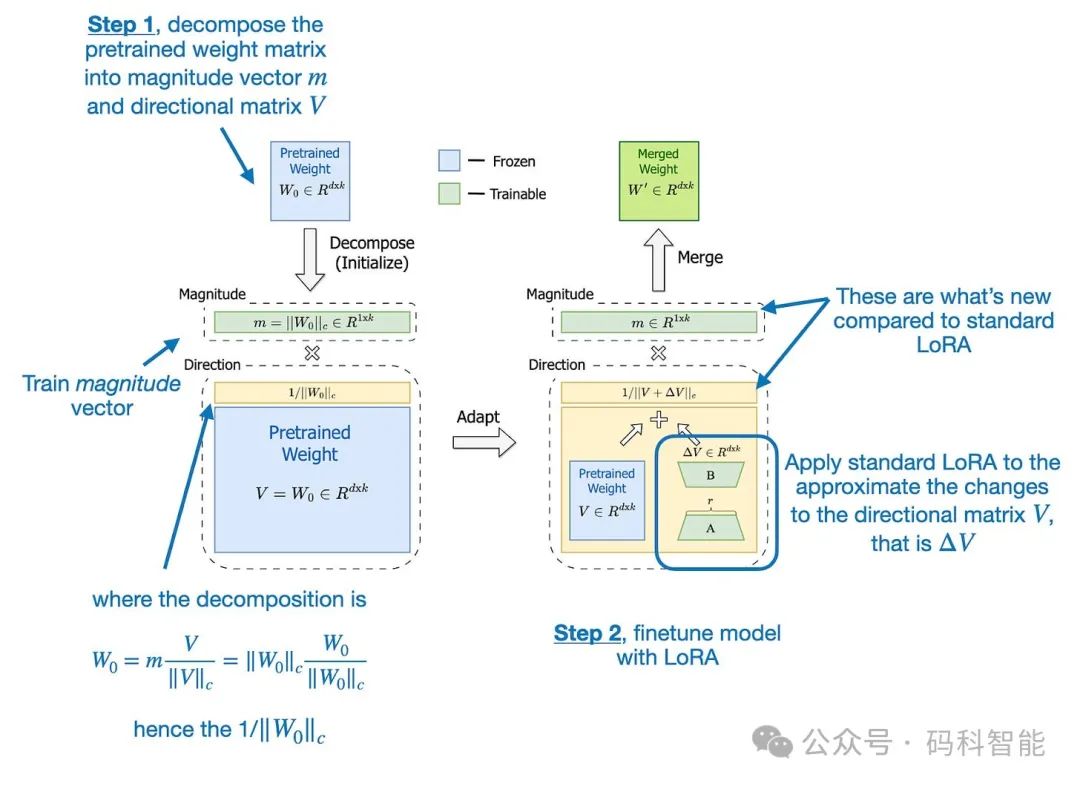
DoRA 是对原始 LoRA 方法的一个小的、合乎逻辑的改进。与 LoRA 倾向于统一调整幅度和方向不同,DoRA 可以进行细微的方向调整,而不必增加幅度。结果是提高了性能和稳定性,因为即使使用较少的参数,DoRA 也能胜过 LoRA,并且对等级的选择不太敏感。例如:Apple 最近在他们的Apple Intelligence Foundation Language Models论文中提到,他们使用 LoRA 来专门化 LLM 的设备任务。
3. 三月:持续进行LLM训练的技巧
据我所知,指令微调是 LLM 从业者最常用的微调形式。这里的目标是让公开可用的 LLM 更好地遵循指令,或者让这些 LLM 专门针对子集或新指令。然而,当谈到吸收新知识时,持续的预训练(有时也称为不断预训练)才是正确的方法。
3.1 简单的技术有效
这篇长达 24 页的《持续预训练大型语言模型》论文报告了大量的实验,并附带了无数的图表,
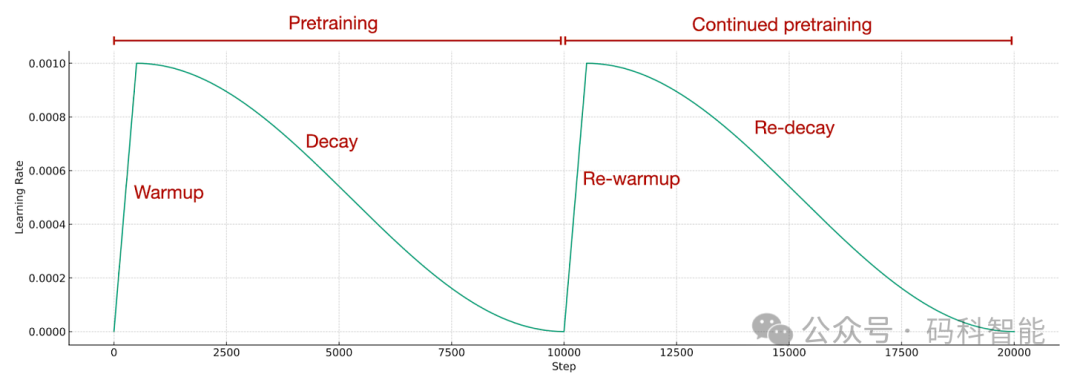
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code>https:<span style="color:#ca7d37">//arxi</span>v.org/<span style="color:#ca7d37">abs</span>/<span style="color:#0e9ce5">2403.08763</span></code></span></span>成功应用持续预训练的主要技巧是什么?如下图所示。
-
简单的重新Warmp并重新衰减学习率。
-
将原始预训练数据的一小部分(例如 5%)添加到新数据集中,以防止灾难性遗忘。请注意,0.5% 和 1% 等较小的比例也是有效的。
3.2 这些简单的技术还能继续有效吗?
没有理由相信这些方法不会继续适用于未来的 LLM。然而,值得注意的是,近几个月来,预训练流程变得更加复杂,由多个阶段组成,包括短上下文和长上下文预训练。
4. 四月:LLM 对齐的 DPO 或 PPO,还是两者兼有?
在总结论文本身之前,我们先来概述一下近端策略优化 (PPO) 和直接偏好优化 (DPO),这两种方法都是通过强化学习与人类反馈 (RLHF) 来对齐 LLM 的流行方法。RLHF 是将 LLM 与人类偏好对齐的首选方法,可提高其响应的质量和安全性。
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code>论文链接:https:<span style="color:#ca7d37">//arxi</span>v.org/<span style="color:#ca7d37">abs</span>/<span style="color:#0e9ce5">2404.10719</span></code></span></span>
传统上,RLHF-PPO 一直是训练 LLM 的关键步骤,用于 InstructGPT 和 ChatGPT等模型和平台。然而,DPO 因其简单性和有效性,去年开始受到关注。与 RLHF-PPO 相比,DPO 不需要单独的奖励模型。相反,它直接使用类似分类的目标来更新 LLM。许多 LLM 现在都使用 DPO,尽管缺乏与 PPO 的全面比较。
4.1 PPO 通常优于 DPO
对于 LLM 对齐,DPO 是否优于 PPO?综合研究是一篇写得很好的论文,包含大量实验和结果。主要结论是 PPO 往往优于 DPO,而 DPO 在处理分布外数据时表现较差。
此处,分布外数据意味着语言模型之前是在与用于 DPO 的偏好数据不同的指令数据(通过监督微调)上训练的。例如,模型可能在一般的 Alpaca 数据集上进行训练,然后在不同的偏好标记数据集上进行 DPO 微调。下图总结了主要发现。
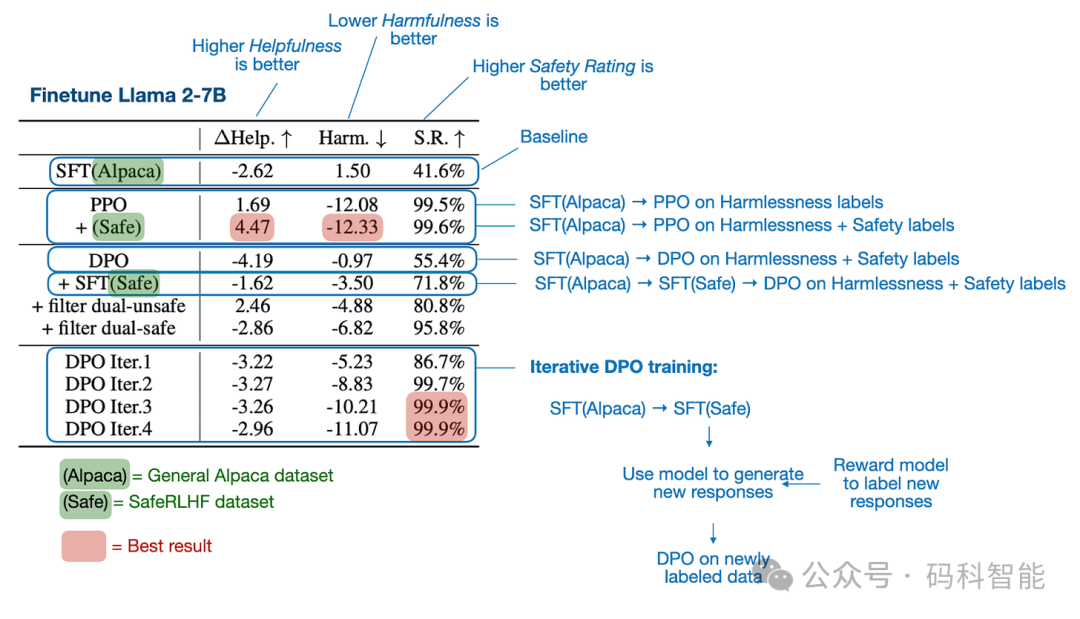
4.2 PPO 和 DPO 目前如何使用?
在最终 LLM 的原始建模性能方面,PPO 可能略有优势。但是,DPO 更容易实现,计算效率更高。因此,据我所知,DPO 在实践中的应用也比 RLHF-PPO 更为广泛。
一个有趣的例子是 Meta AI 的 Llama 模型。虽然 Llama 2 是用 RLHF-PPO 训练的,但较新的 Llama 3 模型使用的是 DPO。有趣的是,最近的模型甚至同时使用 PPO 和 DPO。最近的例子包括Apple 的 Foundation Models和 Allen AI 的Tulu 3 。
5. 五月:LoRA 学习得更少,遗忘得更少
我发现今年的另一篇 LoRA 论文特别有趣,因为它形式化了一些有关使用(和不使用)LoRA 微调 LLM 的常识: Biderman 及其同事撰写的《LoRA 学得更少,忘记得更少》(2024 年 5 月)。
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code>论文链接:https:<span style="color:#ca7d37">//arxi</span>v.org/<span style="color:#ca7d37">abs</span>/<span style="color:#0e9ce5">2405.09673</span></code></span></span>研究中比较了低秩自适应 (LoRA) 与大型语言模型 (LLM) 上的完全微调,重点关注两个领域(编程和数学)和两个任务(指令微调和持续预训练)。
研究表明,LoRA 的学习效果明显低于完全微调,尤其是在编码等需要获取新知识的任务中。当仅执行指令微调时,差距较小。这表明,与将预训练模型转换为指令跟随者相比,对新数据进行预训练(学习新知识)从完全微调中获益更多。
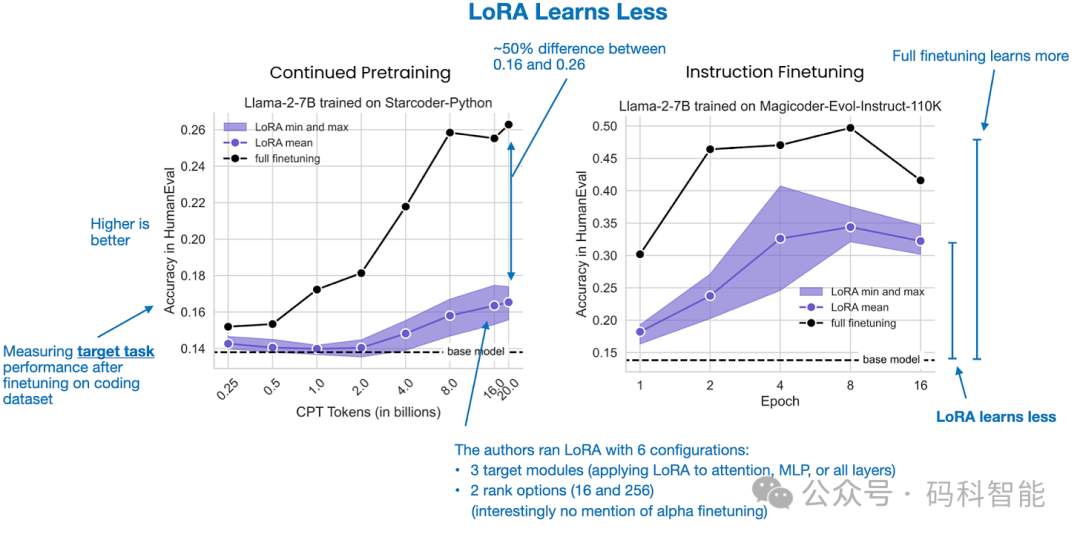
例如,对于数学任务,LoRA 和完全微调之间的差异缩小了。这可能是因为 LLM 对数学问题更熟悉,而且他们在预训练期间可能遇到过类似的问题。相比之下,编码涉及更独特的领域,需要更多新知识。因此,新任务距离模型的预训练数据越远,完全微调在学习能力方面就越有益。
5.1 未来对 LLM 进行微调的方法
在实践中,LoRA 之所以受到欢迎,是因为它比完全微调更节省资源。在许多情况下,由于硬件限制,完全微调根本不可行。此外,如果您只需要解决专门的应用程序,仅使用 LoRA 就足够了。由于 LoRA 适配器可以与基本 LLM 分开存储,因此很容易在添加新功能的同时保留原始功能。此外,可以将两种方法结合起来,使用完全微调进行知识更新,使用 LoRA 进行后续专业化
6. 六月:15 万亿Tokens FineWeb 数据集
Penedo 及其同事发表的论文《FineWeb 数据集:从网络中大规模获取最精细的文本数据》(2024 年 6 月)描述了为 LLM 创建 15 万亿个Token的数据集并将其公开。
<span style="color:rgba(0, 0, 0, 0.9)"><span style="background-color:#ffffff"><code>论文链接:<span style="color:#dd1144">https:</span>/<span style="color:#ca7d37">/arxiv.org/abs/2406.17557</span></code><code>数据集下载:https:/<span style="color:#ca7d37">/huggingface.co/datasets/HuggingFaceFW/fineweb</span></code><code>官方代码:<span style="color:#dd1144">https:</span>/<span style="color:#ca7d37">/github.com/huggingface/datatrove/blob/main/examples/fineweb.py</span></code></span></span>6.1 与其他数据集的比较
既然还有其他几个可用于 LLM 预训练的大型数据集,那么这个数据集有什么特别之处呢?其他数据集相对较小:RefinedWeb(500B 个令牌)、C4(172B 个令牌)、Dolma 1.6(3T 个令牌)和 1.7(1.2T 个令牌)中基于 Common Crawl 的部分、The Pile(340B 个令牌)、SlimPajama(627B 个令牌)、RedPajama 的去重版本(20T 个令牌)、Matrix 的英语 CommonCrawl 部分(1.3T 个令牌)、英语 CC-100(70B 个令牌)、Colossal-OSCAR(850B 个令牌)。
例如,约 3600 亿个 token 仅适用于小型 LLM,FineWeb 数据集中的 15 万亿个 token 应该是最多 5000 亿个参数的模型的最佳选择。
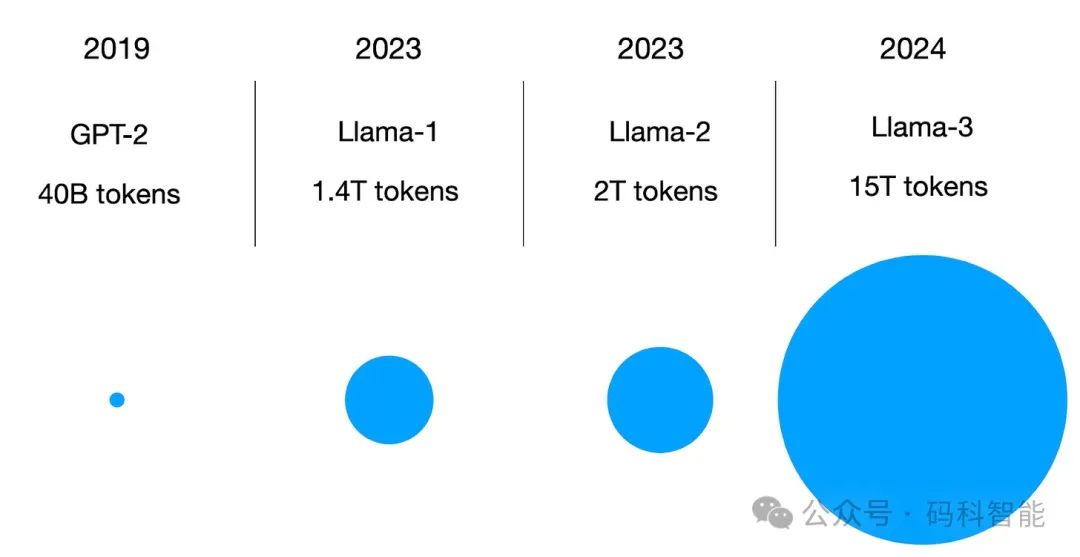
简而言之,FineWeb 数据集(仅限英文)理论上使研究人员和从业人员能够训练大规模 LLM。(附注: 8B、70B 和 405B 大小的Llama 3 模型也接受了 15 万亿个 token 的训练,但 Meta AI 的训练数据集不公开。)
看到这里,也顺手转发给关注大模型及人工智能技术的朋友们吧!
Mark.AI 好文推荐
► 顶配版SAM:由分割一切-升级至识别一切-再进化为感知一切
► 3 小时从零完全训练一个 26M 的小参数GPT?仅需 2G 显卡即可推理!即是开源项目又是LLM入门教程
► 顶配版OCR工具!支持任何语言、任意表格、图表与文档的文本检测和识别工具
► 迈向OCR-2.0新时代:通过统一的端到端模型,实现文本、数学公式、表格、图表及乐谱等内容的精确处理,同时支持场景和文档风格等


















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











