






中文原生「语音合成」测评基准榜单发布!首期声音复刻榜单同步揭晓,豆包模型双榜夺冠!
原创 SuperCLUE CLUE中文语言理解测评基准 2024年12月12日 18:17 浙江

中文原生语音合成测评基准(SuperCLUE-TTS),旨在深入评估新一代语音模型的中文语音合成能力。该基准不仅全面衡量模型在准确性、清晰度、自然度和情感表现等基础能力方面的表现,还重点考察其在语音导航、有声读物、语音播报、内容配音、直播广告等场景应用的适用性。同时,本次测评还单独设置了声音复刻任务,选取了8种不同音色(4男声4女声,分别取自现实名人、网络红人、影视人物、卡通人物,每段素材时长约30秒),用以评估模型对声音的还原与模仿能力。
测评方案见:语音合成大模型测评基准(方案)发布。本次我们针对国内外10款代表性语音合成模型及5款声音复刻模型进行了全面评测,以下为详细测评报告。
![]()
语音合成测评摘要
测评要点1:中文语音合成领域国内模型表现优异,领跑评测基准。
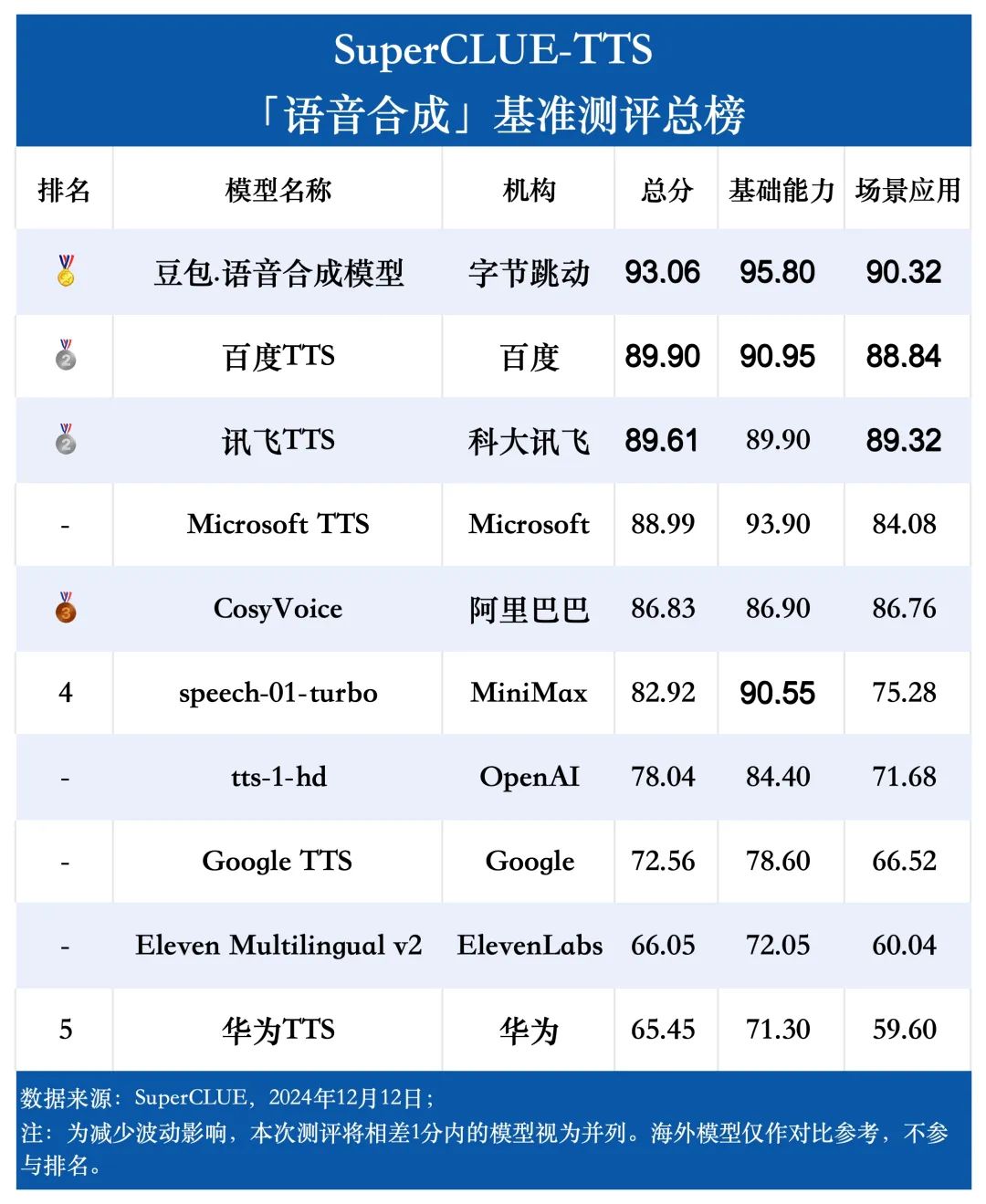
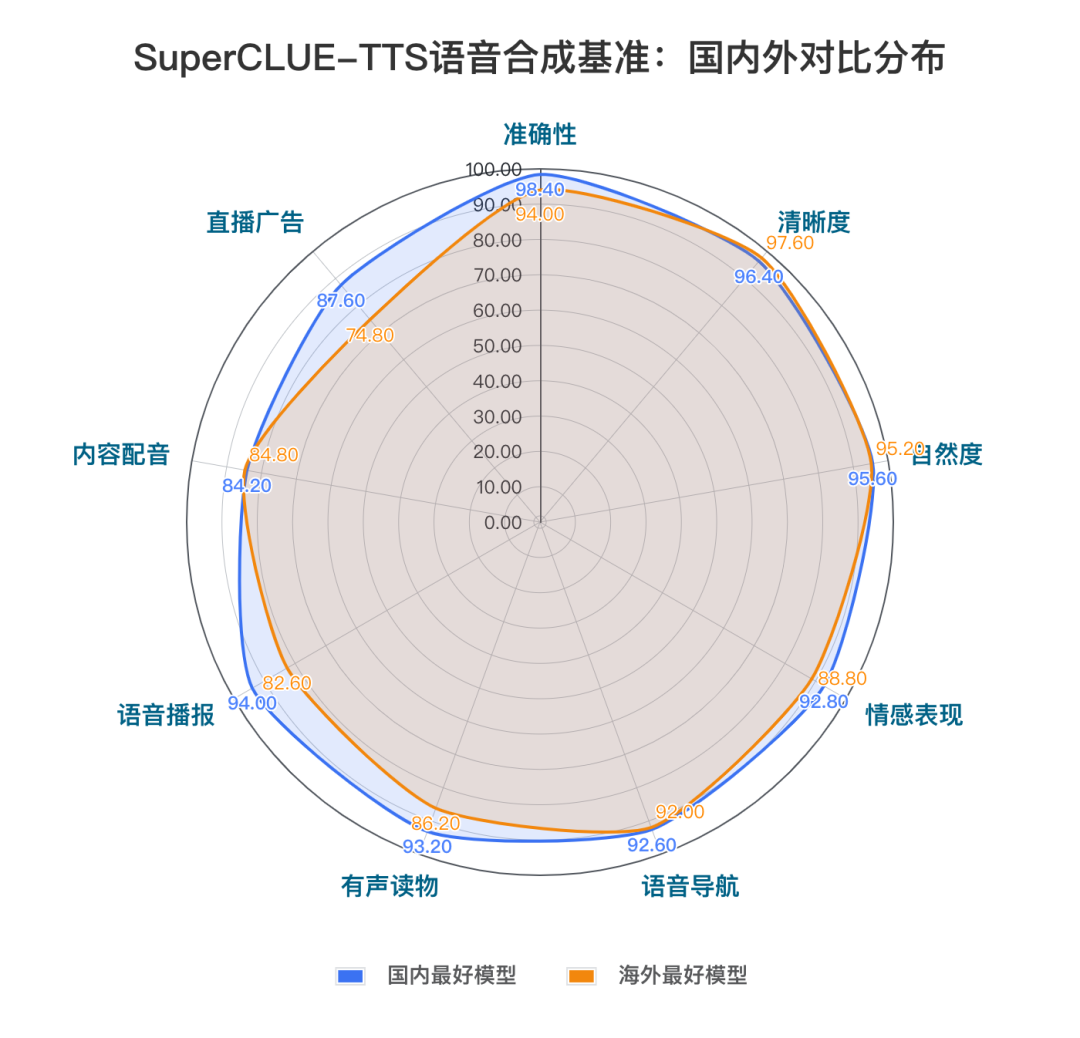
国内语音合成模型在中文任务上展现出显著优势,豆包模型以93.06分的成绩领跑SuperCLUE-TTS基准。百度TTS、讯飞TTS、CosyVoice以及speech-01-turbo等多个国内模型都表现不俗,其中百度TTS和讯飞TTS在合成准确性和清晰度等方面分别都有较好表现。相比之下,海外模型受限于中文语言特性的掌握程度,整体表现相对欠佳。这充分体现了国内厂商在中文语音处理领域的技术积累和优势地位。
测评要点2:新一代语音技术加持下,国内头部语音模型在自然度和情感表现方面有较大竞争力。
讯飞TTS、豆包.语音合成模型和CosyVoice等模型在自然度上均表现优异,具备较高的拟人化能力。相比之下,国外模型在中文语音处理中的表现略显不足,其语音自然度和流畅性稍逊于国内模型。值得一提的是,豆包.语音合成模型在情感表现方面尤为突出,能够更精准地展现文本中蕴含的情感和语调变化,而 speech-01-turbo 的情感表现同样颇具亮点。
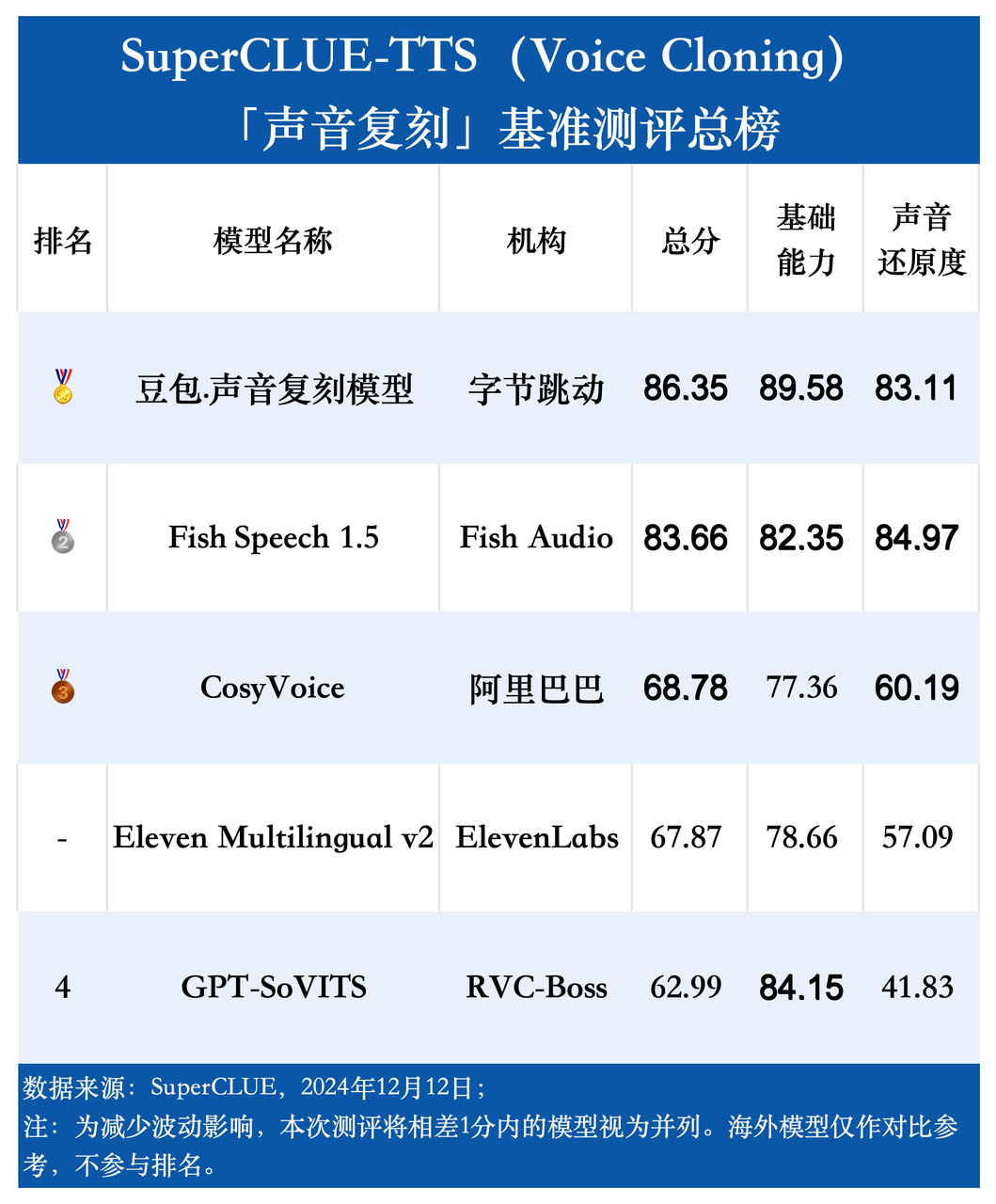
测评要点3:声音复刻模型在声音还原度方面表现各不相同,区分性较大。
GPT-SoVITS在情感表现方面具有一定的优势,但在声音还原度上的表现略显不足,合成稳定性仍有待提升;Fish Speech 1.5与豆包.声音复刻模型在声音还原度方面表现尤为突出,合成效果稳定,展现出明显的优势。整体来看,目前所有的模型在声音复刻的稳定性上仍有提升空间。
# 榜单概览
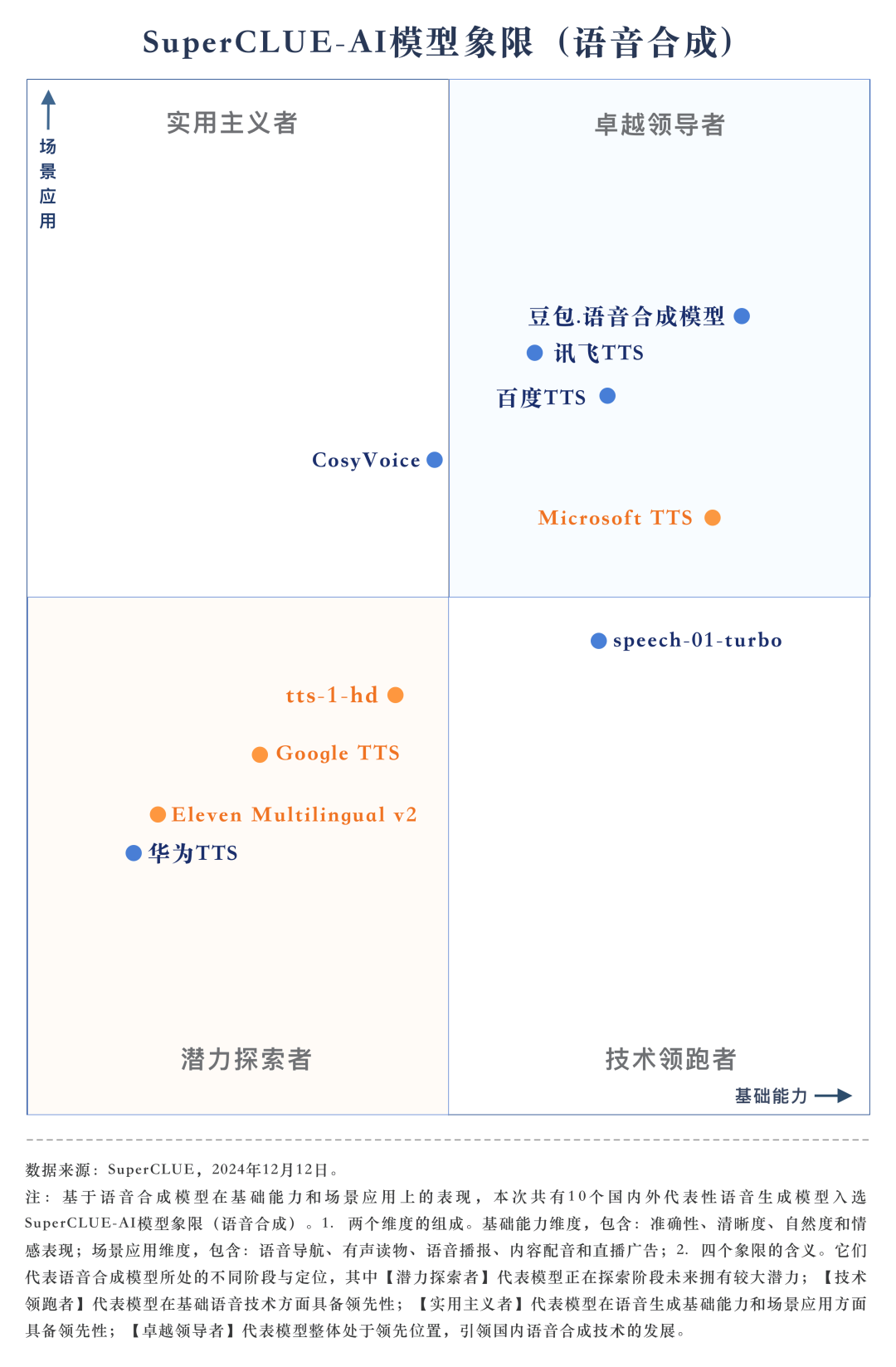
榜单地址:www.superclueai.com
详情请查看下方#正文。
#SuperCLUE-TTS介绍
SuperCLUE-TTS是专为中文语音合成任务设计的语音合成模型综合性评测基准,旨在为中文语音合成领域提供全面且多维度的模型能力评估参考。
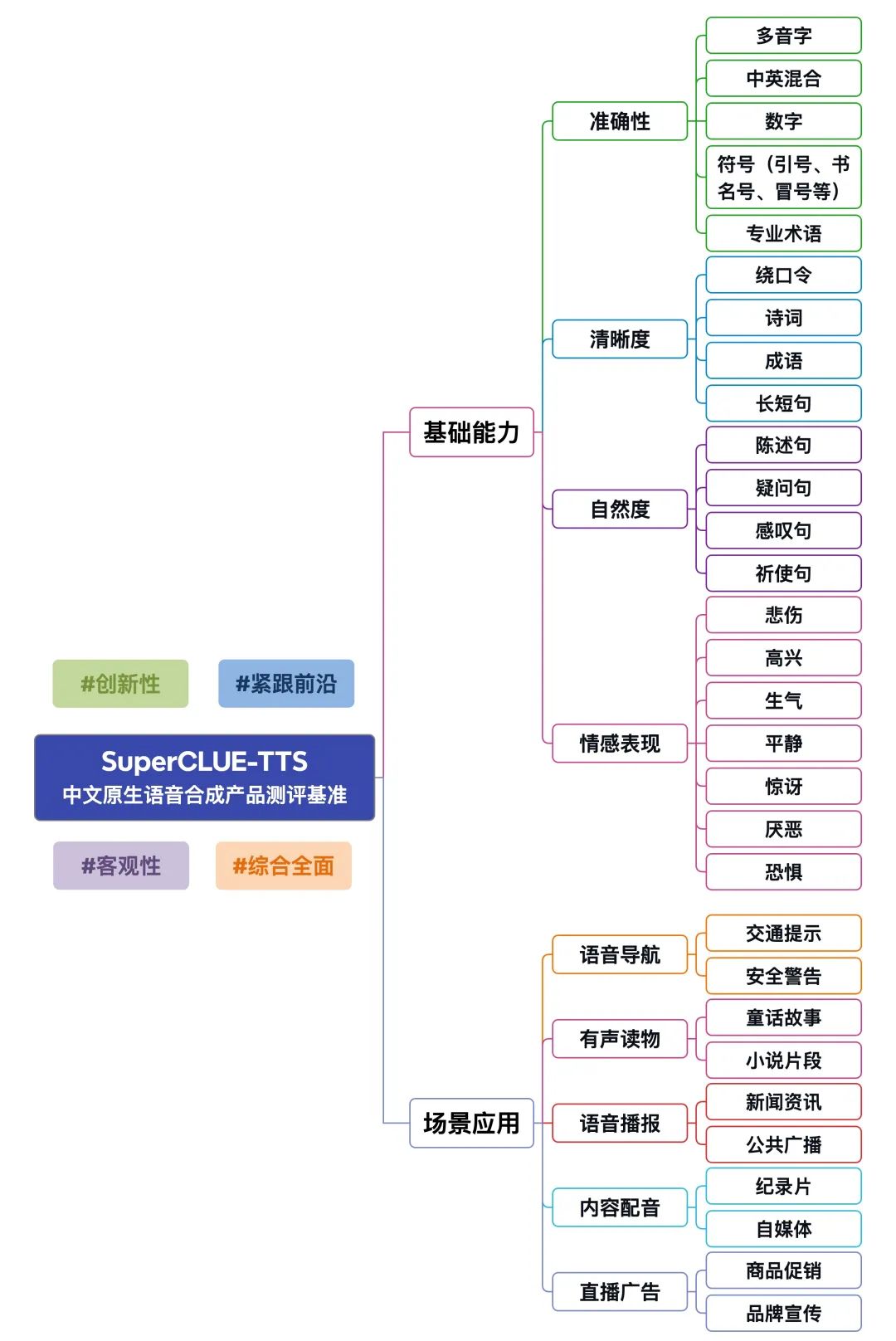
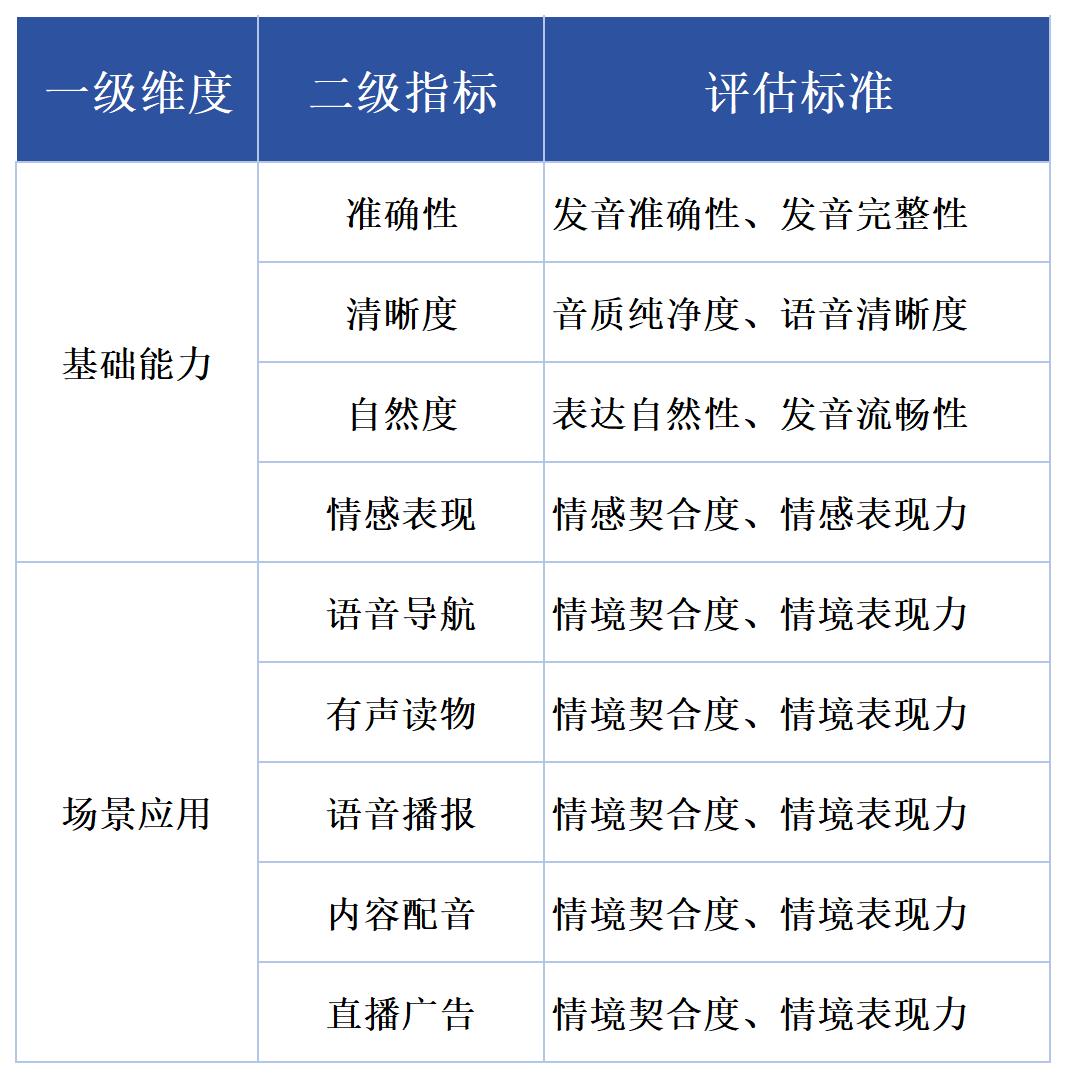
基础能力涵盖语音合成任务中必需具备的四项核心要素:准确性、清晰度、自然度以及情感表现。
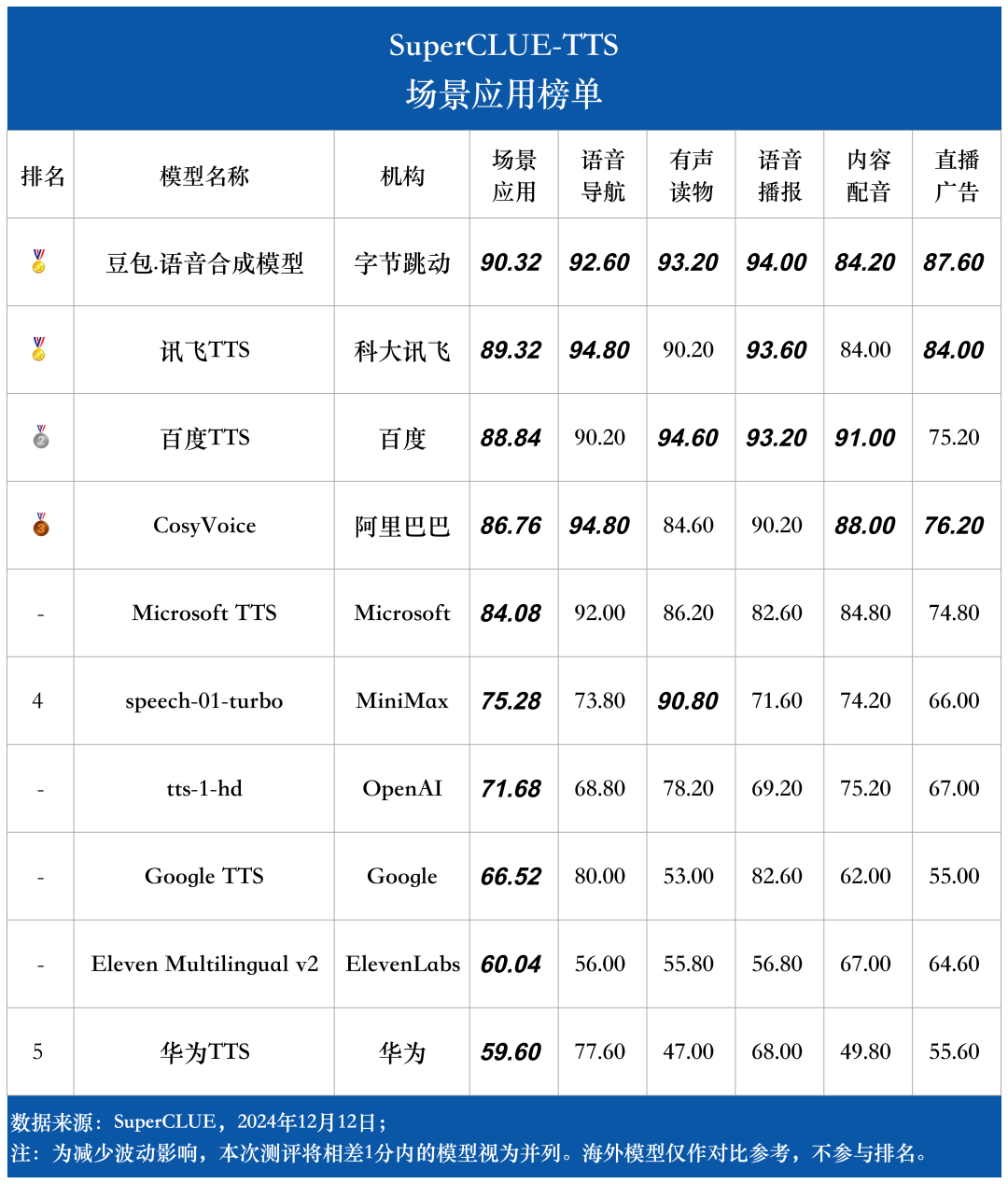
场景应用包括语音合成任务中的五大常见场景:语音导航、有声读物、语音播报、内容配音和直播广告。
测评方法
参考SuperCLUE细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息。
![]()
1)测评集构建
中文TTS文本材料构建流程:1.根据任务特点,撰写专项TTS文本--->2.测试--->3.修改并确定最终专项TTS文本--->4.针对每一个测评指标构建专用的测评集。
![]()
2)音频构建
每个模型(或产品)选取一个最具代表性的音色(开发文档中调用代码的默认音色、产品推荐的第一个音色),按照默认的参数合成测评集中文本的音频。
![]()
3)评分过程
经过反复实验与验证,我们最终决定采用人工评估的方法,由经过培训的评估人员严格按照评价标准和评分细则,并结合主观感受,对生成音频的合成效果进行全面评估。每个评估指标分为5个分数等级,分别为优秀、良好、一般、较差、极差。
评价标准
评分细则
1.准确性
发音准确性:评估音频中的发音是否符合标准发音规则,是否存在错误发音或误读现象。
发音完整性:评估音频中是否存在音节、词语或句子的遗漏,确保每个语音单位的发音均完整。
2.清晰度
音质纯净度:评估音频中是否存在如电噪、背景噪音或其他干扰因素,影响音质的纯净性。
语音清晰度:评估音频中发音的清晰度,确保每个音节、字的发音清楚明了,没有模糊不清或含混不清的现象。
3.自然度
表达自然性:评估音频中的自然韵律是否符合语言习惯,语调、及重音变化是否合理,语气是否到位,是否不存在声音过于机械或矫揉造作的现象。
发音流畅性:评估音频中的声音是否自然顺畅,节奏是否自然且有变化,无明显的卡顿、停顿或语速不一致,是否连贯且易于理解。
4.情感表现
情感契合度:评估音频中的情感表达是否与文本内容的情感语境相符,是否能够准确传达内容的情感特征。
情感表现力:评估音频中情感表达的力度和细腻程度,是否能够有效传达情感的强度和层次,使听者感受到丰富的情感变化。
5.场景应用
情境契合度:评估音频中的语气、语调、音色等是否与该场景的预期风格一致,音频是否符合场景要求的氛围。
情境表现力:评估音频在不同场景下对内容生动性和适应性的表达程度,是否能够通过适当的语调、节奏和音色变化,有效支持场景需求。
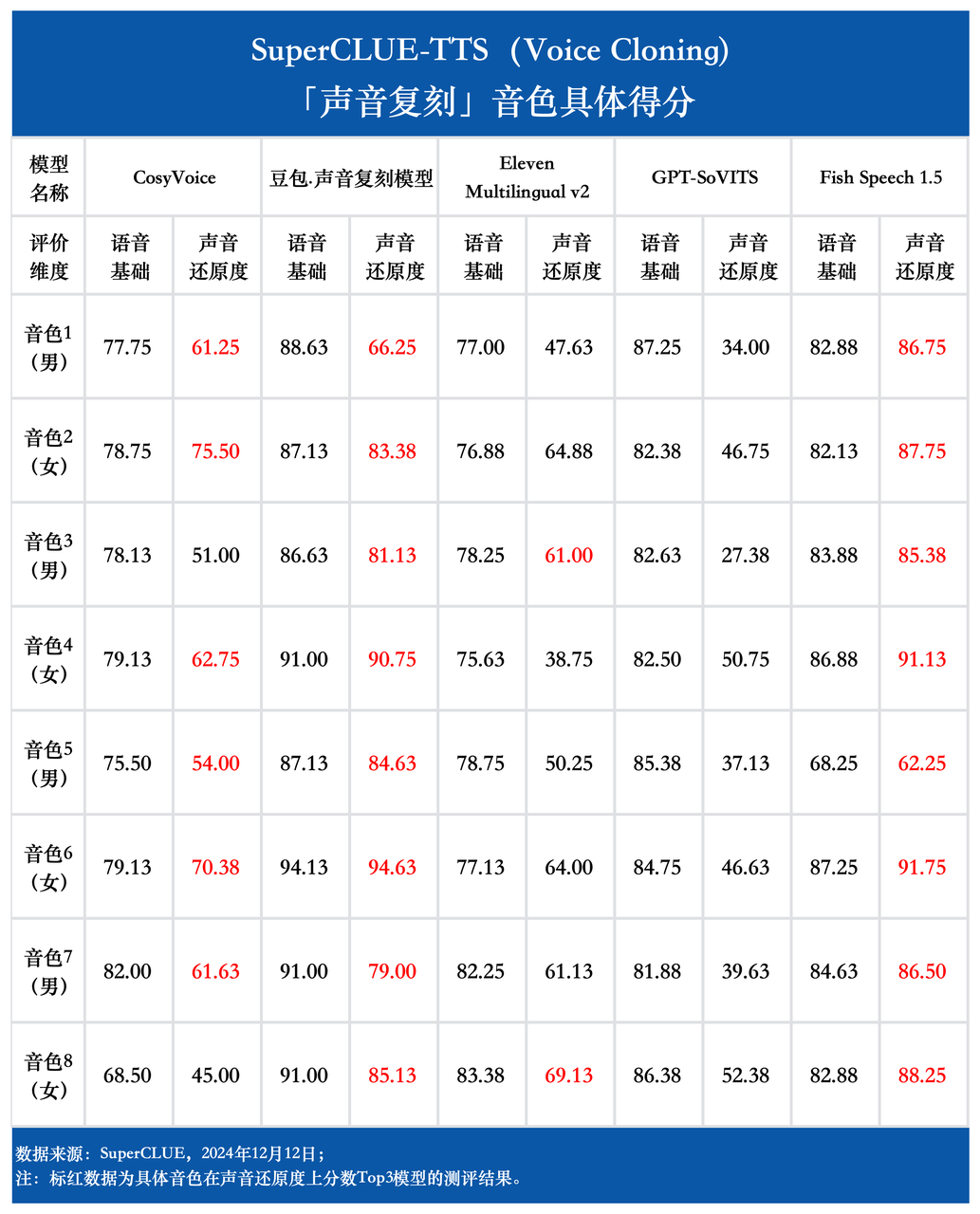
6.声音还原度(声音复刻)
音色相似度:评估复刻声音与原音频在音色上的相似程度,包括音质、音高、音色特征等。
语气一致性:评估复刻声音与原音频在语气、情感表达及语音细节上的一致性,包括语调、语速、停顿、拖音、情感强度等。
测评示例
维度:情感表现-生气
提示词Prompt:「这太过分了!为什么每次都是我承担所有的后果?我真的受够了这种不公平的对待!」
模型回答:
测评示例,CLUE中文语言理解测评基准,6秒
评分:
情感契合度(人工平均分):4.75分
情感表现力(人工平均分):4.50分
最终得分(满分5分):
(4.75+4.50)/2 = 4.625分
# 参评模型
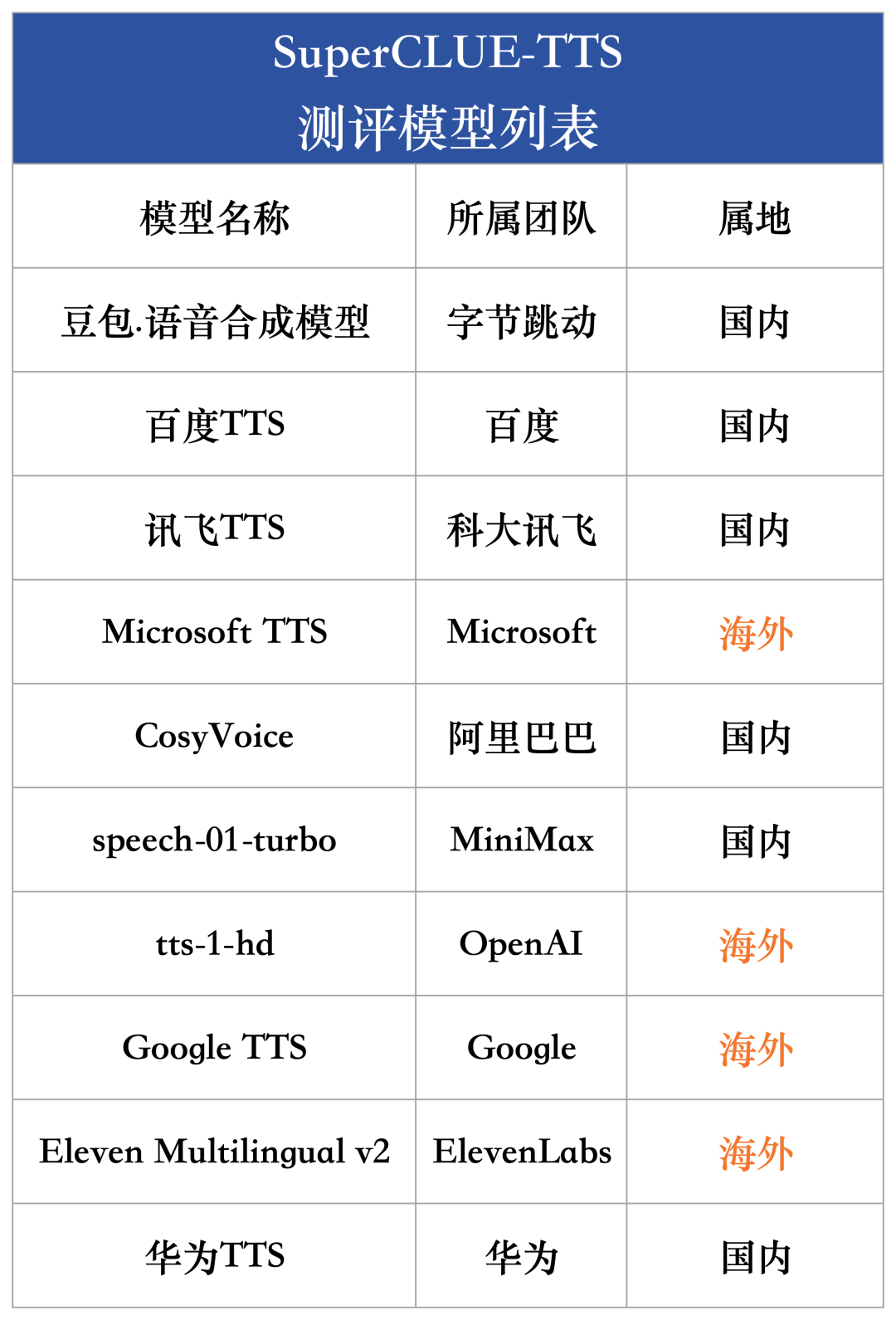
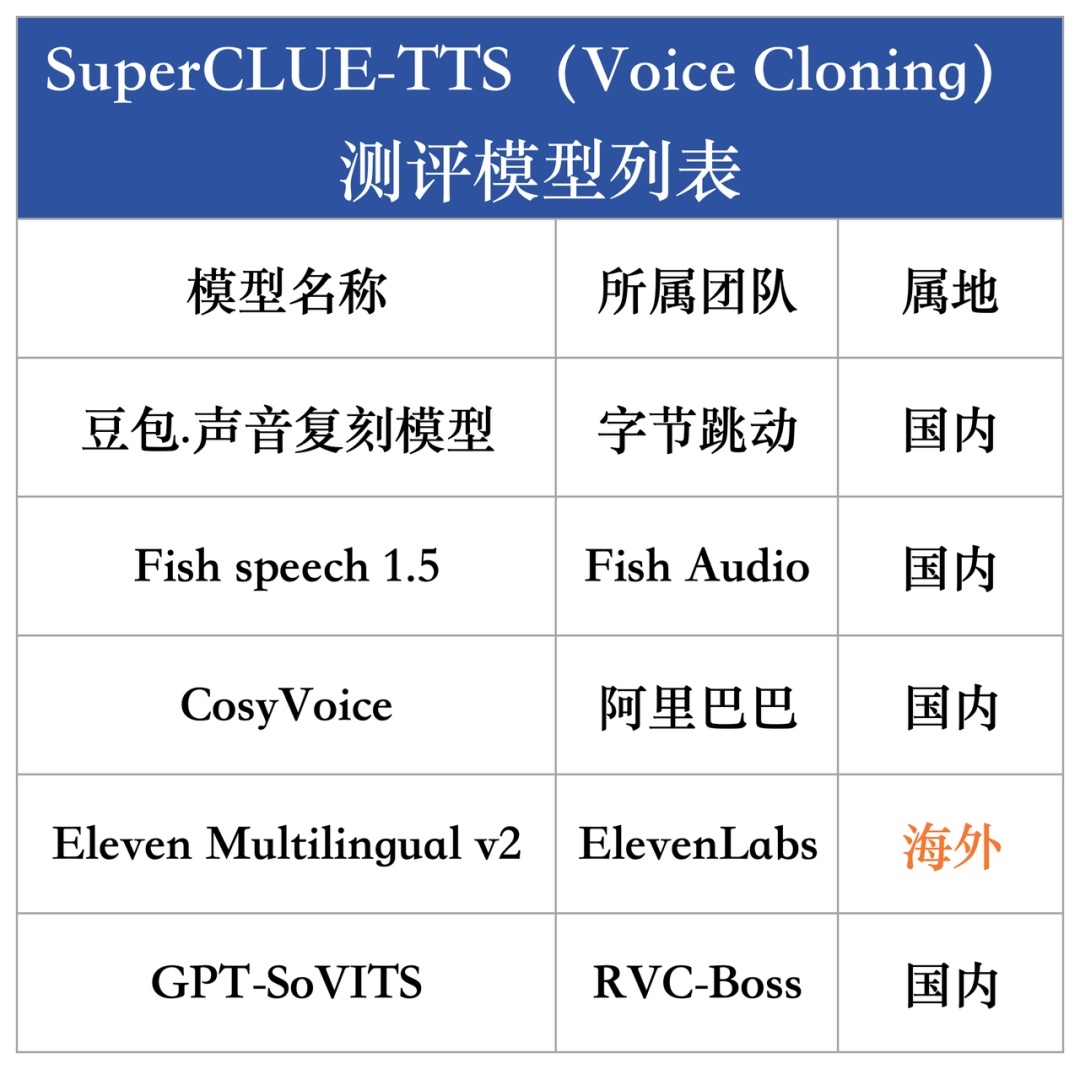
为综合衡量当前国内外大模型在语音合成能力的发展水平,本次评测选取了国内外具有代表性的10款语音合成模型和5款声音复刻模型。
一、语音合成
二、声音复刻
# 测评结果
一、语音合成
总榜单
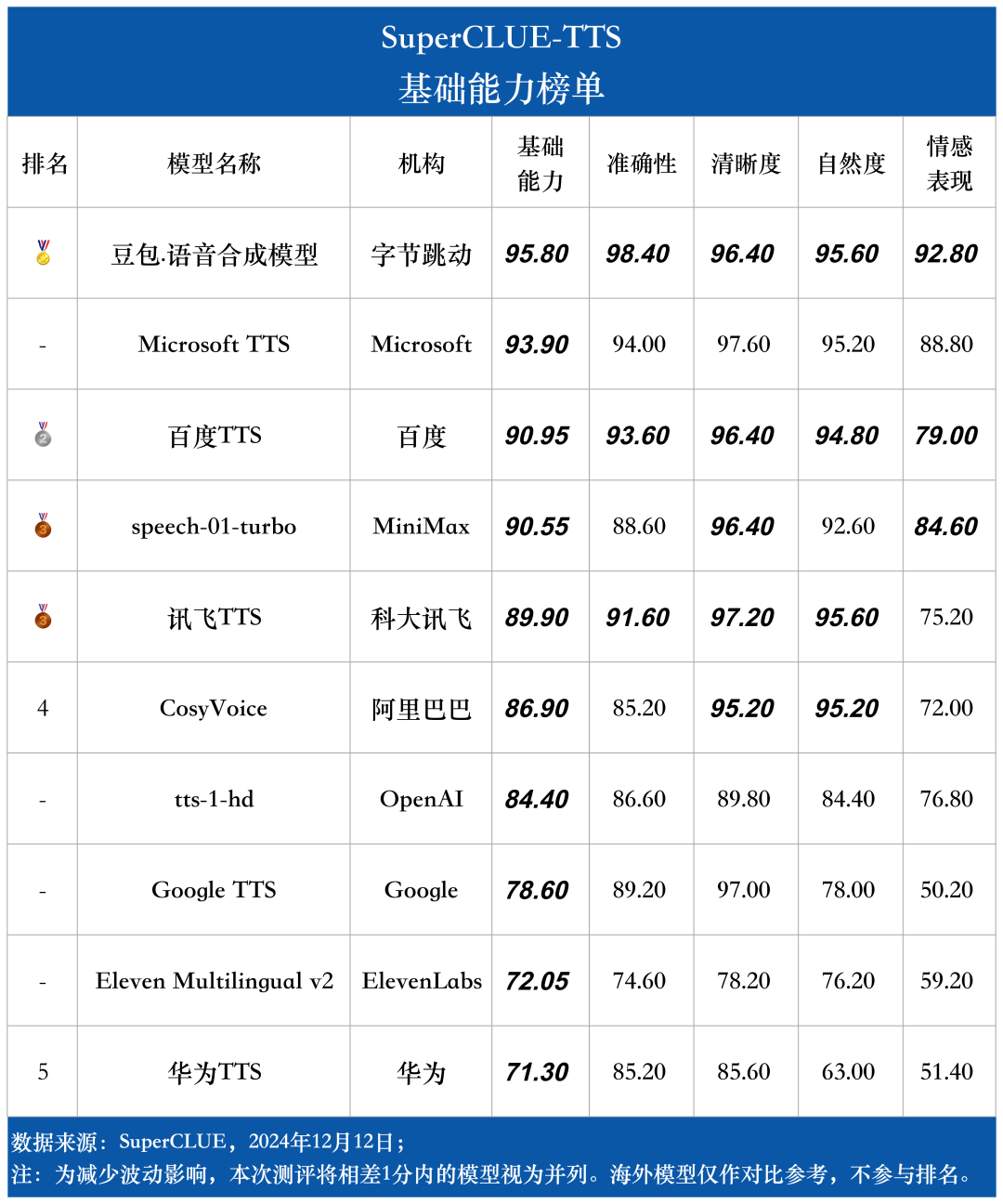
基础能力榜单
场景应用榜单
二、声音复刻
总榜单
音色具体得分
# 模型对比示例
一、语音合成
#示例1 基础能力-自然度
提示词Prompt:「哇!昨晚的烟花表演真是美轮美奂,每一束火花在夜空中绽放,仿佛点亮了整个城市的夜晚。」
模型回答比较:
【讯飞TTS示例】:整体表现较为自然流畅。
【得分】:4.75分
讯飞TTS-自然度,CLUE中文语言理解测评基准,8秒
【华为TTS示例】:声音机械感明显,有一定优化空间。
【得分】:3.00分
华为TTS-自然度,CLUE中文语言理解测评基准,8秒
#示例2 基础能力-情感表现
提示词Prompt:「别过来,求求你别过来!你到底想干什么?!我……我真的没做什么啊!你别动,求求你别再靠近了!」
模型回答比较:
【豆包.语音合成模型示例】:情感表现与文本契合度较高。
【得分】:4.86分
豆包.语音合成模型-情感表现,CLUE中文语言理解测评基准,7秒
【CosyVoice示例】:情感略显平淡,有一定优化空间。
【得分】:2.63分
CosyVoice-情感表现,CLUE中文语言理解测评基准,5秒
#示例3 场景应用-有声读物
提示词Prompt:
「我接下来要朗读一个小说片段:
他哭着,却又高兴起来。
好像直到这一刻,他才算真正地回了家。
他把装了信的铜匣埋在了那棵树下,然后对闻时、谢问深深行了个大礼说:"我可以走了。"
说着他便甘心闭上了眼。他能感觉到自己正在慢慢消散,融进这烟雾般的雨里。就在他消失前的最后一刻,他听见闻时问了一句:"如果能留下一点东西,你想变成什么。"
李先生想也没想:"鸟吧。"
他看见闻时点了一下头,说:"好。"
教书先生再无踪影,没过多久,闻时用他残留的一缕尘缘捻出了一只飞鸟。
它跟田野间低空飞过的鸟雀别无二样,只是没在任何一处屋檐停留,而是径直飞落到了那棵弯曲的树里。」
【speech-01-turbo】示例:
【得分】:4.75分
speech-01-turbo-有声读物,CLUE中文语言理解测评基准,1分钟
#示例4 场景应用-语音播报
提示词Prompt:「我接下来要播报一条公共广播:各位旅客,请注意,火车站一楼大厅的服务台已迁移至二楼,请前往新的位置办理相关服务。感谢您的配合,祝您旅途愉快!」
【百度TTS】示例:
【得分】:4.63分
百度TTS-语音播报,CLUE中文语言理解测评基准,14秒
二、声音复刻
#示例1 罗翔老师
提示词Prompt:「真是太不可思议了!这座老建筑经过百年的风雨侵蚀,依然屹立不倒,展现出惊人的坚韧与美丽。」
【Fish Speech 1.5】示例:
【得分】:4.50分
Fish Speech 1.5-罗翔音色复刻示例,CLUE中文语言理解测评基准,8秒
#示例2 林黛玉
提示词Prompt:「我来竟何事?高卧沙丘城。城边有古树,日夕连秋声。」
【豆包.声音复刻模型】示例:
【得分】:4.75分
豆包.声音复刻模型-林黛玉音色复刻示例,CLUE中文语言理解测评基准,7秒
# 测评分析及结论
1.中文语音合成领域国内模型表现优异,领跑评测基准。
测评结果显示,国内语音合成模型在中文任务上展现出显著优势,豆包.语音合成模型(93.06分)综合能力表现出色,领跑SuperCLUE-TTS基准。
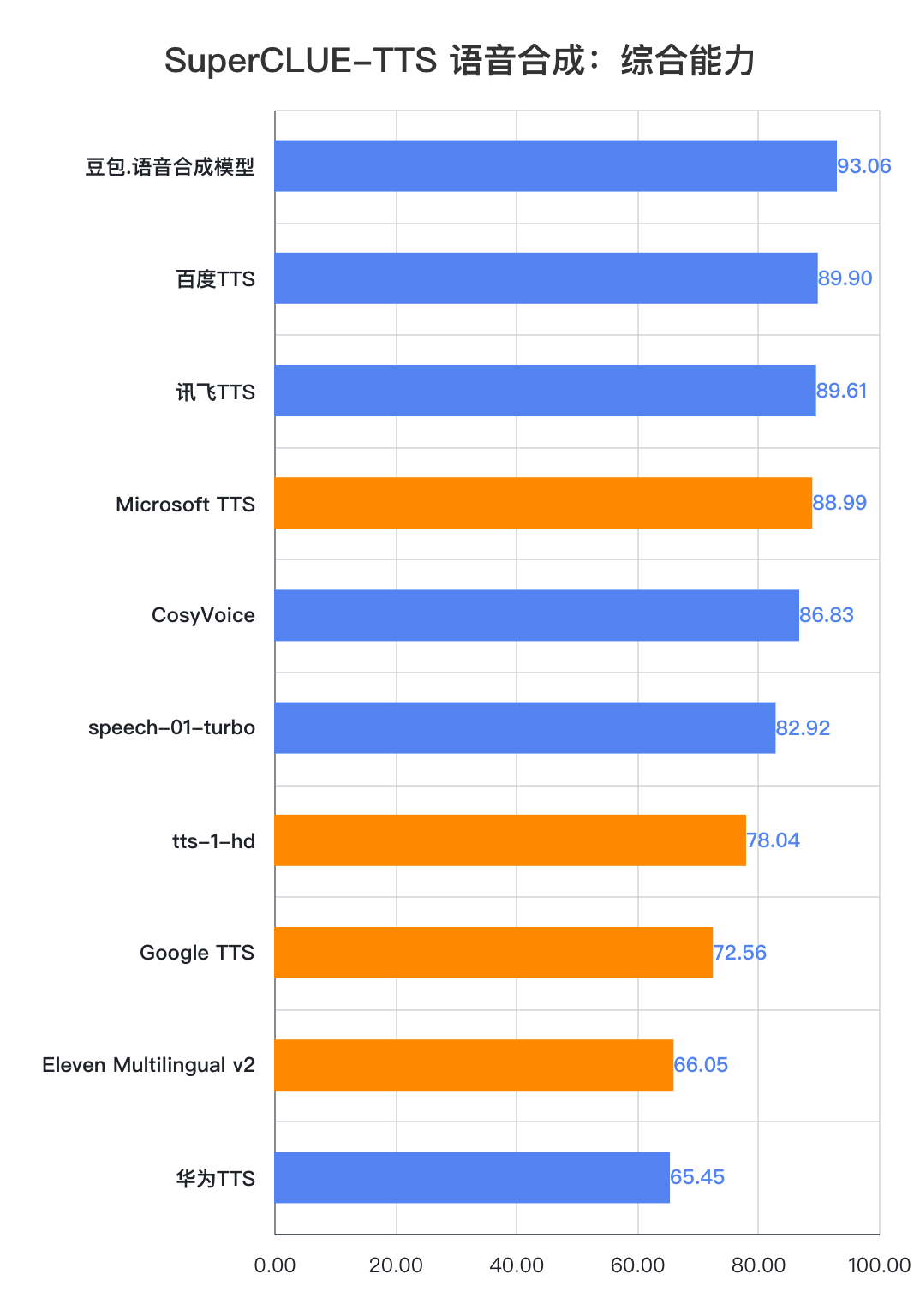
百度TTS、讯飞TTS、CosyVoice以及speech-01-turbo等多个国内模型都表现不俗。相比之下,海外模型受限于中文语言特性的掌握程度,整体表现相对欠佳。这充分体现了国内厂商在中文语音处理领域的技术积累和优势地位。
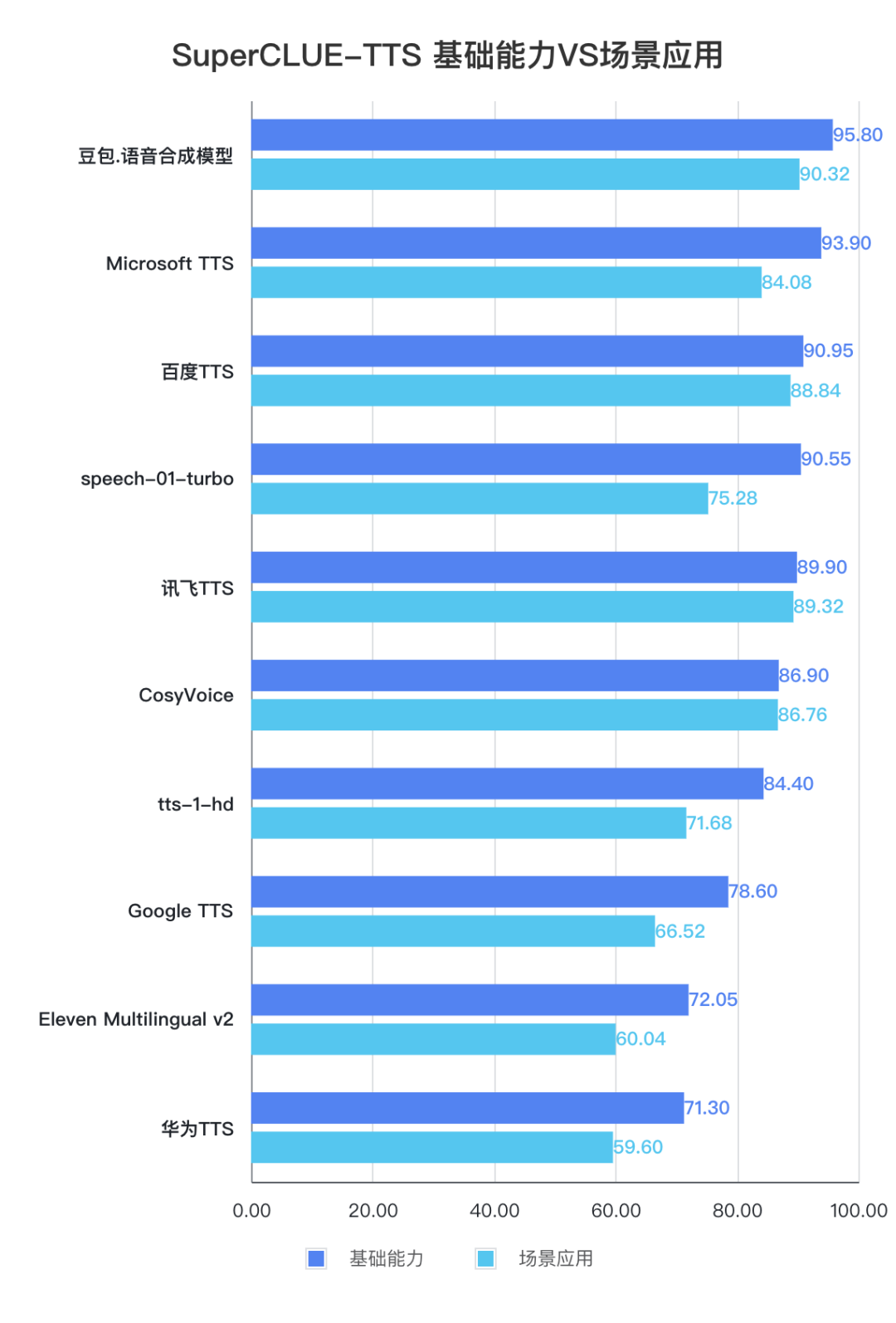
其中,百度TTS和讯飞TTS在合成准确性和清晰度等方面分别都有较好表现。
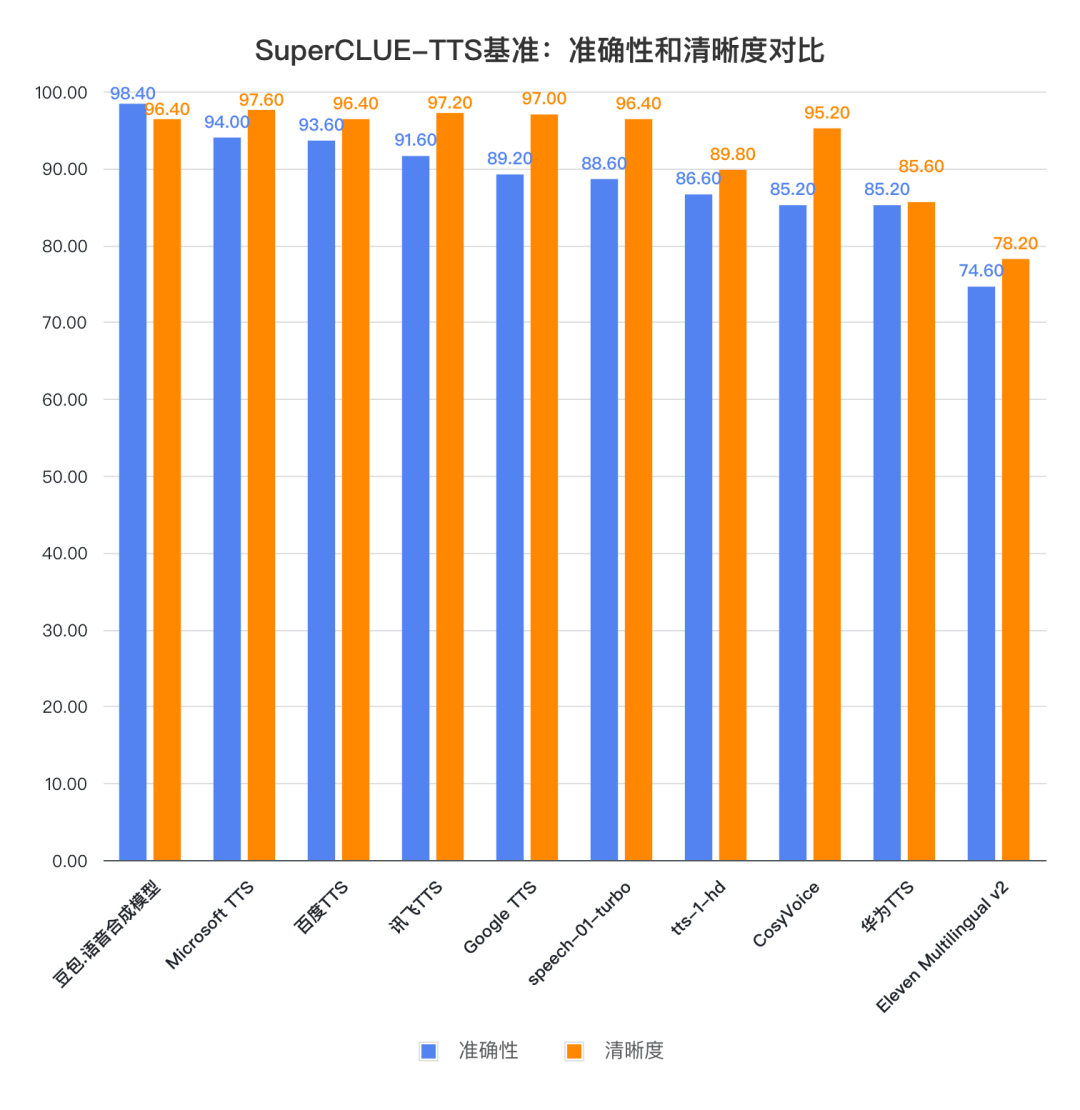
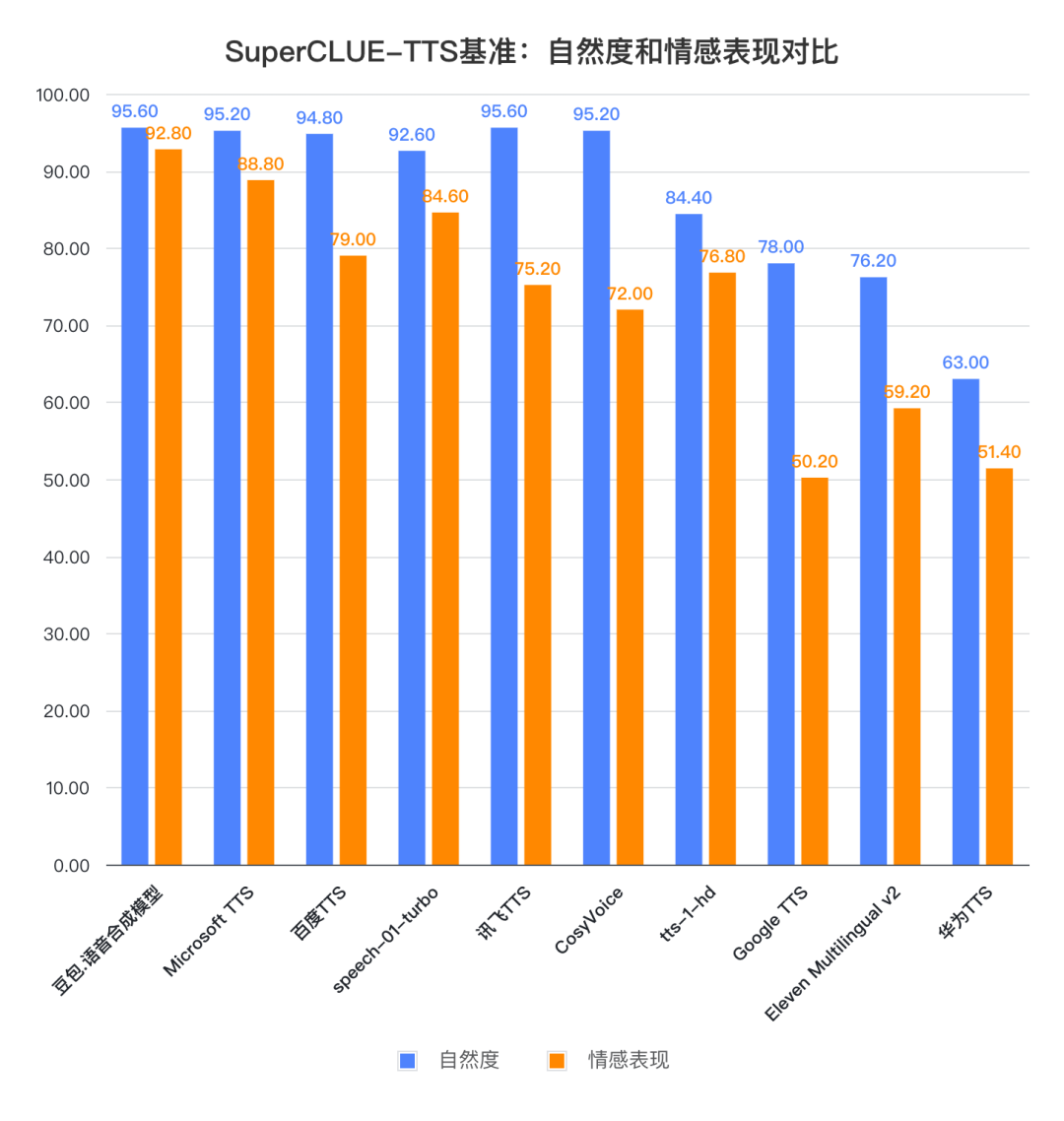
2.新一代语音技术加持下,国内头部语音模型在自然度和情感表现方面有较大竞争力。
整体来看,讯飞TTS、豆包.语音合成模型和CosyVoice等模型在自然度上均表现优异,具备较高的拟人化能力。相比之下,国外模型在中文语音处理中的表现略显不足,其语音自然度和流畅性稍逊于国内模型。值得一提的是,豆包.语音合成模型在情感表现方面尤为突出,能够更精准地展现文本中蕴含的情感和语调变化,而 speech-01-turbo 的情感表现同样颇具亮点。
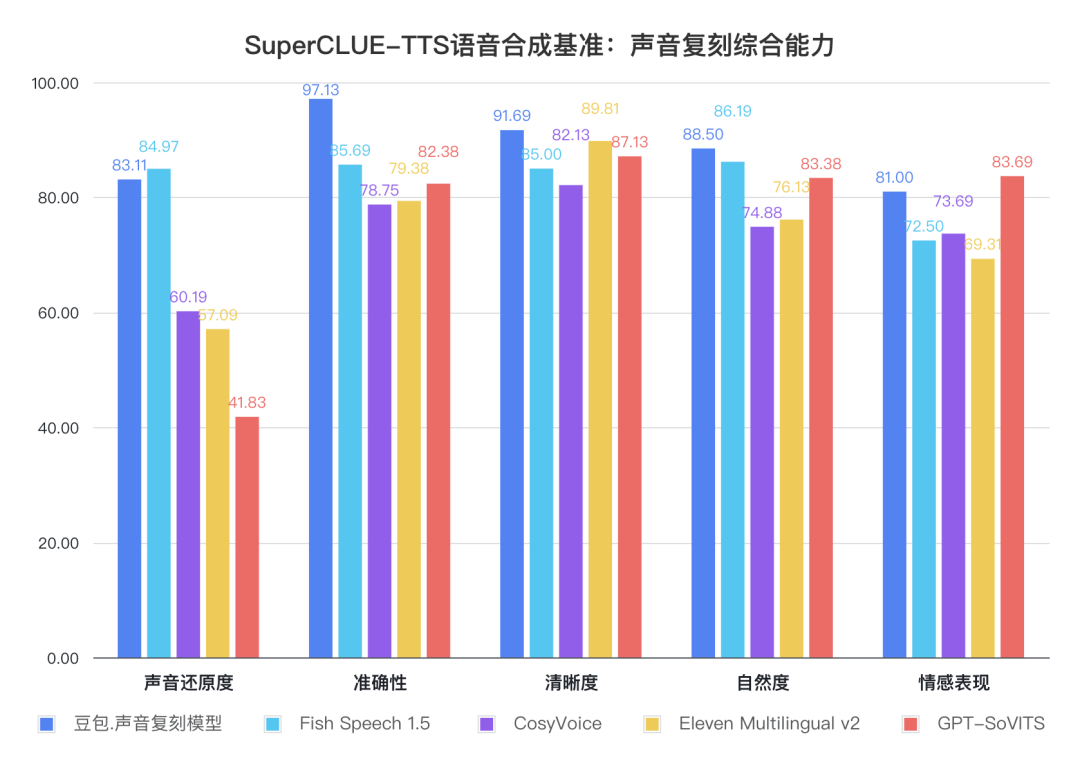
3.声音复刻模型在声音还原度方面表现各不相同,区分性较大
评测结果显示,GPT-SoVITS在情感表现方面具有一定的优势,但在声音还原度上的表现略显不足,合成稳定性仍有待提升;Fish Speech 1.5与豆包.声音复刻模型在声音还原度方面表现尤为突出,合成效果稳定,展现出明显的优势。整体来看,目前所有的模型在声音复刻的稳定性上仍有提升空间。
# 测评邀请
参与流程
1. 邮件申请
2. 意向沟通
3. 参测确认与协议流程
4. 提供测评API接口或大模型
5. 公开测评报告
# 邮件申请
邮件标题:
邮件标题:SuperCLUE-TTS语音合成测评申请,发送到


















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











