






LLM 大模型学习必知必会系列(一):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化
原创 XX AIGC小白入门记 2024年08月01日 12:01 广东

VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化
-
Github 地址:https://github.com/vllm-project/vllm
一、前言
1.1 重要推理超参数
-
do_sample:布尔类型。是否使用随机采样方式运行推理,如果设置为False,则使用beam_search方式
-
temperature:大于等于零的浮点数。公式为:
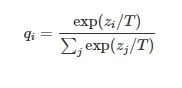
从公式可以看出,如果T取值为0,则效果类似argmax,此时推理几乎没有随机性;取值为正无穷时接近于取平均。一般temperature取值介于[0, 1]之间。取值越高输出效果越随机。如果该问答只存在确定性答案,则T值设置为0。反之设置为大于0。
-
top_k:大于0的正整数。从k个概率最大的结果中进行采样。k越大多样性越强,越小确定性越强。一般设置为20~100之间。
-
实际实验中可以先从100开始尝试,逐步降低top_k直到效果达到最佳。
-
-
top_p:大于0的浮点数。使所有被考虑的结果的概率和大于p值,p值越大多样性越强,越小确定性越强。一般设置0.7~0.95之间。
-
实际实验中可以先从0.95开始降低,直到效果达到最佳。
-
top_p比top_k更有效,应优先调节这个参数。
-
-
repetition_penalty:大于等于1.0的浮点数。如何惩罚重复token,默认1.0代表没有惩罚。
1.2 KVCache
上面我们讲过,自回归模型的推理是将新的token不断填入序列生成下一个token的过程。那么,前面token已经生成的中间计算结果是可以直接利用的。具体以Attention结构来说:
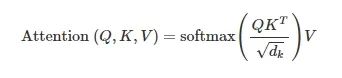
推理时的Q是单token tensor,但K和V都是包含了所有历史token tensor的长序列,因此KV是可以使用前序计算的中间结果的,这部分的缓存就是KVCache,其显存占用非常巨大。
二、VLLM框架
vLLM 是一个专注于 LLM(大型语言模型)的推理和部署库,它整合了 iterative-level schedule 调度策略和 PagedAttention 注意力机制,旨在优化处理能力。其中,iterative-level schedule 通过连续批次处理(continuous batching),即在生成一个 token 后立即安排下一批请求,来提升效率。而 PagedAttention 则借鉴了操作系统的分页管理概念,将连续的键值缓存分散存储,以减少显存的不必要占用,提高整体性能。
2.1 vLLM 架构
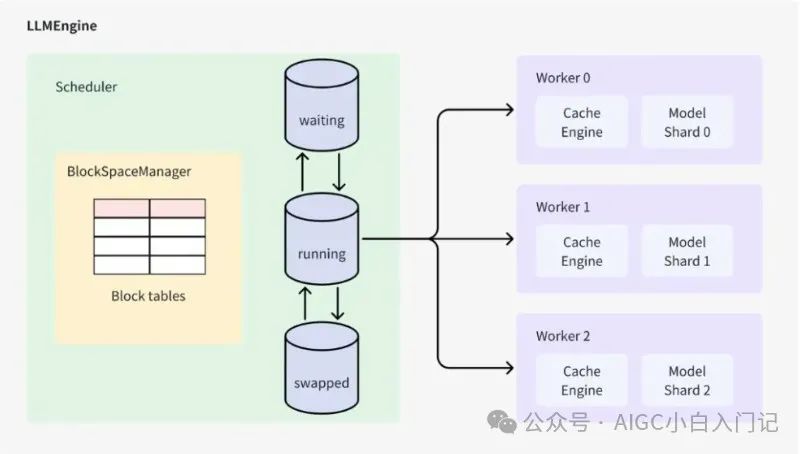
上图展示了 vLLM 的架构,其中 LLMEngine 类是核心组件。外部接口类 LLM 和 AsyncLLMEngine 是对 LLMEngine 的封装。
LLMEngine 包含两个关键组件:Scheduler 负责调度请求,Worker 负责执行模型推理。Scheduler 从等待队列中选择下一个要处理的请求,而 Worker 则使用模型对选定的请求进行推理。
2.2.1 Scheduler
Scheduler 采用 iterative-level 策略来调度请求,即在生成一个 token 后重新调度下一批请求。这种策略允许 vLLM 在每一轮迭代中处理不同数量的请求(即 batch size 不固定),从而最大化吞吐量。请求的处理分为两个阶段:填充阶段和生成阶段。
-
在填充阶段,Scheduler 会处理 prompt,同时生成第一个 token 并生成 prompt KV cache。
-
在生成阶段,Scheduler 会继续预测下一个 token。
目前有两种实现 iterative-level 策略的方法:一种是区分填充阶段和生成阶段,另一种是不区分这两个阶段。vLLM 采用的是第一种方法,即同一批次中的请求要么都处于填充阶段,要么都处于生成阶段,这与 huggingface 的 TGI 推理库保持一致。而 Orca 系统则没有区分这两个阶段。
2.2.2 Worker
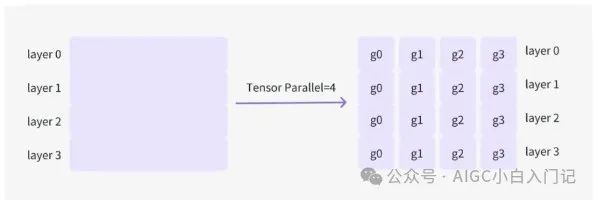
上图为Worker流程图。Worker 负责执行模型推理。对于大型模型,可以将模型分布在多个 Worker 上以协同处理请求。
例如,假设模型由 4 层组成,且有 4 张显卡可用,可以设置 Tensor Parallelism 为 4。这样,模型将被分成 4 个部分,每张显卡负责存储和处理模型的一部分。
2.2 主要特性
-
通过PagedAttention对 KV Cache 的有效管理
-
传入请求的continus batching,而不是static batching
-
支持张量并行推理
-
支持流式输出
-
兼容 OpenAI 的接口服务
-
与 HuggingFace 模型无缝集成
2.3 vLLM 核心技术点
2.3.1 Continuous batching
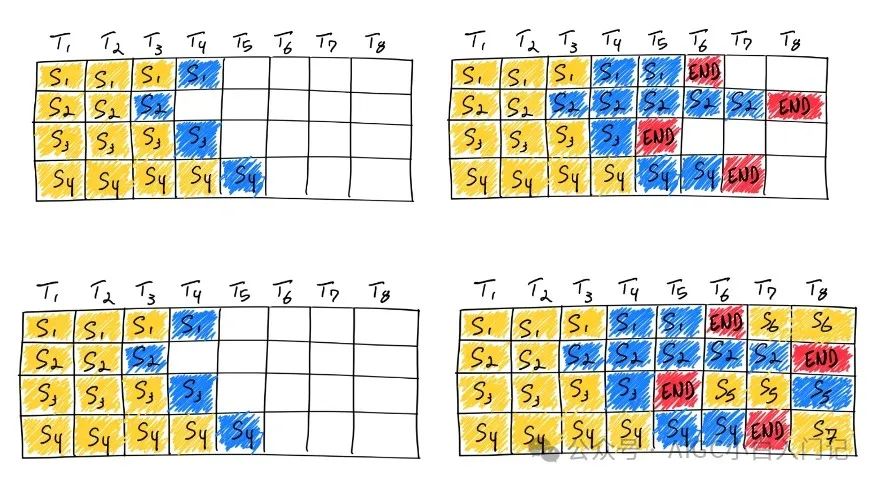
在实际推理过程中,一个批次多个句子的输入的token长度可能相差很大,最后生成的模型输出token长度相差也很大。在python朴素推理中,最短的序列会等待最长序列生成完成后一并返回,这意味着本来可以处理更多token的GPU算力在对齐过程中产生了浪费。continous batching的方式就是在每个句子序列输出结束后马上填充下一个句子的token,做到高效利用算力。
2.3.2 PagedAttention
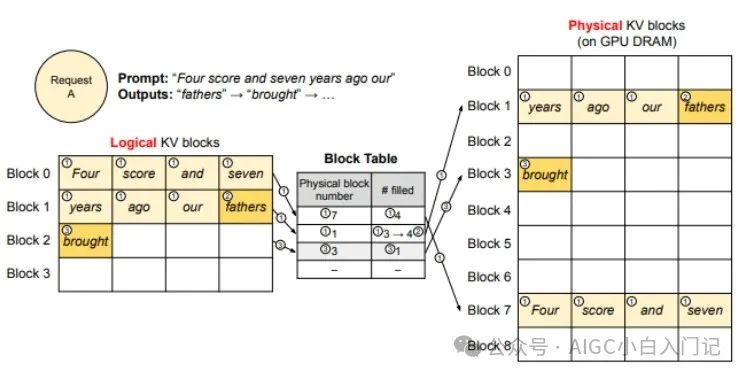
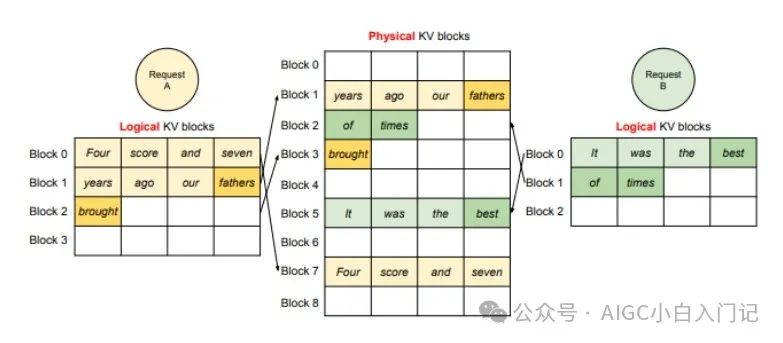
推理时的显存占用中,KVCache的碎片化和重复记录浪费了50%以上的显存。VLLM将现有输入token进行物理分块,使每块显存内部包含了固定长度的tokens。在进行Attention操作时,VLLM会从物理块中取出KVCache并计算。因此模型看到的逻辑块是连续的,但是物理块的地址可能并不连续。这和虚拟内存的思想非常相似。另外对于同一个句子生成多个回答的情况,VLLM会将不同的逻辑块映射为一个物理块,起到节省显存提高吞吐的作用。


















 5310
5310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











