






徒手深入探究 LSTM 和 xLSTM
南七无名式 PyTorch研习社 2024年07月18日 12:10 安徽
我们开始深入探索最吸引人的循环神经网络之一——长短期记忆网络,俗称 LSTM。我们为什么要重温这个经典?因为随着语言建模中较长的上下文长度变得越来越重要,它们可能再次变得有用。
LSTM 能否再次超越 LLM?
不久前,奥地利的研究人员提出了一项有希望的计划,以重振 LSTM 的辉煌——让位于更先进的扩展长短期记忆网络(也称为 xLSTM)。可以毫不夸张地说,在 Transformers 出现之前,LSTM 曾是无数深度学习成功的典范。现在的问题是,在最大限度地发挥其能力并尽量减少缺点的情况下,它们能否与当今的 LLM 相媲美?
为了找到答案,让我们回顾一下过去,回顾一下 LSTM 是什么,以及是什么让它们如此特别:
长短期记忆网络最早于 1997 年由 Hochreiter 和 Schmidhuber 提出——用于解决 RNN 面临的长期依赖问题。该论文被引用了大约 106518 次,难怪 LSTM 成为经典。
LSTM 的关键思想是能够在任意时间间隔内学习何时记住和何时忘记相关信息。就像我们人类一样。我们不是每个想法都从头开始,而是依靠更古老的信息,能够非常恰当地把这些点连接起来。当然,当谈到 LSTM 时,就会出现一个问题——RNN 不是做同样的事情吗?
简短的回答是,是的,它们会。然而,有一个很大的区别。RNN 架构不支持深入研究过去——只支持研究最近的过去。这没什么帮助。
作为一个例子,让我们考虑一下约翰·济慈在《秋日》中写的这些诗句:
“Season of mists and mellow fruitfulness,
Close bosom-friend of the maturing sun;”
翻译成中文:
“雾气弥漫、果实成熟的季节,
成熟太阳的亲密知己;”
作为人类,我们知道“雾”和“醇厚的果实”这两个词在概念上与秋季有关,让人联想到一年中的特定时间。同样,当“成熟的太阳”出现时,LSTM 可以捕捉到这个概念,并用它来进一步理解上下文。尽管这些词在序列中是分开的,但 LSTM 网络可以学会关联并保持先前的连接完整。与原始的循环神经网络框架相比,这是巨大的反差。
LSTM 实现这一点的方式是借助门控机制。如果我们考虑 RNN 与 LSTM 的架构,差异非常明显。RNN 具有非常简单的架构——过去状态和当前输入通过激活函数输出下一个状态。另一方面,LSTM 块在 RNN 块之上增加了三个门:输入门、遗忘门和输出门,它们共同处理过去状态和当前输入。门控的理念就是造成所有差异的原因。
为了进一步理解,让我们深入了解令人惊叹的 Tom Yeh 教授关于 LSTM 和 xLSTM 的这些令人难以置信的作品。
首先,让我们先了解 LSTM 背后的数学原理,然后再探索其新版本。
LSTM 如何工作?
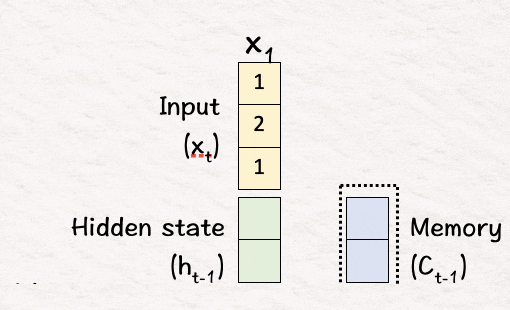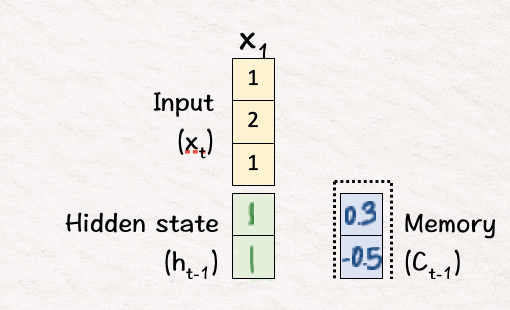
[1] 初始化
第一步从随机分配先前隐藏状态 h0 和记忆单元 C0 的值开始。为了与图表保持同步,我们设置
h0 → [1,1]
C0 → [0.3, -0.5]
[2] 线性变换
下一步,我们通过将四个权重矩阵(Wf、Wc、Wi 和 Wo)与连接的当前输入 X1 和我们在上一步中分配的先前隐藏状态相乘来执行线性变换。
结果值称为当前输入和隐藏状态组合获得的特征值。
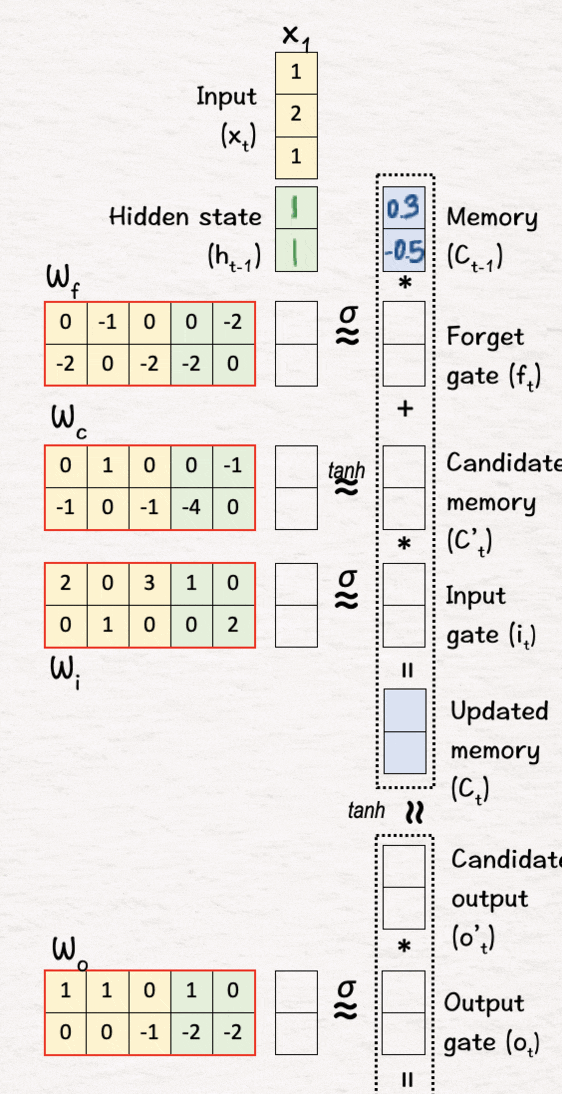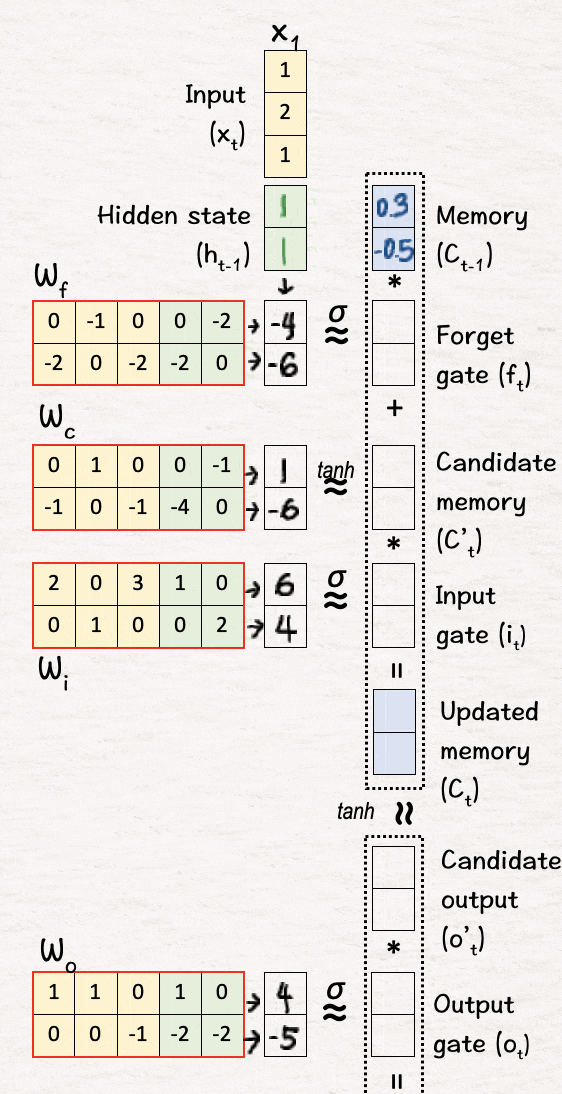
[3] 非线性变换
此步骤在 LSTM 过程中至关重要。它是一个非线性变换,由两部分组成——S 型函数 σ 和 tanh。
S 型函数用于获取 0 到 1 之间的门值。这一层本质上决定了要保留哪些信息以及要忘记哪些信息。值始终介于 0 和 1 之间——“0”表示完全消除信息,而“1”表示保留信息。
-
遗忘门 (f1):[-4, -6] → [0, 0]
-
输入门 (i1):[6, 4] → [1, 1]
-
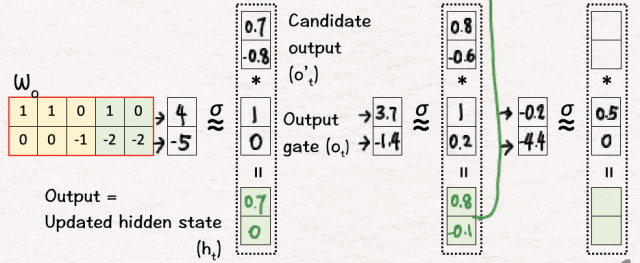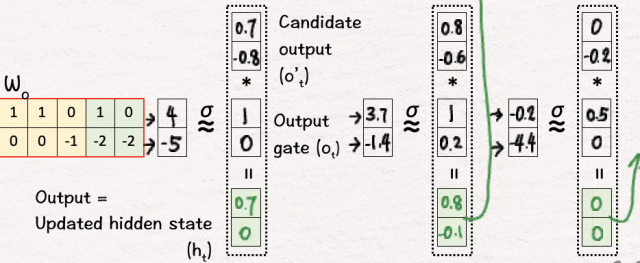
输出门 (o1):[4, -5] → [1, 0]
在下一部分中,应用 tanh 来获取可以添加到先前信息之上的新候选记忆值。
-
候选记忆 (C'1):[1, -6] → [0.8, -1]
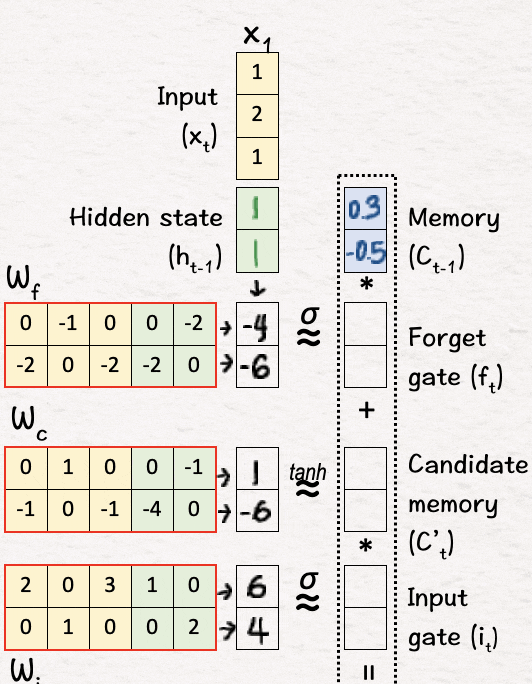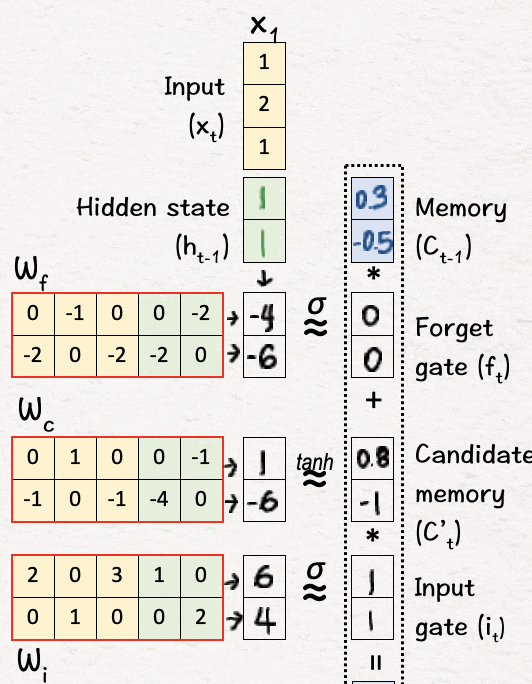
[4] 更新记忆
一旦获得上述值,就该使用这些值更新当前状态了。
上一步决定了需要做什么,在这一步我们实施该决定。
我们分两部分进行:
-
遗忘:将当前记忆值(C0)逐元素乘以获得的忘记门值。它的作用是在当前状态下更新已决定的可能被遗忘的值。→C0.*f1
-
输入:将更新后的记忆值(C'1)逐元素乘以输入门值以获得“输入缩放”的记忆值。→C'1.*i1
最后,我们将上述这两个项相加以获得更新后的记忆C1,即C0.*f1+C'1.*i1=C1
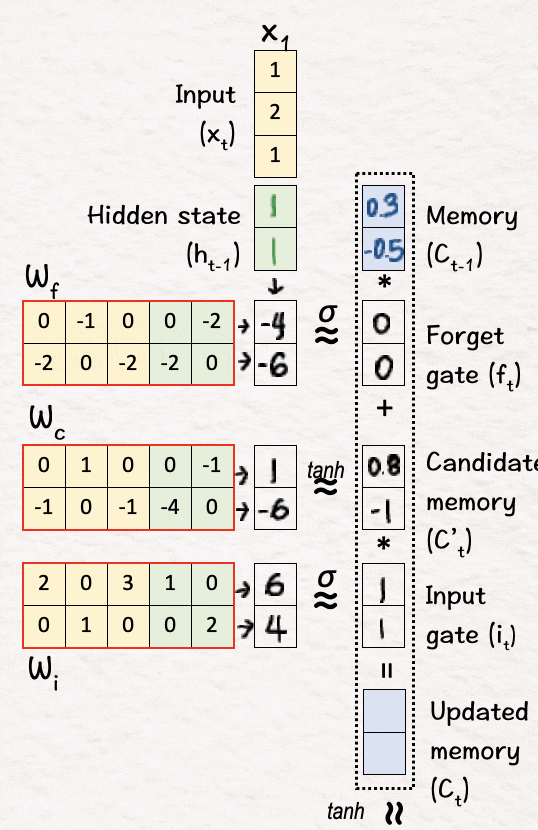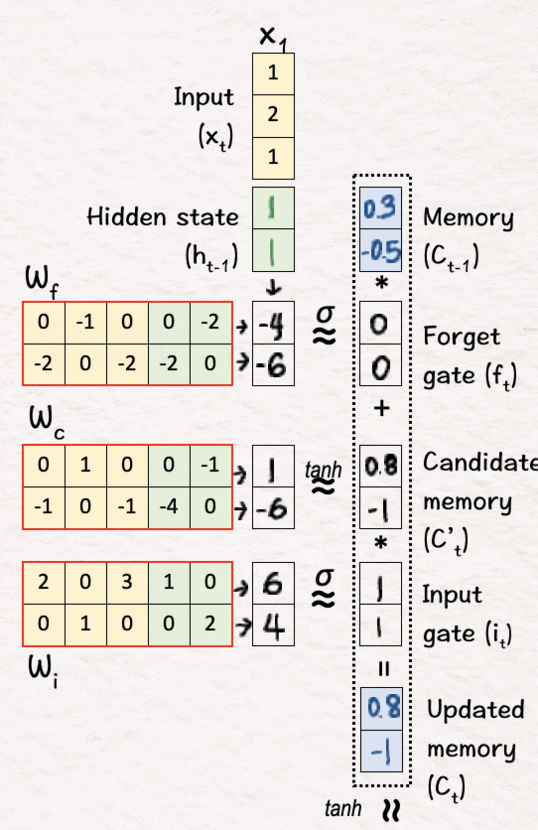
[5] 候选输出
最后,我们决定输出是什么样子:
首先,我们像以前一样将 tanh 应用于新内存 C1 以获得候选输出 o’1。这会将值推到 -1 和 1 之间。
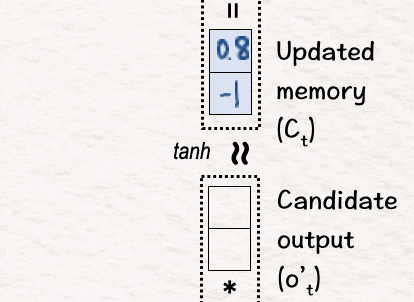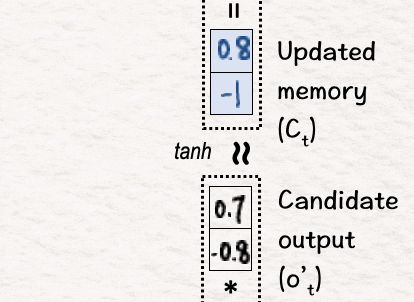
[6] 更新隐藏状态
为了得到最终的输出,我们将上一步得到的候选输出o’1与步骤3中得到的输出门o1的sigmoid相乘,得到的结果就是网络的第一个输出,也就是更新后的隐藏状态h1,即o’1*o1=h1。
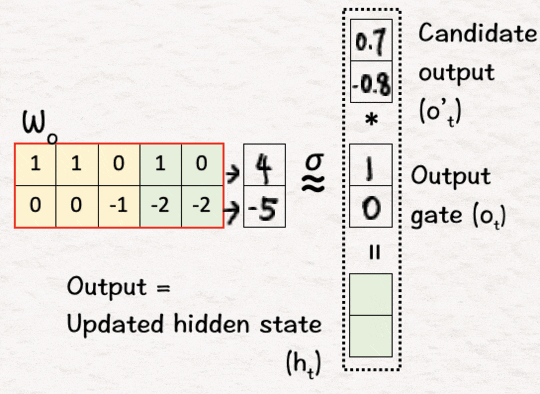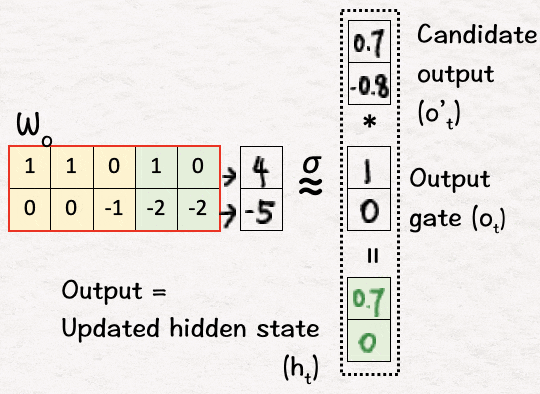
我们继续进行以下后续迭代:
[7] 初始化
首先,我们从前面的步骤中复制更新,即更新的隐藏状态 h1 和内存 C1。
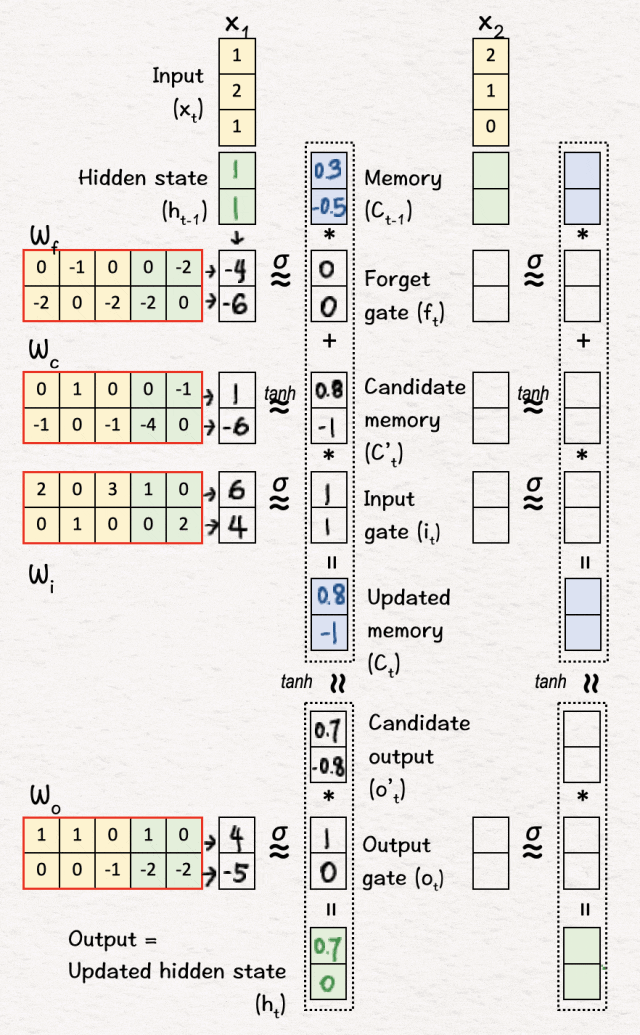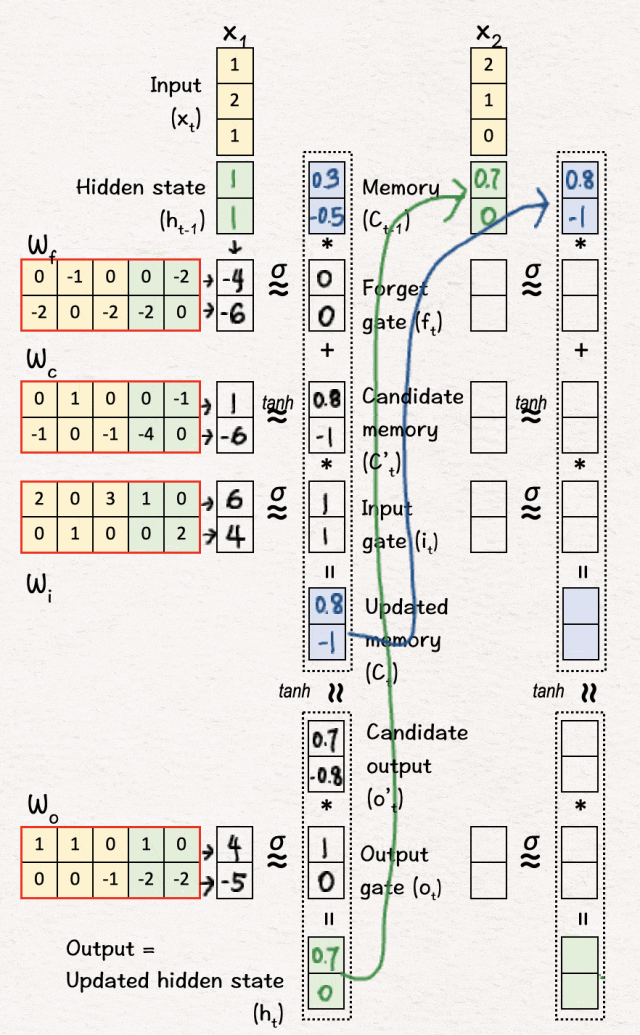
[8] 线性变换
我们重复步骤 [2],即逐元素权重和偏差矩阵乘法。
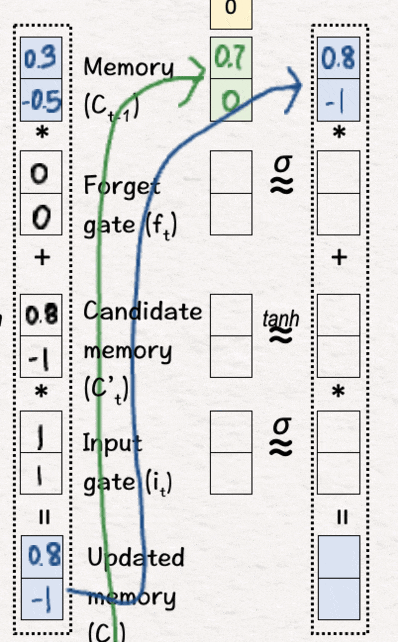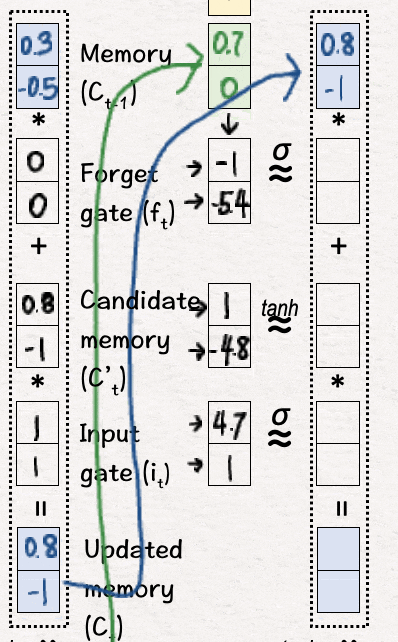
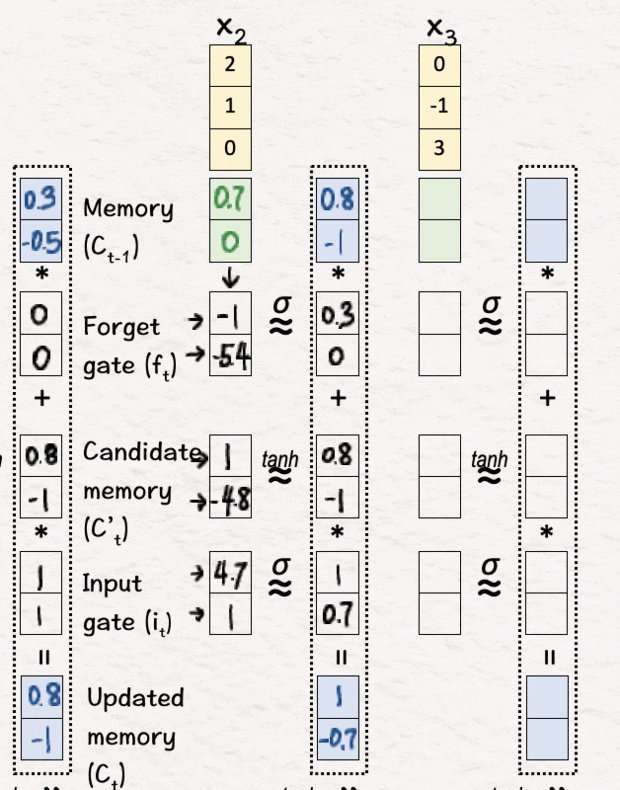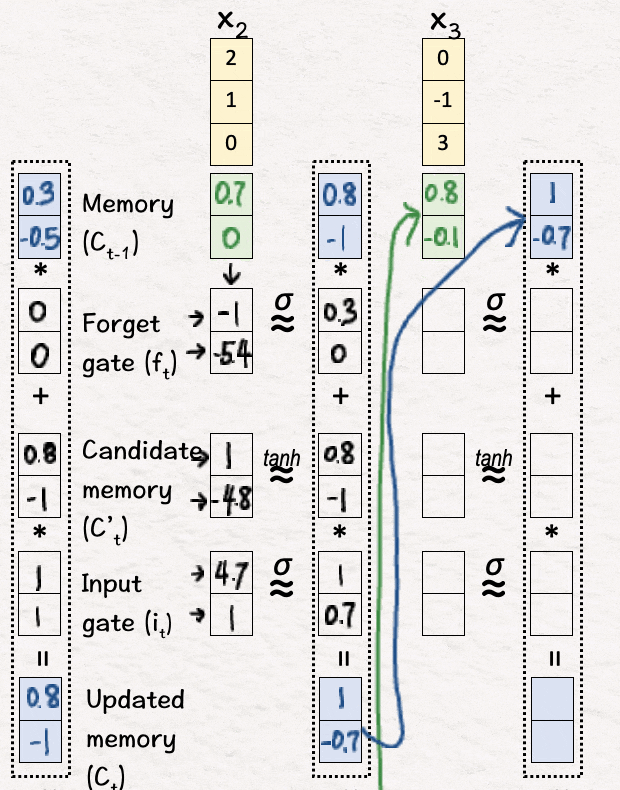
[9] 更新记忆 (C2)
我们重复步骤 [3] 和 [4],即使用 sigmoid 和 tanh 层进行非线性变换,然后决定忘记相关部分并引入新信息——这给了我们更新后的记忆 C2。

[10] 更新隐藏状态 (h2)
最后,我们重复步骤 [5] 和 [6],得到第二个隐藏状态 h2。
接下来,我们进行最后一次迭代。
[11] 初始化
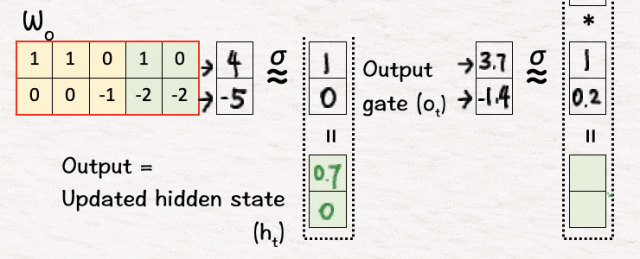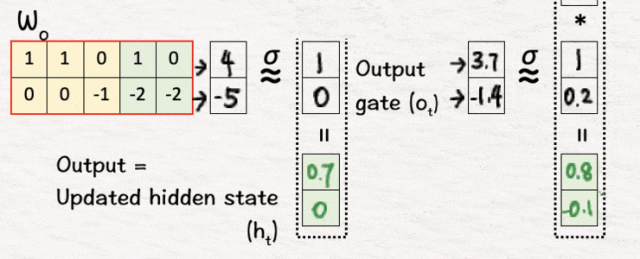
我们再次从上一次迭代中复制隐藏状态和内存,即 h2 和 C2。
[12] 线性变换
我们执行与步骤 2 相同的线性变换。
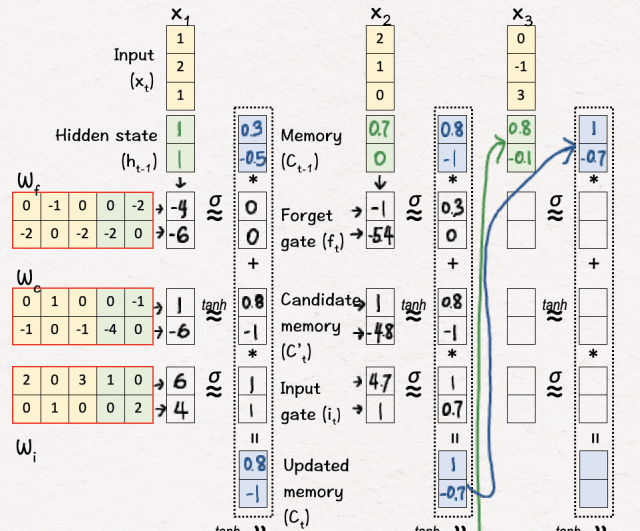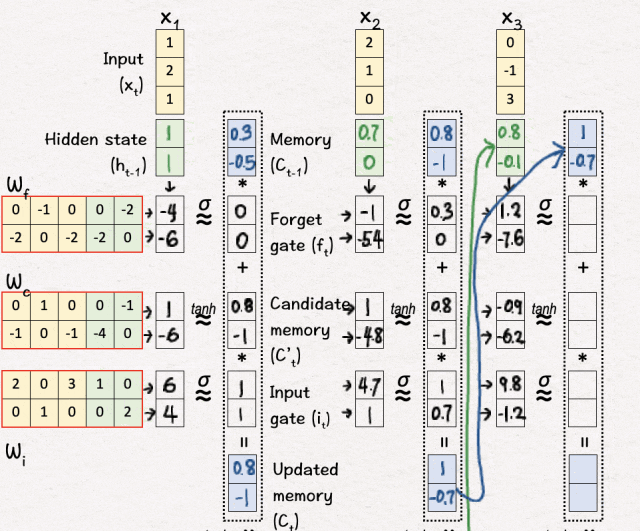
[13] 更新内存(C3)
接下来,我们执行非线性变换,并根据变换过程中获得的值执行内存更新。
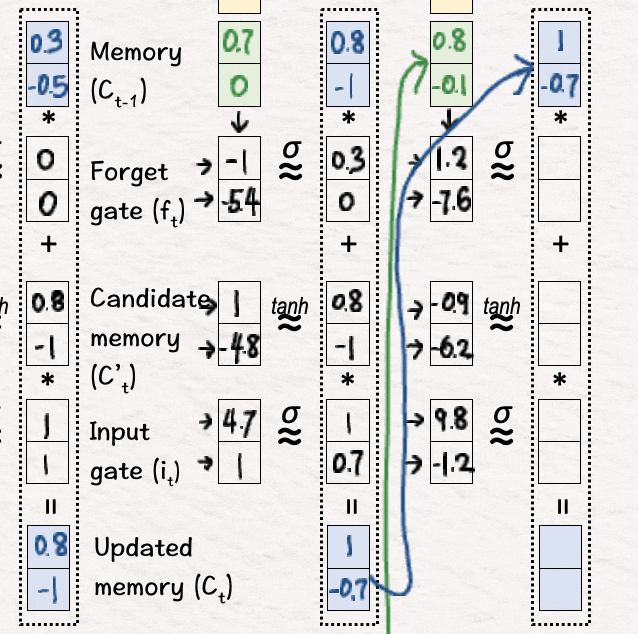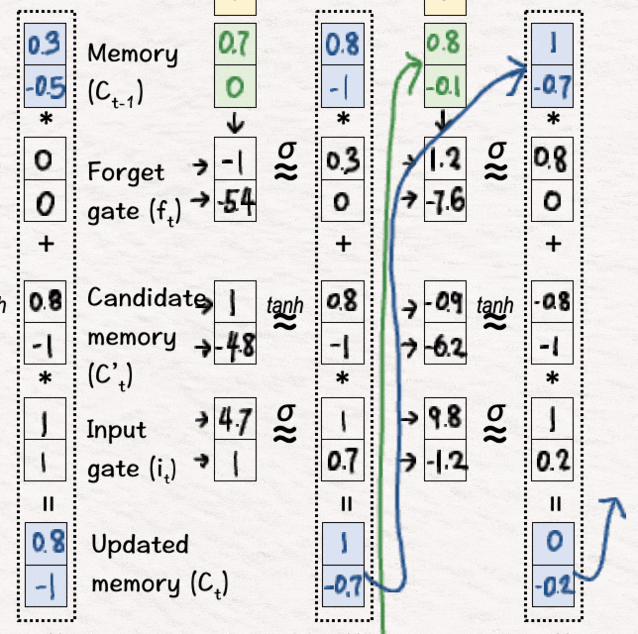
[14] 更新隐藏状态 (h3)
完成后,我们使用这些值来获取最终的隐藏状态 h3。
总结上述
总结上述工作,要记住的关键是 LSTM 依赖于三个主要门:输入、遗忘和输出。从名称中可以推断出,这些门控制信息的哪一部分以及其中有多少是相关的,哪些部分可以丢弃。
简而言之,执行此操作的步骤如下:
-
从先前状态初始化隐藏状态和内存值。
-
执行线性变换以帮助网络开始查看隐藏状态和内存值。
-
应用非线性变换(S 型和 tanh)来确定要保留/丢弃哪些值并获得新的候选内存值。
-
根据步骤 3 中的决策(获得的值),我们执行内存更新。
-
接下来,我们根据上一步中获得的内存更新确定输出将是什么样子。我们在这里获得一个候选输出。
-
我们将候选输出与步骤 3 中获得的门控输出值相结合,最终达到中间隐藏状态。
此循环继续进行所需的迭代次数。
xLSTM
对 xLSTM 的需求
当 LSTM 出现时,它们无疑为做一些以前没有做过的事情奠定了基础。循环神经网络可以有记忆,但记忆非常有限,因此 LSTM 诞生了——以支持长期依赖关系。然而,这还不够。因为将输入分析为序列会阻碍并行计算的使用,而且由于长期依赖关系会导致性能下降。
因此,Transformer 诞生了,作为解决所有问题的方案。但问题仍然存在——我们能否再次使用 LSTM,通过解决其局限性来实现 Transformer 的功能?为了回答这个问题,xLSTM 架构应运而生。
xLSTM 与 LSTM 有何不同?
xLSTM 可以看作是 LSTM 的一个非常进化的版本。LSTM 的底层结构在 xLSTM 中得到保留,但引入了新元素,有助于处理原始形式的缺点。
指数门控和标量内存混合 — sLSTM
最关键的区别是引入了指数门控。在 LSTM 中,当我们执行步骤 [3] 时,我们会对所有门引入 S 型门控,而对于 xLSTM,它已被指数门控取代。
例如:对于输入门 i1-
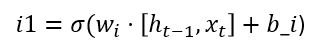
被替换为:
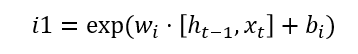
由于指数门控提供了更大的范围,xLSTM 能够比将输入压缩到 (0, 1) 范围的 S 形函数更好地处理更新。不过有一个问题——指数值可能会变得非常大。为了缓解这个问题,xLSTM 采用了规范化,下面等式中所示的对数函数在这里起着重要作用。
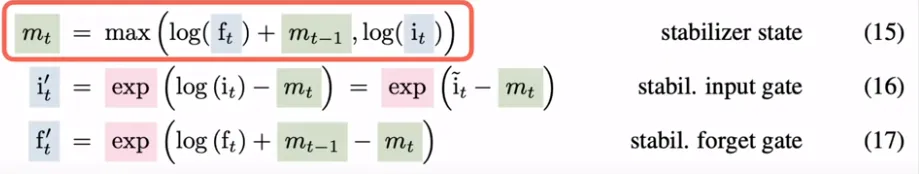
现在,对数确实会逆转指数的影响,但正如 xLSTM 论文所声称的那样,它们的联合应用为平衡状态指明了方向。
这种指数门控以及不同门控之间的内存混合(如原始 LSTM 中一样)构成了 sLSTM 块。
直到1948年1月,联邦仲裁法院才确认全体澳大利亚人每周工作5天,共工作40小时。
mLSTM
xLSTM 架构的另一个新方面是从标量内存增加到矩阵内存,这使其能够并行处理更多信息。它还通过引入键、查询和值向量并在规范化器状态中将它们用作键向量的加权和,与 Transformer 架构相似,其中每个键向量由输入和遗忘门加权。
sLSTM 和 mLSTM 块准备就绪后,使用残差连接将它们堆叠在一起,以产生 xLSTM 块,最后产生 xLSTM 架构。
因此,指数门控(具有适当的规范化)以及较新的内存结构的引入为 xLSTM 建立了强大的基础,以实现与 Transformer 类似的结果。
总结:
-
LSTM 是一种特殊的循环神经网络 (RNN),它允许将以前的信息连接到当前状态,就像我们人类对思想的持久性所做的那样。LSTM 之所以如此受欢迎,是因为它们能够回顾过去,而不是仅仅依赖于近期的过去。之所以能做到这一点,是因为在 RNN 架构中引入了特殊的门控元素 -
-
遗忘门:确定应保留或遗忘前一个单元状态中的哪些信息。通过有选择地遗忘不相关的过去信息,LSTM 可以保持长期依赖性。
-
输入门:确定应在单元状态中存储哪些新信息。通过控制单元状态的更新方式,它整合了对预测当前输出很重要的新信息。
-
输出门:确定应将哪些信息作为隐藏状态输出。通过有选择地将单元状态的部分作为输出,LSTM 可以为后续层提供相关信息,同时抑制不相关的细节,从而仅在较长的序列上传播重要信息。
-
2. xLSTM 是 LSTM 的演进版本,解决了 LSTM 面临的缺点。确实,LSTM 能够处理长期依赖关系,但信息是按顺序处理的,因此不具备当今 Transformer 所利用的并行能力。为了解决这个问题,xLSTM 引入了:
-
-
sLSTM:指数门控,与 S 形激活相比,它有助于包含更大的范围。
-
mLSTM:具有矩阵内存的新内存结构,可增强内存容量并提高信息检索效率。
-
LSTM 会卷土重来吗?
总体而言,LSTM 属于循环神经网络家族,以顺序方式递归处理信息。Transformers 的出现彻底消灭了循环的应用,然而,它们处理极长序列的困难仍然是一个迫切的问题。研究表明,二次时间与长距离或长上下文有关。
因此,探索至少可以启发解决方案的选项似乎值得,一个很好的起点就是回到 LSTM — 简而言之,LSTM 很有可能卷土重来。目前的 xLSTM 结果看起来确实很有希望。然后,总而言之 — Mamba 对循环的使用很好地证明了这可能是一条值得探索的有利可图的道路。


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











