






尺寸差了一个量级,如何较量?DeepSeek R1与阿里QwQ-32B
原创:亲爱的数据
2025年3月6日,
阿里通义千问团队推出推理模型
QwQ-32B大语言模型。
看似普通的一则新闻,
发布了一个模型这么件事。
阿里尚未发布详细的技术报告来解释 QwQ是如何开发的,甚至新闻官网只有742个字。
《QwQ-32B:拥抱强化学习的力量》

该怎么理解呢?
我的理解,
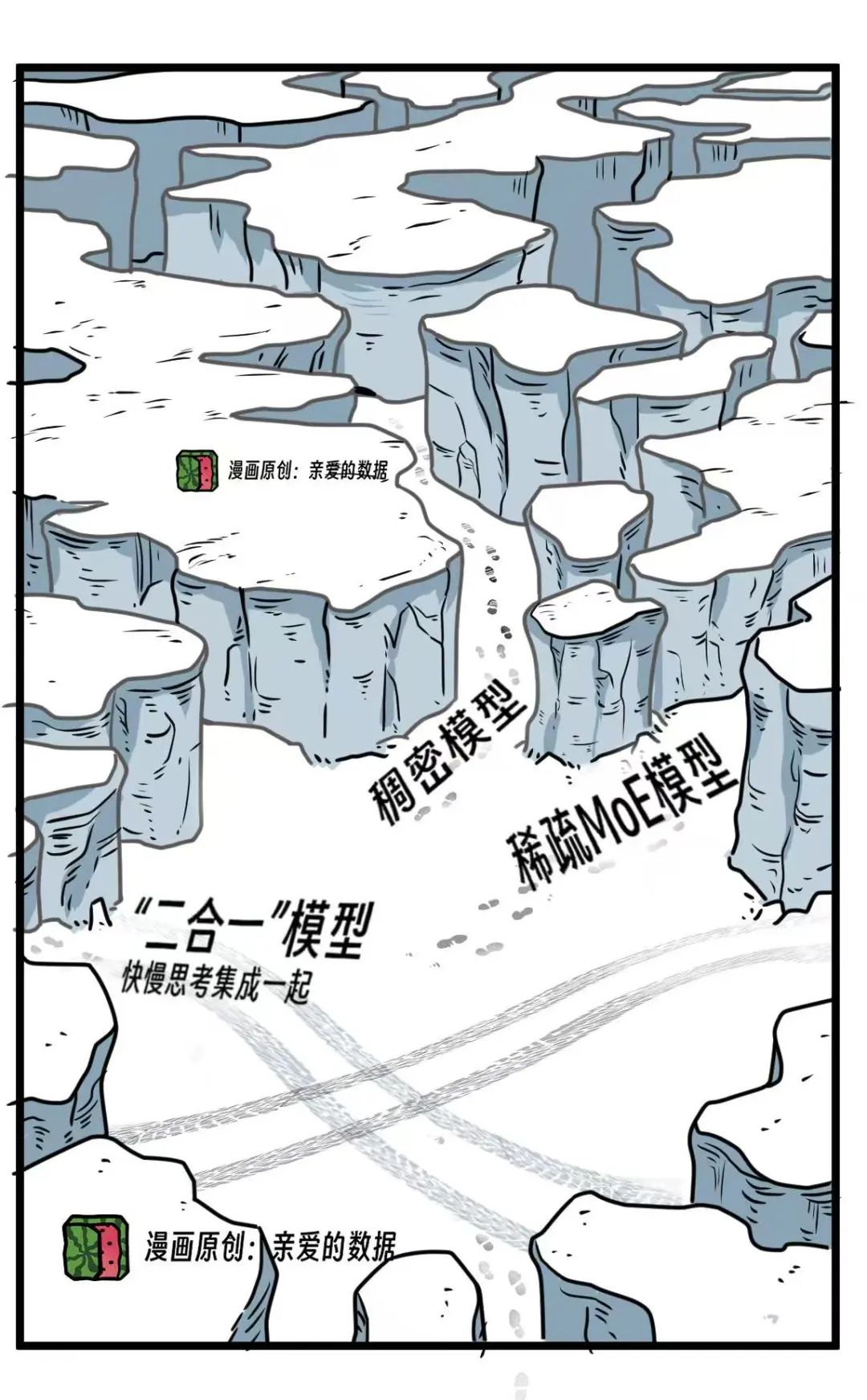
QwQ-32B是一款稠密(又称密集)推理模型。
虽然只有一句话,但是信息量很大。
想读懂的话,要很多“知识储备”,
什么是MoE(混合专家模型)?
什么是稠密模型?
什么是推理模型?
模型参数规模怎么对比?
背后隐藏的不少问题都可展开聊,
不如,聊聊有哪些结论?


第一点,QWQ模型有一个系列,
阿里在上一版的基础上,
用了R1也同样用了的强化学习技术。
好消息是出效果了,不出效果不会放出来。
毕竟这个是开源模型,
只有闭源模型才愿意买广告胡吹,
开源模型则不需要。
反观很多大模型友商,
还停留在花钱买彩虹屁的石器时代。
在开源打得如此激烈的当下,显得尤为又自嗨。
抛开“强不强”不聊,
要知道大模型技术人员的知识体系泾渭分明,
你是做视觉的,就是视觉;
你是自然语言处理的就是自然语言处理,
而强化学习是另外一套知识体系。
强化学习这条道路,
大模型团队里没有点技术储备都发不了力。
阿里毕竟是阿里,
看到强化学习的天花板还能往上推,
就毫不犹豫地往上推。
恭喜阿里出效果,恭喜团队奋战有成绩。
无独有偶,一天之前,
2024 年的图灵奖颁给了一对著名的师徒:
Richard Sutton 有“强化学习之父”的美名。
Andrew Barto是 Sutton的博导。
自 1980 年代起,
两位均对强化学习持续做出奠基性贡献。
一边是企业界的前沿技术突破,
另一边则是对强化学习理论基础的权威认可。
这两者实际上是相辅相成的,
正是几十年前奠定的坚实理论基础,
才使得今天我们能够在工业界实现如此惊人的技术突破。向强化学习开创者的致敬,向DeepSeek R1团队,向阿里千问团队,用强化学习推动模型技术进步的工程师致敬。

第二点,在推理模型大火之后,
大家都只做推理模型这一种类型了吗?
当然不是。
这里就不得不把Claude 3.7 Sonnet这个模型拉出来对比一下。
这也是一个刚刚(2月25日)放出来的新模型,
是Claude 3.5 Sonnet 的升级版。
不得不感慨一句,版本号增长得如此之快,
可见软件版本迭代得多快,
可见其背后的技术进展有多快。
AI的竞争有多激烈。


我特别强调,Claude 3.7 Sonnet模型的技术路线,
和QwQ-32B模型大不一样,完全不同。
QwQ-32B模型强调推理性能,
是一个独立的推理模型,
而Claude 3.7 Sonnet模型有推理能力(慢思考),
但是Claude团队把快慢思考集成在一个模型里了,
你想用哪个就选哪个。

特别注意的是,
选择按钮的背后是一个“二合一”的模型,
而不是一个“选项”一个模型,
技术博客上的表述是,人类使用同一个大脑,
既能静心思考,又有快速反应。
阿里是否也在做和Claude 团队类似的事情,
不得而知。
但是你用推理模型去快问快答简单问题,
肯定不合适,
比如,你问推理模型“你好”,
模型推理一番回答你,
或者是啰啰嗦嗦回答一堆。
比如,下面这种肯定不行,
日后定会想办法解决。


第三点,为什么QWQ-32B可达到DeepSeek R1的“智商”水平?
尤其是在尺寸差了一个量级的情况下。
在MoE模型出道之后,
模型参数规模不再是名字上挂的那个数字,
比如,DeepSeek R1拥有6710亿的巨大的参数量,但由于创新性地使用了MoE架构,以及MLA(多头潜在注意力机制)的方法,每次推理仅激活370亿参数(占比总量6%)。这使得DeepSeek R1虽然整体参数量很大,但干活时只需要动用极小的一部分力量。
MoE模型是稀疏模型,
也就是说,并不是每个计算步骤都会用到全部的模型参数,而是通过选取一些专家来参与计算。就好比,有一个专家库,但是每次干活不是专家库里的专家全体出动。
DeepSeek R1的惊人之处在于,
1个共享专家和256个专家,
实际上,历史上,哪个MoE模型也从来没有过达到如此庞大的专家数量。专家多了一时爽,那就问负载均衡怎么办?

当然DeepSeek处理得很好,
但是这篇文章不聊这个,按下不表。
DeepSeek每次通过路由专家,只选8个模型,
也就是说只有8个专家干活了,其他闲着。
那么问题来了,你统计工作量的时候,
是不是只算这8个(仅激活370亿参数)就够了。
于是,真正用来比较的,
是千问QWQ-32B和DeepSeek R1模型的37B。
“闲置专家”不在考虑范围内。
比模型整个的参数规模更难理解的是真正“参与工作”的参数,这个问题确实是伴随着MoE模型而出现的,从激活量来看,32B(320亿参数)比37B(370亿参数)少不了多少,这是一种进步。
激活量少了,随之而来的是,成本降低,性价比提高。另有一个关键点,阿里通义千问团队的这个模型是每个专家每次都在干活,而DeepSeek R1模型是每次干活是不同的专家。因为MoE的大参数量可不是吃白饭的,
MoE的全量大参数对模型能力极有加成,对于每个token激活的是不同的37B(370亿参数)这个时候,我想说,QWQ-32B的专家还挺能打的,毕竟DeepSeek R1模型的整体专家数量在这里摆着,长期干活的专家要会更多知识才能和擅长不同的更细分的领域的“当值专家”一较高下。
看到这里,我挺激动的,再次为千问团队高兴。
而我更高兴的是,DeepSeek最大的价值不是被膜拜,而是被超越。
(完)
One More thing
玩MoE模型,如何榨干芯片性能?
这个问题的答案得问DeepSeek,
他们将MoE技术拉到一个新高度,
又在分布式计算,通信库等底层基础设施方面大大下了一番功夫,
恭喜DeepSeek,喜提成本利润率545%,
每秒输出吞吐量约1.5万tokens。
(官宣数据14.8k tokens/s)。
我最近聊天的口头禅就是:
“人家DeepSeek每秒输出吞吐一万五,
友商吞吐原地杵。”
一万五是一次综合实力的大检阅。
数字这么好看,这真是一件好事,
整个系统的吞吐量越大越好,
问题在于怎么把吞吐做上去。
人人都知道要榨干芯片性能,
问题在于怎么榨干。
一个模型在某种型号的芯片上跑起来,
这个系统的总吞吐量的理论峰值,
是由芯片性能决定的。
芯片性能是上限,
也是工程团队竭尽全力接近的目标。
做出极高的总吞吐量,梦寐以求。
也就是说,有N个厂商,
每个都跑同样的DeepSeek R1模型,
每个厂商都用同样数量的芯片,
谁做到的总吞吐量最高,谁就最赚钱。
这门生意本质就是这点了。
对比一些友商和DeepSeek的吞吐,
DeepSeek高了10倍。
至于为何是10倍,得拿另外一篇文章来讲。
有兴趣的读者,请在文末留言扣数字1。
阿里千问团队也有MoE模型的经验。
或者这么说,DeepSeek的基础设施是为MOE设计的,效率非常之高,给谁一时都很难超越,不如在自己擅长的技术路线上发展。那天,我和武汉人工智能研究院王金桥院长一起吃拉面,他还给我科普:“MoE(稀疏)模型适合大型To C业务量,Dense(稠密)适合To B业务量。”
阿里选择稠密模型的理由非常充分,
云计算厂商就是服务To B业务的。
一周之后,DeepSeek就搞了开源周,
不得不说,慷慨开源很多MoE底层技术,
商业机密肯定还有很多。
我所知道的是,
稀疏和稠密是两种完全不同的技术路线,
榨干芯片性能的方法完全不一样,
把稠密技术路线调为MoE稀疏技术路线谈何容易。
当DeepSeek横空出世,不只是模型,
而是模型带着它的榨干芯片性能的全套方案一起横空出世,这可是MoE专属方案。
这时,有一个选择题摆在大模型厂商面前,
在致敬和学习之后,也要做MoE模型吗?
这个问题我特别想问千问团队的人,
无奈周靖人把团队看得太严了。
此时,我想,他们已经给我答案了。
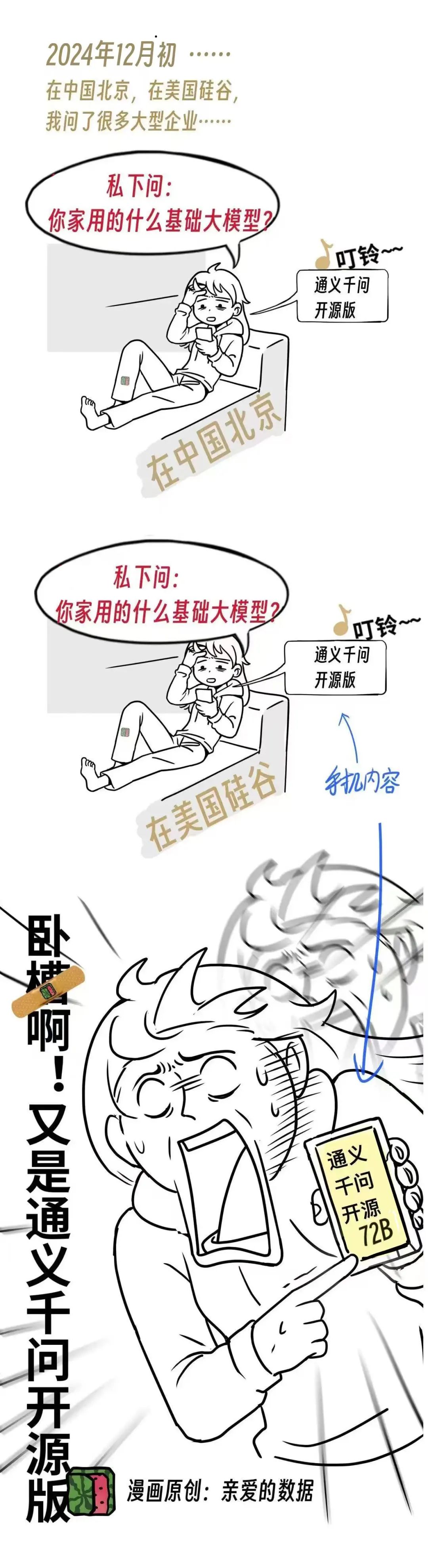
我们回忆一下,在DeepSeek爆火之前,
通义千问72B横扫企业级市场,
无论中国,还是美国,头部科技大厂内部都在悄悄用通义千问72B。阿里千问团队和美国Meta公司(Llama)选择同一种开源市场策略。
面对令人尊敬的挑战者,
阿里交出了自己的答卷。
竞争还在继续。
(完)


















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











