






毫无疑问,2025 年将会是强化学习之年
原创 艾木三号 Mindstorms 2025年02月08日 19:30 山东
大模型的所有智能来源于数据[1]。我们可以从两个方面来看待智能:知识和思维。
DeepSeek 的“啊哈时刻”
在训练 DeepSeek-R1-Zero 的过程中,DeepSeek 团队从大模型的思考过程中观察到一个奇妙的现象:模型在解决复杂的数学问题的时候,会用拟人化的语气进行思考,它会自我评估,会暂停下来进行反思,它甚至会像人一样使用“aha”这样的词表达发现的喜悦。

DeepSeek 团队认为,这个时刻不仅仅是大模型的“啊哈时刻”,同时也是研究团队的“啊哈时刻”,因为大模型的这一表现展示出了“强化学习的力量与美感”[2]。
R1-Zero[3] 是一个在基础模型上直接做强化学习而训练出来的版本,没有经过微调,也没有经过与人类偏好的对齐训练。也就是说,大模型在没有人类引导的情况下,仅仅通过强化学习就自己学会了“深度思考”。
这是 AI 范式的变革。OpenAI o1/o3、DeepSeek-R1、Kimi k1.5 都是这一新范式的代表[4]。
毫无疑问,2025 年将会是 RL 之年。
这个“啊哈时刻”有多啊哈?
我尝试在 DeepSeek-R1-Zero 上复现这个“啊哈时刻”。
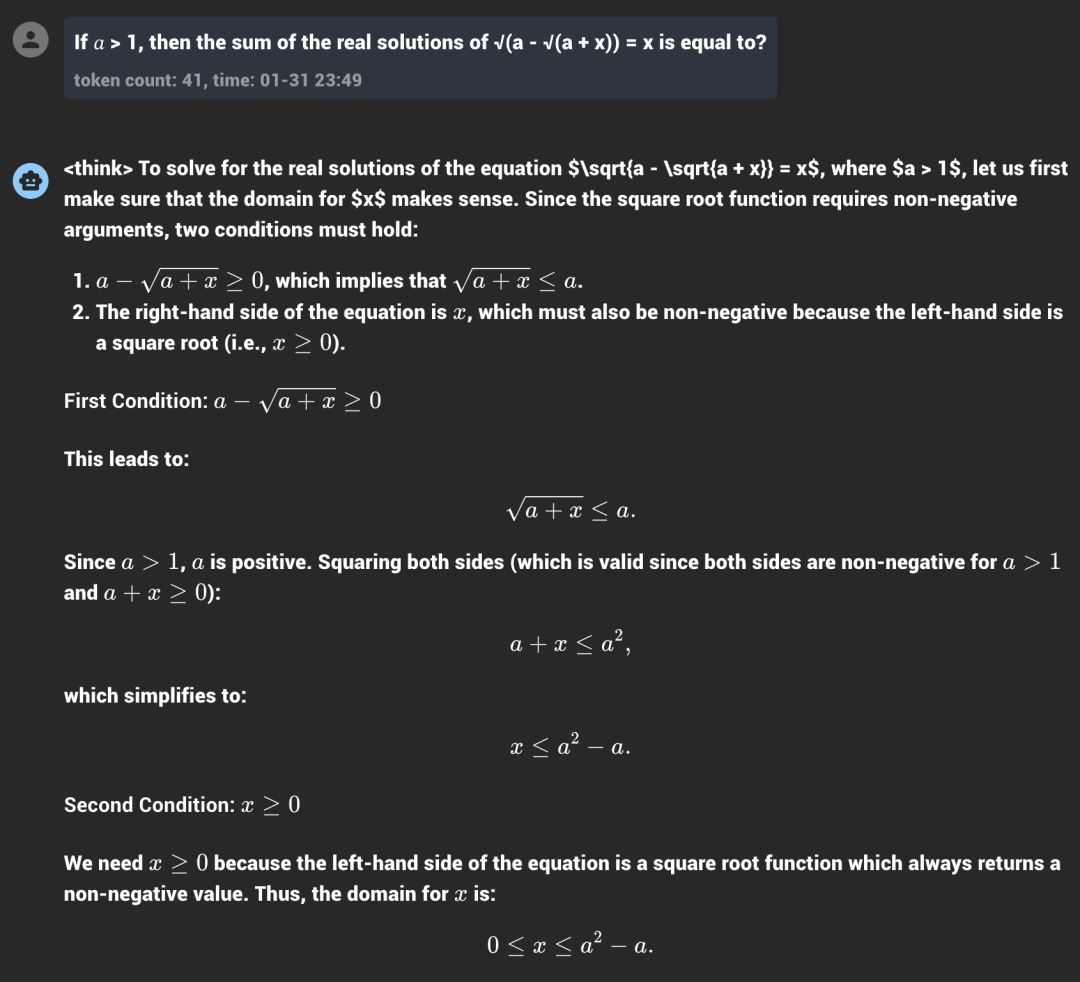
虽然过程中没有出现“啊哈时刻”,但是 R1-Zero 在解决问题的时候确实是表现出了很强的“深度思考”能力。
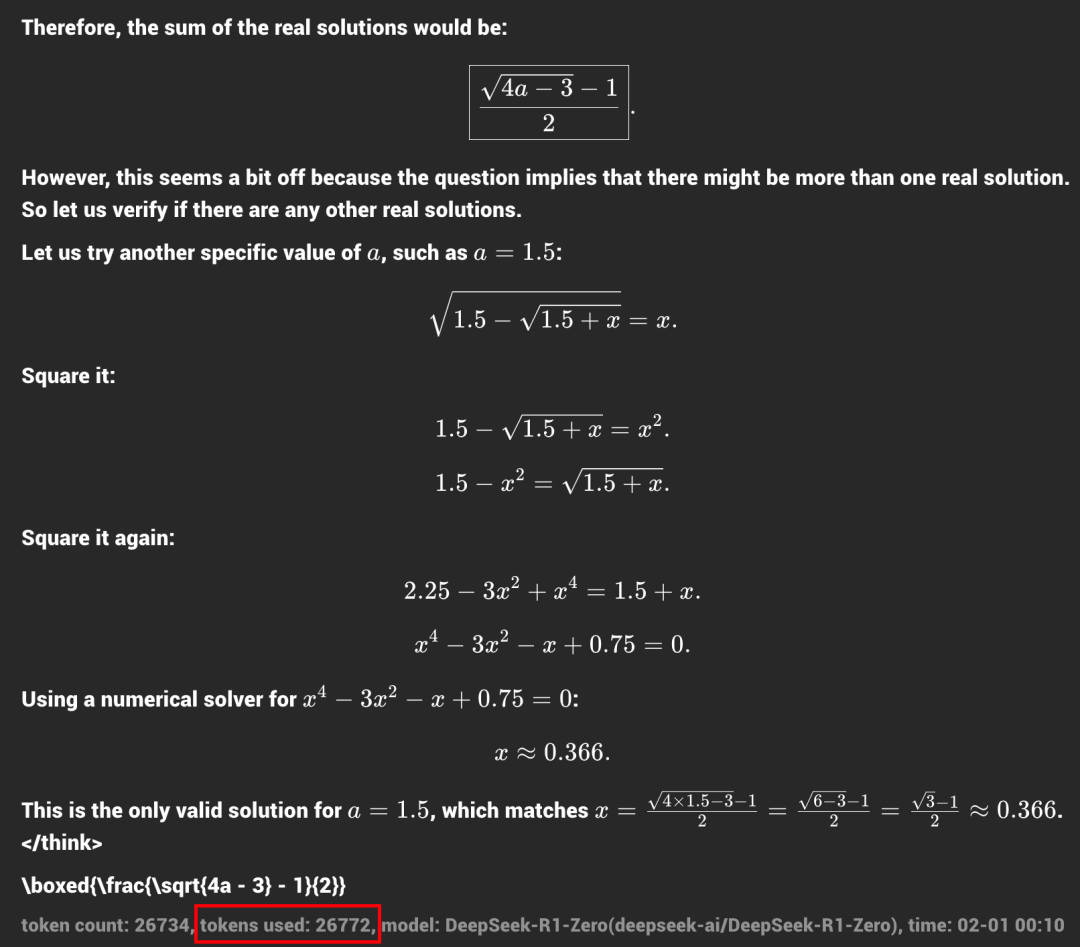
首先,可以看到大模型的思维链(Chain-of-Thought)变得超级超级长。R1-Zero 在解这个数学题的时候,整个输出部分消耗掉了 26.7K 的 Token。这是什么概念?Claude Sonnet 最大的输出长度才是 8K。据 DeepSeek 的论文描述,大模型是在强化学习训练过程中,“自主掌握了通过增加思考时间来渐进解决复杂推理任务的能力”[2]。
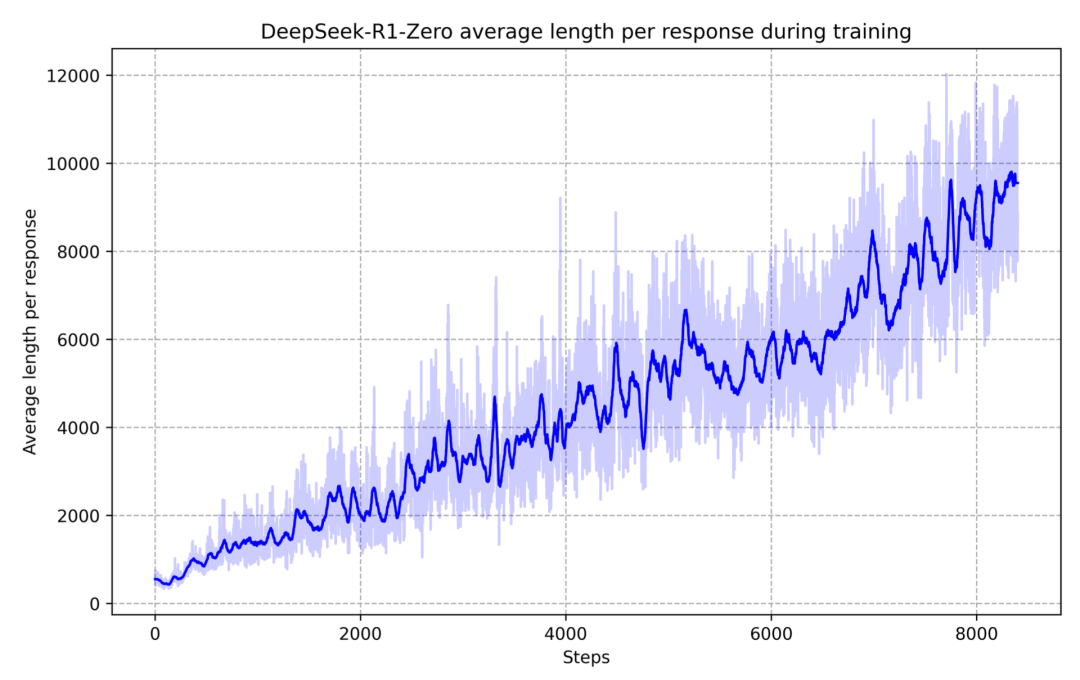
DeepSeek-R1-Zero 在强化学习训练过程中于训练集上的平均响应长度变化
把输出上下文窗口扩充得足够长,在推理时投入更多的计算,是实现“深度思考”的基本条件。而“深度思考”也确实带来了性能的大幅提升。这也就是 OpenAI 所说的,第二种规模定律(Scaling Law)[5]。
其次,我们可以看到 R1-Zero 在解决问题的过程中使用了很多高级的思维策略。比如,一步一步思考,或者叫规划(Planning):

比如,自我评估(Evaluation):

比如,自我反思(Reflection):

比如,探索多种可能(Exploration):


这些思维策略都是非常通用且非常重要的策略,意味着我们人类在解决任何复杂问题的时候,都可能需要用到。它们也是大模型去模拟人类进行推理的关键认知过程,Kimi 的论文里总结的很好:在规划(Planning)阶段,模型建立系统性执行预案;在评估(Evaluation)阶段,进行中间步骤的批判性验证;在反思(Reflection)阶段,支持策略的重构与优化;在探索(Exploration)阶段,激发多路径解决方案的生成[6]。
看到这里,你“啊哈”了么?我想你可能不仅感受到“啊哈”,甚至想要惊呼——“AI 要成精啦!”
要知道这是 R1-Zero,这些思维策略不是人类显性地“教”给大模型的,都是大模型在强化学习训练过程中自主探索和学习到的。
难道 DeepSeek 真的找到了让 AI 超越人类的办法?人类将再次想起被 AlphaGo 碾压的恐惧?这一次 AI 不仅是在围棋领域,而是将在所有领域全面碾压人类?
大模型的知识从何处来?
大模型的知识从何处来?让我们再深度思考一下这个问题,像 DeepSeek 一样。
DeepSeek 团队[2]跟 Kimi 团队[6]一样放弃了那些复杂的训练方法,比如蒙特卡洛树搜索(MCTS)、价值函数(Value Function)以及过程奖励模型(Process Reward Model)。R1-Zero 在做强化学习训练时的奖励信号很简单:一个是答案正确与否——只奖励结果,不关心推理过程;另一个是回复必须遵守 `<think>推理过程</think><answer>答案</answer>` 这种格式,其目的就是让大模型践行我之前的文章[7]中曾提到的那条通用的认知原则 think-before-acting。

DeepSeek-R1-Zero 的思维模板
这是强化学习环境能给到大模型的所有关键信息,大模型仅基于这两个简单的奖励信号去探索,就能逐步学习到长思考能力和各种复杂的思维策略。这让人不可思议,怎么做到的?
R1-Zero 的训练过程跟 AlphaGo 不一样。AlphaGo 你只需要告诉它一些围棋的基本规则,然后它就可以通过自我博弈,达到可以战胜世界冠军的水平。R1-Zero 的强化学习训练不是从一些基本规则开始的,它是从一个 671B 参数规模的基础大模型(DeepSeek-V3-Base)开始训练的。所以有人把这两者做类比,我觉得并不完全合适。
基础大模型里已经有什么,它已经能做什么?这是一个值得思考的问题。
大模型的所有智能来源于数据,让我们去数据中找找。我在 OpenWebMath[8] 这个数据集中简单搜索了一下,找到了 5 个跟“啊哈时刻”中那道数学题目直接相关的网页[9][10][11][12][13],

help, so hard! [8]
这些网页里有原始题目,有人类给出的标准答案和解题过程,而且有很多种解题方案(也有人类面对数学题的无助呐喊[笑])。这些语料有极大概率已经进入到 DeepSeek-V3-Base 的训练数据集里了[14]。
也就是说,R1-Zero 在解这道题的时候,并不是完全从零开始,并不是完全自主探索,预训练阶段已经为它提供了相当多的知识积累。在强化学习训练阶段,它需要做的是将这些知识(包括陈述性、程序性以及策略性知识)重新组合并应用起来。
所以,强化学习到底有多自主?大模型有多少能力是从零“涌现”出来的?AI 又在多大程度上脱离了对人类生成数据的依赖而成为能自主学习的智能体?
大模型是如何思考的?
大模型是如何思考的?让我们再深度思考一下这个问题。
早在 2021 年,就有论文展示了基础模型已经具有一定的 CoT 能力了[16]。你通过一句简单的元提示词,就能引导出大模型的一步一步思考的能力。注意,这是在 GPT-3 上做的实验,GPT-3 没有经过微调,也没有经过与人类偏好对齐的强化训练,就是基础模型。基础模型就已经具备 CoT 能力了。

只是这种 CoT 能力是隐性的,需要你利用元提示词去引导。后来大部分模型厂商都通过微调将这种能力内化到模型内部了。现在你再去问大模型这种问题,它会自动根据需求调用这种思维能力,一步一步思考后再回答。
很多人被 DeepSeek 的深度思考惊艳到,一部分原因是它在使用一种拟人化的语气进行思考,仿佛是一个人的内心独白。要模拟这种内心独白极其简单,只需要一句提示词就够了:
Present your thinking process not as a bullet list, but rather as a VERY VERY LONG and IN-DEPTH internal monologue.把这句提示词丢给 Claude,Claude 就可以给你表演内心戏了:

我们可以再发挥一下想象。我们完全可以要求 Claude 遵循 think-before-acting 原则[7],使用 <think> 和 <answer> 标签组织回复,甚至可以通过元提示词要求 Claude 使用 Kimi 论文中提炼出的那四种通用思维策略(规划、评估、反思、探索)来思考。这完全是可行的,感兴趣的朋友可以去尝试一下。
这是不是说明,像 Claude Sonnet 这种“非推理模型”已经具备了深度思考和推理能力?
对比一下,你会发现这些所谓“非推理模型”已经具备了“深度思考”的潜力,但是你也可以明显感受到它们的“深度思考”与 DeepSeek-R1 这类模型的“深度思考”的差异——它们的思考强度完全不够。一个明显表现就是它们的 CoT 明显比较短,即思考的时长不够。这也是为什么我更喜欢 Kimi 论文里 “Short-CoT 模型” vs ”Long-CoT 模型”的区分逻辑,这里没有“推理”和“非推理”的区分。
强化学习强化了基础模型和微调后的模型。DeepSeek 团队在前期的一个强化学习实验中讨论过“强化学习为什么有效”这个问题[15],他们对比了微调模型和强化模型在 Pass@K 指标和 Maj@K 指标下的表现,发现强化学习只会增强 Maj@K 指标,而不会增强 Pass@K 指标。就像是射击练习,你本来射 10 次可以中一次,经过强化后,射 10 次可能有更多次中把;如果你本来无法射中靶子,强化学习也没办法让你射中靶子[17]。DeepSeek 团队当时的假设是:“强化学习通过使输出分布更加稳健来提升模型的整体性能,换言之,这种改进应归功于从 TopK 候选中提升正确响应的能力,而非源自模型基础能力的根本性提升[15]。”
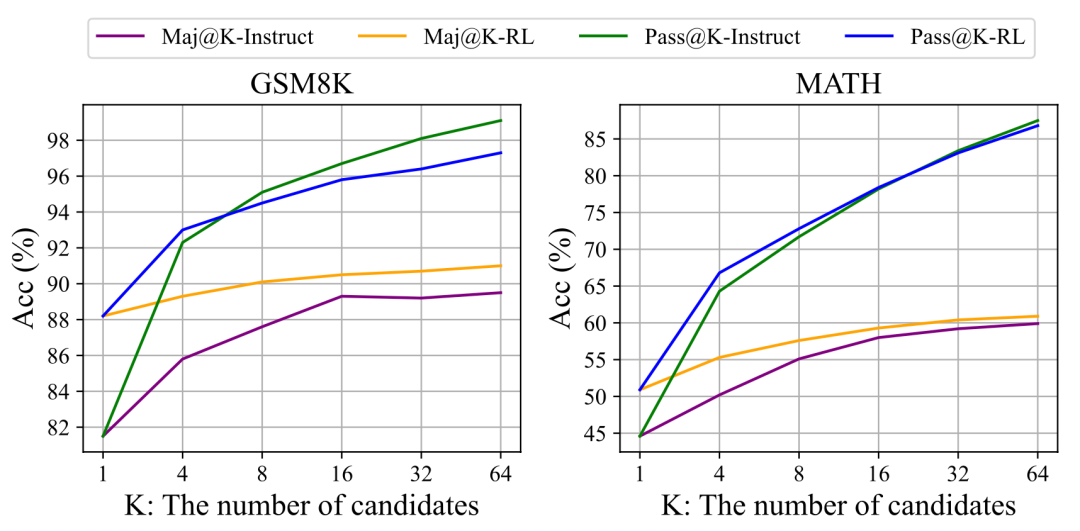
Maj@K 和 Pass@K 指标对比[15]
这也符合直觉。因为强化学习的逻辑就是如果采样到正确的结果,就通过奖励来强化这一结果,让大模型更容易生成正确的结果。能被强化的前提是,基础模型或者微调后的模型至少有能力生成正确的结果。
这是不是就是说,深度思考能力已经潜藏在基础模型和微调后的模型内了,强化学习只是把它激发出来并加强了?
看到这里,你可能开始觉得 DeepSeek 的那个“啊哈时刻”好像也没那么啊哈了。
如果你观察细致,在实际使用 DeepSeek-R1 这类推理模型的过程中,你可以发现它们依然有很多思维上的缺陷。它们依然有幻觉,有些情况甚至更严重,而且更隐蔽了。它们的知识应用水平非常低,明明语料中已经有匹配的内容了,它们还是会绕圈子(R1-Zero 那个例子)。它们的思维链过于冗长,思维过程混乱,Token 效能太低,有些情况下表现甚至不如 Short-CoT 模型。它们的自我评估很不靠谱,有时候会莫名其妙抛弃一个更好的方案(甚至是已经成功的方案),转向另一个方案(这是缺少过程监督导致的)。它们会重复探索相同的路径,甚至会陷入死循环。
这些缺陷有多少是无法“根治”的,有多少是可以优化的,又有多少是不成为题的,今年我们就可以看到推进结果。
AI,让我欢喜让我忧
(写最后这一部分的时候神经网络的温度有点高~)
机器有机器的限制,人类也有人类自身的限制。
尽管我们已经知道,大模型只是在通过语言符号模拟人类的推理过程,但我们对语言能将 AI 带到何处还是缺乏想象,就像我们经由凡身肉体,难以想象千里眼和顺风耳的极限。
尽管我们已经知道,基础大模型只学习到了语料中的一些统计规律,它只是在预测下一个词(NTP,Next Token Prediction),但是架不住他们把整个互联网的数据都用去训练大模型,把基础模型搞成千亿参数规模。
尽管我们已经知道,有监督的微调(SFT,Supervised Fine-Tuning) 只是在让大模型记答案,但是架不住他们花大价钱请博士生和北大中文系的人去做数据标注[18]。
尽管我们已经知道,强化学习就是不断试错,就是“题海战略”——对人类来说是比较低级的、相当低效的学习方式。但是架不住大模型每个问题都可以错几千次,机器人每走一步可以摔倒上万次,最终它们会学会(一切?)。
NTP 不需要过脑子,SFT 是在背答案,RL 是大模型自己做练习,并根据反馈修正自身。RL 不同于前两者,我们可以看到大模型在 RL 过程中,不仅仅是在执行 NTP 这样的基础运算,而是在学着重新组合和应用一些重要的思维策略。这表示 RL 已经将大模型的思维能力带到了一个新的抽象层级,the real learning begins。
更关键的是,这三种训练模式是可以叠加组合的,DeepSeek-R1 就是 NTP+ SFT+RL 组合配方训练出的产物。这种模式上限在哪里?目前我们还看不到。
说实话,这几天我看论文的心情是既有忧惧又有欣喜。
让我忧惧的是:
现在 AI 都可以做到“三思而后答”了,可是很大一部分人,甚至都不愿意对自己看到、听到、读到的东西“二思”。人会从三思的人,变成二思的人,变成一思的人,最终变成不思的人吗?笛卡尔说:我思故我在。或许,这才是人类真正面临的存在主义危机。
在人与 AI 的协作关系中,人类是会变得越来越重要、越来越富有创造力,还是会在生产关系中逐渐被边缘化,变得越来越无能,这是一个严肃的问题。如果走向第二种极端,好的情况是《机器人瓦力》,坏的情况就可能是《黑客帝国》。

《机器人瓦力》剧照
让我欣喜的是:
我找到了一个新乐子——研究 AI 的思维过程。
我告诉自己,作为人类一定不要放弃思维的乐趣。

《3年A班》剧照
[1] 大模型的智能来源于数据,不代表数据就直接决定了大模型的智能。大模型的智能与数据之间的关系会随着 AI 的演进而变得越来越复杂。
[2] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (https://arxiv.org/abs/2501.12948)
[3] R1-Zero 与大家线上使用的 R1 版不同,R1 是经过微调又经过强化学习训练出的版本。你可以把 R1-Zero 想象成 EVA 零号机,R1 是初号机。
[4] 虽然这个范式是 OpenAI 领的头,Kimi 也做出了与 DeepSeek 同样出色的工作,但是 ta 们都没有像 DeekSeek 一样在学术圈甚至公众视野中带来如此巨大的全球震撼力。我觉得一个核心原因是 DeepSeek 的模型开源了。既然这些公司的核心诉求是逐“利”,那“名”自然就要让给别人了,这很公平。
[5] https://openai.com/index/learning-to-reason-with-llms/
[6] Kimi k1.5: Scaling Reinforcement Learning with LLMs (https://arxiv.org/abs/2501.12599)
[7] 我从顶级的提示词工程团队(Anthropic)那里学到了什么
[8] https://huggingface.co/datasets/open-web-math/open-web-math
[9] https://math.stackexchange.com/questions/2966454/how-to-prove-sqrt-a-sqrt-a-sqrt-a-sqrt-a-sqrt-a-sqrt-a-ldots
[10] https://web2.0calc.com/questions/help-so-hard
[11] https://www.cut-the-knot.org/arithmetic/algebra/AnEquationInRadicals.shtml
[12] https://math.stackexchange.com/questions/2563567/heuristics-when-doing-heavy-algebraic-manipulation-sqrta-sqrtax-x
[13] https://artofproblemsolving.com/wiki/index.php?title=1981_AHSME_Problems/Problem_29&diff=128561
[14] DeepSeek 团队曾构建过一个 DeepSeekMath 语料库[15],这个数学语料库是从 Common Crawl 中提炼出来的,而用作提炼数据的模型则是基于 OpenWebMath[7] 这个数据集训练的。
[15] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (https://arxiv.org/abs/2402.03300)
[16] 提示词编程?面向大语言模型编程?
[17] Pass@K 考察的是最低标准,至少一个正确即可,Maj@K 是多数正确才算成功。
[18] 小道消息,来自:逐句讲解 DeepSeek-R1、Kimi K1.5、OpenAI o1 技术报告——“最优美的算法最干净” (https://www.xiaoyuzhoufm.com/episode/67a1b697247d51713c868367?s=eyJ1IjogIjYxZDdjODQ2MmNiZDdjMDE3NjllMTMyYyJ9)


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











