






REINFORCE++逆袭!比Deepseek GRPO更稳定,揭示藏在REINFORCE++中的密码
原创 NLP轻松谈 NLP轻松谈 2025年02月24日 21:37 北京
基于人类反馈的强化学习 (RLHF, Reinforcement Learning from Human Feedback) 正在快速发展,PPO、DPO、RLOO、ReMax 和 GRPO 等算法相继出现。通过将近端策略优化 (PPO, Proximal Policy Optimization) 中的各种优化技术融入传统的 REINFORCE 算法,作者提出了REINFORCE++,旨在提高 RLHF 的性能和稳定性,同时减少计算资源需求,而无需依赖评论网络(critic network)。
REINFORCE++ 的一个关键优势是,它比 GRPO 更加稳定,比 PPO 更加高效。
什么是 REINFORCE?
REINFORCE 是强化学习中一种重要且简单的策略梯度方法,旨在通过直接优化策略来最大化期望的累积奖励。该算法采用蒙特卡洛方法,按以下步骤执行:
-
策略采样:智能体根据当前策略与环境互动,生成一系列状态、动作和奖励(轨迹)。
-
回报计算:对于每条轨迹,使用折扣累积奖励计算回报:
![]()
-
梯度估计:通过蒙特卡洛方法计算策略梯度,并按以下方式更新策略参数 :
![]()
-
策略更新:使用梯度上升法更新策略参数:
![]()
REINFORCE++ 中的关键优化技巧
为了稳定模型训练,REINFORCE++ 中引入了多个优化技巧:
Token 级别的 KL 惩罚
计算 RL 模型和 SFT 模型之间每个 Token 的响应分布的 KL 散度,并将其作为惩罚项加入到奖励函数中。具体地,每个 Token 的奖励表示如下:
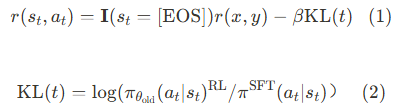
其中,表示指令,表示回复,表示是否是最后一个token.
Token 级别的 KL 惩罚的优势在于,它可以与过程奖励模型(PRM)无缝结合,实现信用分配,只需在奖励 Token 的位置添加 即可。
最近,有研究者发现,在 REINFORCE++ 中与 GRPO 一起使用外部 KL 损失也能取得良好效果。REINFORCE++逆袭Deepseek的GRPO!微软团队用逻辑谜题揭示大模型顿悟时刻
小批量更新
小批量更新通过以下方式提高了训练效率和稳定性:
-
将训练数据分成更小的批次,而不是使用整个数据集进行更新。
-
允许每个小批次进行多个参数更新,从而加速收敛并减少内存消耗。
-
引入随机性,帮助避免局部最优解,并提高模型的泛化能力。
奖励归一化与截断
该方法通过以下两种方式解决了奖励信号的波动性问题:
-
奖励归一化:对奖励进行标准化(例如,减去均值并除以标准差),使奖励信号更加平滑,增强训练的稳定性。
-
奖励截断:将奖励值限制在一定范围内,减少极端奖励对模型更新的影响,避免梯度爆炸。
优势归一化
优势归一化有助于管理 REINFORCE++ 中优势函数的方差。该优势函数的估计公式如下:
![]()
其中, 是结果奖励函数, 是每个 Token 的 KL 奖励, 是 Token 的位置。归一化过程包括:
-
计算完整批次中所有优势值的均值和方差。
-
对这些值进行归一化,以提高数值的稳定性并增强学习效果。在实践中采用 Z-score 归一化方法,即 ,其中 为均值, 为批次内样本的标准差。
PPO-Clip
PPO 算法中的一项关键技术,通过引入裁剪机制来限制策略更新的幅度,从而确保更新不会超过预定的阈值。其表达方式如下:
![]()
其中, 表示新旧策略的比率, 是优势估计, 是一个小常数。
事实上,作者在 REINFORCE 中采用了 PPO 的损失函数。
代码实现
REINFORCE++ 算法已基于 OpenRLHF 进行实现,具体实现细节可以在 GitHub 仓库中找到。
实验比较与参数
通过与 GRPO 等方法的对比实验,REINFORCE++ 展现出了明显的优势。关键的超参数包括:
-
KL 系数:(用于 BT 奖励模型)或 (用于数学测试)
-
最大样本数:
-
每个提示的样本数:
-
回滚批次大小:
-
训练批次大小:
-
演员学习率:
-
评论学习率:
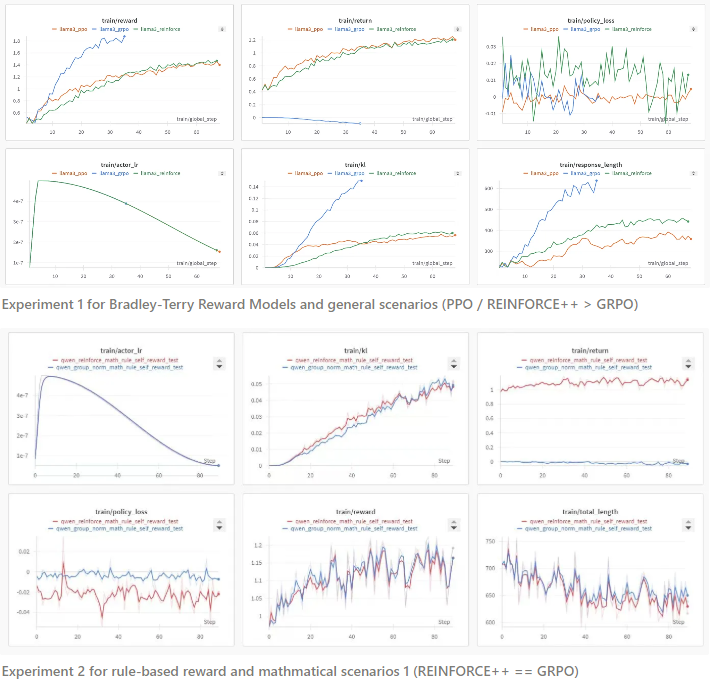
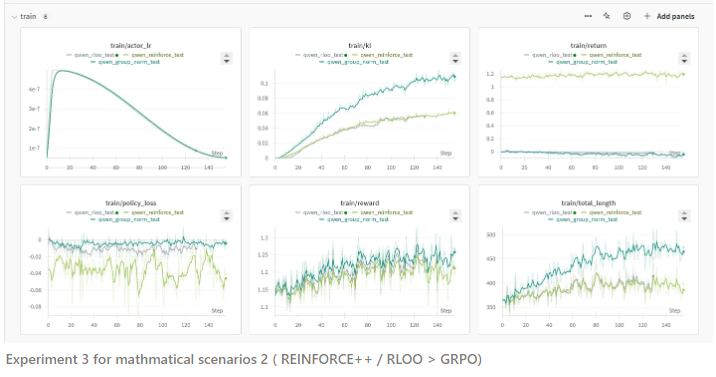
实验结果表明,REINFORCE++ 在稳定性上明显优于 GRPO,同时在单位 KL 消耗下实现了更高的奖励增益。此外,REINFORCE++ 相较于 PPO 还能够在没有评论网络的情况下节省计算资源,并有效解决了响应长度调整的问题。
最近,作者再次测试了 REINFORCE++,并尝试加入一个简单的奖励均值基准(类似于 RLOO),以观察会发生什么。
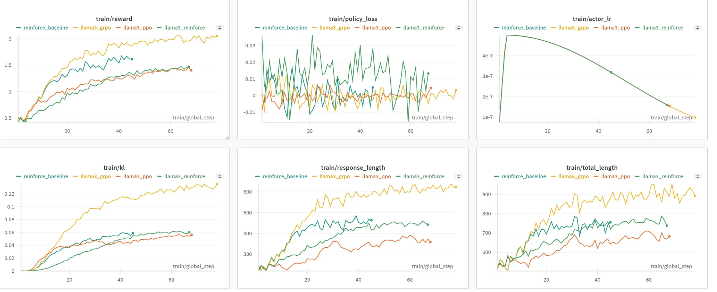
结果发现,去除 GRPO 中的 /std 参数,确实能够提高模型的稳定性。
讨论
Bradley-Terry (BT) 奖励模型
许多人认为,在成对奖励模型中,奖励的具体数值不重要,因此在 GRPO 中减去平均奖励看起来更合理。然而,这忽视了一个基本理解:强化学习(RL)本质上并不是通过奖励的绝对值来学习,而是通过奖励的相对值来进行学习。
如果从 Q 表的角度来看,无论我们将正负样本的奖励设置为 1 和 -1,还是 1 和 -0.5,RL 的学习目标都没有根本变化。RL 的目标始终是找到能获得最大奖励(即 1 分)的解决方案。在 RL 中,减去基准通常是为了减少梯度的方差。
过程奖励模型
有些人可能会问,为什么在像 REINFORCE++ 这样的算法中,直接使用累计回报来指导梯度优化。对于过程奖励模型,初始化的 token 累计回报通常比后面的 token 更大。为了解决这个问题,作者采用了 奖励归一化 技术,确保奖励既有正值也有负值。此外,作者还通过 优势归一化 进一步处理这些累计回报。
另外,还可以考虑不依赖累计回报来优化模型。相反,可以将 作为 token 的回报,这相当于将问题转化为 多智能体设置。这种方法的优点是可以提前进行信用分配,但缺点是它没有理论保证收敛性。
原文:REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
往期内容
REINFORCE++逆袭Deepseek的GRPO!微软团队用逻辑谜题揭示大模型顿悟时刻
没有H100也能玩转大模型!DeepSeek 的GRPO颠覆RLHF训练法则:16GB显存榨干百亿模型


















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











