







近一年,多模态视觉&语言大模型架构演进汇总梳理
CV开发者都爱看的 极市平台 2024年07月15日 22:00 广东
作者丨Dreamweaver
极市导读
本文回顾了多模态LLM (视觉-语言模型) 近一年来的模型架构演进,对其中有代表性的工作进行了精炼总结,截止2024.06。
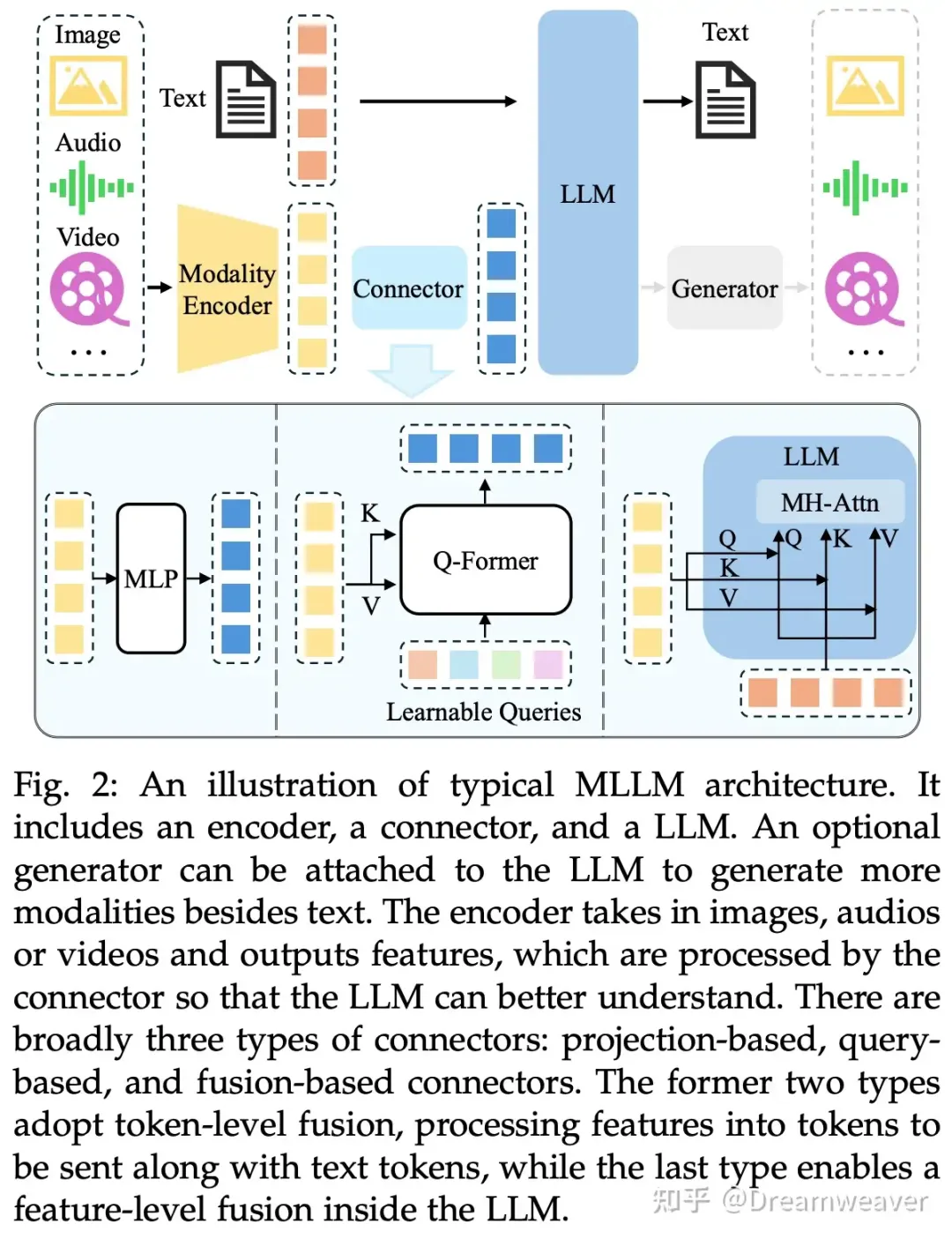
这篇综述一张图总结了多模态LLM的典型架构:
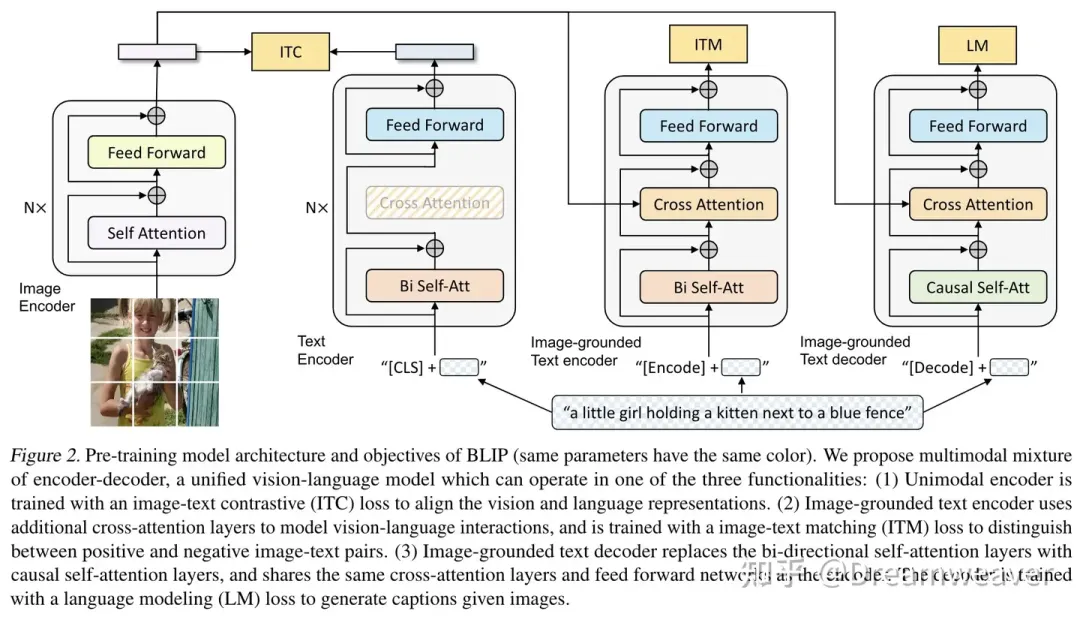
BLIP
【2022.01发布】[1]
统一视觉-语言理解和生成,使用captioner+filter高效利用互联网有噪数据

模型架构:
• Image/text encoder: ITC loss对齐视觉和语言表征,基于ALBEF提出的momentum distillation
• Image-grounded text encoder: ITM loss建模视觉-语言交互,区分positive/negative图文对,使用hard negative mining挖掘更高相似度的负例优化模型
• Image-grounded text decoder: LM loss实现基于图像的文本解码,将双向self-attention替换为causal self-attention
BLIP的bootstrapping训练过程:

BLIP-2
【2023.01发布】[2]
使用相对轻量的Q-Former连接视觉-语言模态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2931
2931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











