







全文总结
这篇论文介绍了DeepSeek-Coder系列模型,旨在通过大型语言模型提升代码智能。
研究背景
-
背景介绍:
这篇文章的研究背景是大型语言模型的快速发展极大地推动了软件开发中的代码智能。然而,封闭源代码模型的主导地位限制了广泛的研究和开发。为了解决这一问题,作者提出了DeepSeek-Coder系列,一系列开源的代码模型,旨在提供更广泛的代码智能研究和应用。 -
研究内容:
该问题的研究内容包括:介绍DeepSeek-Coder系列的开源代码模型,这些模型从2万亿个token中从头开始训练,并在多个基准测试中表现出色。此外,文章还探讨了如何通过预训练数据组织、Fill-In-The-Middle(FIM)策略和长上下文处理来增强模型的代码生成和补全能力。 -
文献综述:
该问题的相关工作包括对现有开源和封闭源代码模型的比较分析。作者指出,尽管封闭源代码模型如Codex和GPT-3.5在性能上表现优异,但其封闭性限制了研究和应用的广泛性。相比之下,开源模型在可访问性和灵活性方面具有优势。
研究方法
这篇论文提出了DeepSeek-Coder系列模型。具体来说:
-
模型训练:
模型在2万亿个token上进行从头训练,涵盖87种编程语言。采用Fill-In-The-Middle(FIM)策略和长上下文处理来增强代码生成和补全能力。FIM策略通过随机分割文本并连接特殊字符来进行预训练任务,以提高模型在代码补全任务中的表现。 -
数据收集:
训练数据集由87%的源代码、10%的英语代码相关自然语言语料库和3%的非代码中文自然语言语料库组成。数据收集过程包括数据爬取、规则过滤、依赖解析、仓库级去重和质量筛选。 -
模型架构:
使用基于Transformer的解码器模型,结合Rotary Position Embedding(RoPE)和Grouped-Query-Attention(GQA)。模型参数规模从1.3B到33B不等,以适应不同的计算和应用需求。
实验设计
-
实验设置:
使用多种公共代码相关的基准测试来评估模型的性能,包括HumanEval、MBPP、DS-1000和LeetCode Contest等。实验在HAI-LLM框架下进行,利用NVIDIA A100和H800 GPU进行训练。 -
数据处理:
数据集经过严格的过滤和去重处理,以确保数据质量和多样性。使用编译器和质量模型结合启发式规则进一步过滤低质量数据。
结果与分析
-
代码生成:
DeepSeek-Coder-Base在HumanEval和MBPP基准测试中表现出色,平均准确率分别为50.3%和66.0%。在DS-1000基准测试中,模型在所有库中均表现出较高的准确性。 -
FIM代码补全:
在单行补全基准测试中,DeepSeek-Coder-Base在Python、Java和JavaScript上的表现优于其他模型,显示出其在代码补全任务中的优越性。 -
跨文件代码补全:
在CrossCodeEval基准测试中,DeepSeek-Coder在多语言环境中表现出色,特别是在Python、Java、TypeScript和C#中。 -
数学推理:
在程序辅助数学推理任务中,DeepSeek-Coder-Base 33B在多个基准测试中表现出色,显示出其在复杂数学计算和问题解决方面的潜力。
结论
这篇论文介绍了DeepSeek-Coder系列模型,展示了其在代码生成和补全任务中的优越性能。通过开源和大规模训练,DeepSeek-Coder不仅缩小了与封闭源代码模型的性能差距,还在多个基准测试中表现出色。未来,作者计划继续开发和分享更强大的代码聚焦的大型语言模型,以进一步提升代码智能的应用水平。
这篇论文通过实证研究展示了开源代码模型在代码智能领域的巨大潜力,具有重要的理论和实践意义。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在大语言模型(LLMs)的基础上提升代码智能。具体来说,现有的闭源模型在性能和可访问性方面存在限制,因此作者提出了开源的DeepSeek-Coder系列模型,旨在解决这一问题。
- 研究难点:该问题的研究难点包括:如何有效地训练大型代码模型以理解多种编程语言,如何在预训练阶段增强模型的代码生成和填充能力,以及如何在不影响代码完成能力的前提下优化模型的性能。
- 相关工作:该问题的研究相关工作包括OpenAI的GPT系列模型、CodeGeeX、StarCoder、CodeLlama等。这些模型在代码生成和理解方面取得了一定的进展,但在性能和可访问性方面仍存在不足。
研究方法
这篇论文提出了DeepSeek-Coder系列模型,用于解决代码智能问题。具体来说,
-
数据收集:训练数据集由87%的源代码、10%的英文代码相关自然语言语料库和3%的中文非代码相关自然语言语料库组成。数据收集过程包括GitHub数据爬取和过滤、依赖解析、仓库级去重和质量筛选。

-
预训练策略:模型采用两种预训练目标:下一个令牌预测和填空-中间(FIM)。FIM方法通过将文本随机分成三部分并打乱顺序来增强模型的代码生成能力。具体来说,FIM方法包括前缀-后缀-中间(PSM)和后缀-前缀-中间(SPM)两种模式。
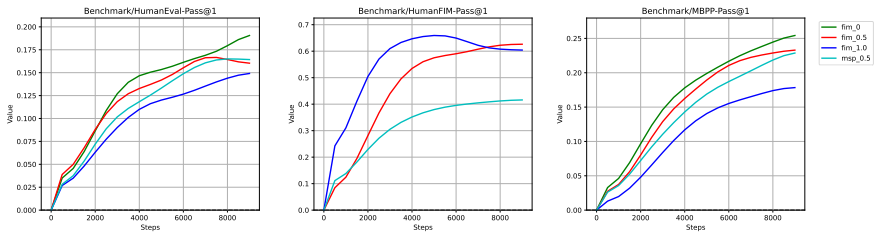
-
模型架构:开发了不同参数的模型,包括1.3B、6.7B和33B参数。每个模型都是基于解码器的Transformer模型,并采用了旋转位置嵌入(RoPE)和分组查询注意力(GQA)。
-
优化:使用AdamW优化器,学习率调度采用三阶段策略,初始学习率为10%,最终学习率为初始率的10%。
-
长上下文处理:通过调整RoPE参数,将上下文窗口扩展到16K,使模型能够处理更长的代码输入。
-
指令微调:通过使用高质量的指令数据进行微调,增强了DeepSeek-Coder-Base模型在零样本指令任务中的能力。
实验设计
- 数据收集:从GitHub收集2023年2月之前的公共代码库,过滤出87种编程语言。数据集包括源代码、英文代码相关自然语言语料库和中文非代码相关自然语言语料库。
- 预训练:在2万亿令牌的数据上进行预训练,采用下一个令牌预测和FIM两种预训练目标。FIM方法采用PSM和SPM两种模式,并通过消融实验确定最佳配置。
- 微调:使用高质量的指令数据进行微调,采用余弦调度,初始学习率为1e-5,批量大小为4M令牌。
- 评估:在多个代码相关的基准测试上进行评估,包括代码生成、FIM代码完成、跨文件代码完成和基于程序的数学推理。
结果与分析
-
代码生成:在HumanEval和MBPP基准测试中,DeepSeek-Coder-Base 33B模型的平均准确率分别为56.1%和66.0%,显著优于其他开源模型和闭源模型。
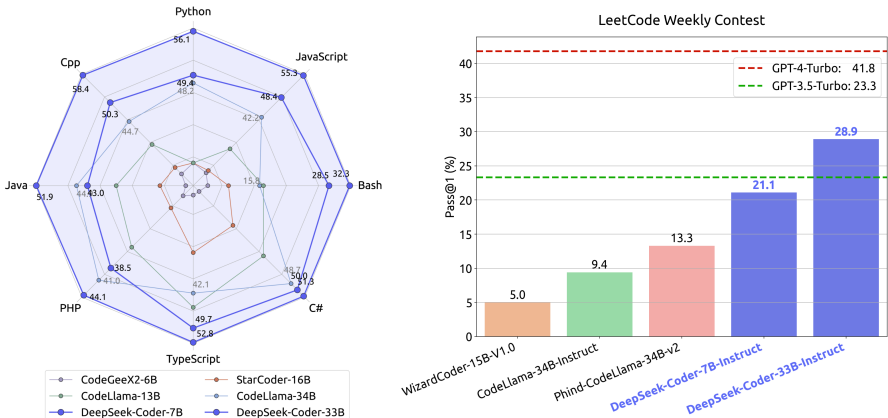
-
FIM代码完成:在单行填补基准测试中,DeepSeek-Coder-Base 1.3B模型的平均准确率为70.4%,优于其他模型。
-
跨文件代码完成:在CrossCodeEval基准测试中,DeepSeek-Coder-Base 6.7B模型在Python、Java、TypeScript和C#语言中的平均准确率分别为61.65%、61.77%、60.17%和52.30%,显著优于其他模型。
-
基于程序的数学推理:在PAL基准测试中,DeepSeek-Coder-Base 33B模型在所有七个基准测试中的平均准确率为65.8%,显著优于其他模型。
总体结论
这篇论文介绍了DeepSeek-Coder系列模型,这些模型在多个代码相关的基准测试中表现出色,显著优于现有的开源和闭源模型。通过大规模的训练和优化,DeepSeek-Coder模型不仅在代码生成和理解方面取得了显著进展,还在数学推理和自然语言处理方面展现了强大的能力。未来的工作将继续开发和分享更强大的代码聚焦大型语言模型。
论文评价
优点与创新
- 开源模型系列:引入了DeepSeek-Coder系列,包含从1.3B到33B不同规模的开放源码代码模型,确保了模型的多样性和适用性。
- 高质量预训练数据:模型在2万亿标记的高质量项目级代码语料库上进行预训练,涵盖了87种编程语言,确保了模型对编码语言的全面理解。
- 仓库级别数据构建:首次在预训练阶段引入仓库级别的数据构建,显著提升了跨文件代码生成的能力。
- Fill-in-the-Middle (FIM) 方法:采用了FIM方法来增强模型的代码补全能力,并通过消融实验确定了最佳的FIM配置。
- 长上下文支持:将上下文长度扩展到16K,使模型能够处理更复杂和广泛的编码任务,提高了模型的多功能性和适用性。
- 多语言支持:扩展了HumanEval基准测试的Python问题到七种其他常用编程语言,展示了模型的多语言能力。
- 多种评估基准:在多个代码相关的基准测试中进行了广泛的评估,证明了DeepSeek-Coder在不同任务上的卓越性能。
- 指令微调:通过高质量的指令数据进行微调,DeepSeek-Coder-Instruct在代码相关任务上超越了OpenAI GPT-3.5 Turbo模型。
- 额外预训练:基于DeepSeek-LLM 7B检查点进行了额外的预训练,进一步提高了模型的自然语言理解和数学推理能力。
不足与反思
- 数据污染问题:尽管在评估过程中尽量排除了测试数据的影响,但在未来的研究中仍需考虑数据污染的可能性。
- 长上下文适应方法的改进:虽然模型在16K上下文中表现可靠,但未来研究将继续优化和改进长上下文适应方法,以提高模型在处理更长上下文时的效率和用户体验。
关键问题及回答
问题1:DeepSeek-Coder系列模型在数据收集和处理方面有哪些独特的步骤?
- GitHub数据爬取和过滤:从GitHub收集2023年2月之前的公共代码库,过滤出87种编程语言。过滤规则包括文件平均行长度、最大行长度、字母字符比例等,初步减少数据量至32.8%。
- 依赖解析:解析文件之间的依赖关系,并按依赖顺序排列文件,以确保每个文件的上下文在其之前出现。具体算法包括拓扑排序,识别并处理不连通的子图。
- 仓库级去重:在仓库级别进行去重,确保每个代码样本的唯一性,避免长重复子字符串的影响。
- 质量筛选和污染防护:使用编译器和质量模型结合启发式规则,过滤掉语法错误、可读性差、模块化低的代码。实施n-gram过滤,移除与测试数据匹配的代码段。
这些步骤确保了训练数据的多样性和高质量,为模型的成功训练奠定了基础。
问题2:DeepSeek-Coder模型在预训练阶段采用了哪些特殊的训练目标和方法?
- 下一个令牌预测(Next Token Prediction):将多个文件连接成固定长度的条目,模型根据上下文预测下一个令牌。
- 填空-中间(Fill-in-the-Middle, FIM):通过将文本随机分成三部分(前缀、中间、后缀)并打乱顺序,增强模型的代码生成能力。FIM方法包括前缀-后缀-中间(PSM)和后缀-前缀-中间(SPM)两种模式。通过消融实验,确定最佳配置为50% PSM率。
- 长上下文处理:调整RoPE参数,将上下文窗口扩展到16K,使模型能够处理更长的代码输入。
这些方法使得DeepSeek-Coder模型在代码生成和填充方面表现出色,特别是在处理复杂和长代码任务时。
问题3:DeepSeek-Coder模型在多个代码相关的基准测试中表现如何?其性能如何与其他模型进行比较?
- 代码生成:在HumanEval和MBPP基准测试中,DeepSeek-Coder-Base 33B模型的平均准确率分别为56.1%和66.0%,显著优于其他开源模型和闭源模型,如CodeLlama-Base 34B和GPT-3.5-Turbo。
- FIM代码完成:在单行填补基准测试中,DeepSeek-Coder-Base 1.3B模型的平均准确率为70.4%,优于其他模型,如StarCoder和CodeLlama。
- 跨文件代码完成:在CrossCodeEval基准测试中,DeepSeek-Coder-Base 6.7B模型在Python、Java、TypeScript和C#语言中的平均准确率分别为61.65%、61.77%、60.17%和52.30%,显著优于其他模型,如CodeGeeX和StarCoder。
- 基于程序的数学推理:在PAL基准测试中,DeepSeek-Coder-Base 33B模型在所有七个基准测试中的平均准确率为65.8%,显著优于其他模型,如CodeLlama和GPT-3.5-Turbo。
总体而言,DeepSeek-Coder模型在多个代码相关的基准测试中表现出色,显著优于现有的开源和闭源模型,特别是在处理复杂和长代码任务以及数学推理方面。
DeepSeek-Coder:当大型语言模型遇上编程——代码智能的崛起
郭大亚 ∗1 ,朱启浩 ∗1,2 ,杨德俭 1 ,谢振达 1 ,董凯 1 ,张文涛 1 陈观亭1,毕晓1,吴宇1,李永科1,罗福丽1,熊英飞2,梁文峰1
1 深寻-AI
2北京大学软件与微电子学院关键实验室(教育部重点实验室);北京大学软件与微电子学院
{zhuqh, guodaya}@deepseek.com
https://github.com/deepseek-ai/DeepSeek-Coder
摘要
大型语言模型的快速发展已经彻底改变了软件开发中的代码智能。然而,闭源模型的盛行限制了广泛的研究与开发。为解决这一问题,我们推出了DeepSeek-Coder系列,这是一系列从13亿到330亿参数的开源代码模型,在2万亿个标记上从零开始训练。这些模型在高质量的项目级代码语料库上进行预训练,并采用16K窗口的填空任务来增强代码生成和填充能力。我们的广泛评估表明,DeepSeek-Coder不仅在多个基准测试中实现了开源代码模型的最先进性能,而且还超越了现有的闭源模型如Codex和GPT-3.5。此外,DeepSeek-Coder模型采用宽松的许可证,允许研究和无限制的商业使用。
图1 | DeepSeek-Coder的性能表现
1. 引言
软件开发领域因大型语言模型(OpenAI,2023年;Touvron等人,2023年)的迅猛发展而发生了显著变化,这标志着代码智能新时代的到来。这些模型具有自动化和简化编码多个方面的潜力,从错误检测到代码生成,从而提高生产力并降低人为错误的可能性。然而,该领域面临的一个主要挑战是开源模型(李等人,2023年;Nijkamp等人,2022年;Roziere等人,2023年;Wang等人,2021年)与闭源模型(Gemini团队,2023年;OpenAI,2023年)之间的性能差距。虽然强大的巨型闭源模型对许多人来说往往难以接触,因为其专有性质。
针对这一挑战,我们推出了DeepSeek-Coder系列。该系列包括一系列开源代码模型,规模从13亿到330亿不等,每个规模都包含基础版本和指导版本。该系列的每个模型都是使用来自87种编程语言的2万亿个标记从头开始训练的,确保全面理解编程语言和语法。此外,我们尝试在仓库级别组织预训练数据,以增强预训练模型在仓库内跨文件上下文中的理解能力。除了在预训
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











