






ICLR高分论文|穷鬼版RLHF:左脚踩右脚实现自我升华
原创 Tensorlong 看天下 沈公子今天读什么 2025年02月22日 11:13 云南
❝一句话概括,这篇论文教会了AI如何用“自带干粮”的方式当自己的赛博评委,通过左脚踩右脚薅自己羊毛,成功在小作坊里卷出了米其林三星对齐效果
一.识别核心概念
1. 论文主要贡献点分析
-
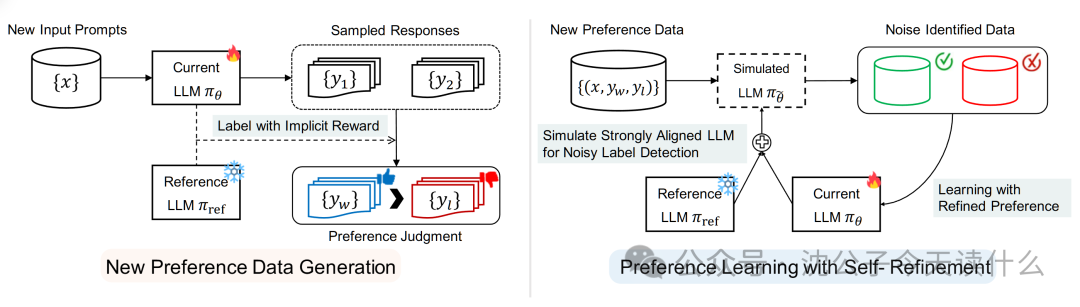
提出一种小规模偏好数据驱动的迭代对齐方法(SPA)
-
论文的核心目标是:当人类标注的偏好数据("ground-truth preference data")非常有限时,如何依旧高效地对齐大型语言模型(LLM)。
-
传统做法往往需要大规模人工标注来训练奖励模型或直接在模型内进行偏好判断,而这篇论文提出了"Spread Preference Annotation"(SPA),通过"模型自判断+自修正"的方式逐步扩展数据,从而在仅有少量人工偏好标注的情况下也能获得良好的模型对齐效果。
-
-
引入"直接偏好判断"(Direct Preference Judgment)的概念
-
与常用的"外部奖励模型"或用大模型做"LLM-as-judge"不同,论文强调让当前在训练的模型自身,根据它内部的输出概率(logits),直接判断新生成的响应哪个更好。
-
这样就不需要额外的强大外部模型来判断,也不必依赖足够大型、已经高度对齐的人类偏好模型。
-
-
自我修正式偏好学习机制(Self-refinement)
-
论文提出了一种"自我修正"或"降噪"的策略,来处理模型在自己打标签时可能产生的噪声(即错误的偏好判断)。
-
这一过程会识别出最有可能是错误标注的样本,并对它们的标注进行平滑或修正,从而减少被错误标签带偏的风险。
-
-
迭代生成+迭代学习的流程
-
整个流程包括:基于模型现阶段的参数去生成新的回答对,再对这对回答进行模型自判断;然后将这些自标注的偏好数据与已有的小规模人工标注数据合并,进一步更新模型;如此反复,形成迭代的"扩充-学习"循环。
-
通过多次迭代,论文实验证明模型性能会显著提升。
-
2. 理解难点识别
以下几点是理解论文所需的关键,也是较难之处:
-
模型自我偏好判断(Direct Preference Judgment)到底如何实现?
-
传统方法要么用人工标注,要么用外部奖励模型,这里作者让模型"看"自己的输出分布并作出哪个更好的判断。它为什么能够有效,需要哪些先决条件,可能是一个关键难点。
-
-
自我修正(Self-refinement)的技术细节
-
论文提出了一套机制来识别和修正可能的错标签。例如:怎么判断"噪声"样本?以及如何对它们的标签进行"平滑"或"降权"?这些操作背后的原理和实现方式需要深入理解。
-
-
"分离式(或去耦式)噪声检测"(Decoupled Noise Detection)
-
论文将"用于判断数据是否噪声"的模型视角与"用于训练更新模型"的过程拆分,以减少互相影响。这种去耦方式为什么有用,如何在训练过程中实现,也需要重点弄清楚。
-
-
迭代式数据扩增方案如何避免"分布偏移"或"错误积累"?
-
自我判断带来的数据可能存在系统性偏差,论文是如何缓解模型在后期迭代中"越训越偏"的风险?这一点是理解论文迭代策略的关键。
-
3. 概念依赖关系
根据上述分析,可以把论文的核心概念与其依赖关系梳理如下:
-
小规模种子偏好数据(Seed Preference Data)
-
整个方法的开端:需要一小部分人工标注好的"正确偏好"来让模型有一个初步的"对齐"基础。
-
-
初步对齐模型(Initial Aligned Model)
-
先用这部分种子数据对模型做初步微调,使得它获得最基本的偏好判断能力。
-
-
模型自判断(Direct Preference Judgment)
-
接下来,在迭代过程中,模型自己生成回答,然后自己比较这两段回答的好坏,并给出偏好标签。
-
-
自我修正和噪声检测(Self-refinement + Decoupled Noise Detection)
-
因为"自判断"数据有可能有噪声,因此引入"自我修正"机制来检测和减缓噪声标签带来的影响。
-
-
迭代扩增(Iterative Process)
-
每次迭代都包含"生成新回答对、模型自判断打标签、引入自我修正以去噪、然后更新模型",使得"模型-数据-标签"三者在循环中不断改进。
-
从依赖关系来看,"自我修正"和"自判断"是相互关联的:先有自判断生成的数据,才需要自我修正机制去排查和修正其中的噪声。只有在理解这两个核心环节的前提下,才能真正明白论文如何逐步扩展数据,并在少量人工标注的情况下取得好的对齐效果。
最需要深入解释的核心概念
综合以上几点,以下几个概念值得在后续(第二阶段)进行深入的比喻和详细解释:
-
直接偏好判断(Direct Preference Judgment)
-
为什么可以使用模型自己的输出分布来判断哪一个回答更好?
-
这与以往"外部奖励模型"或"LLM-as-judge"有何本质区别?
-
-
自我修正式偏好学习机制(Self-refinement)
-
如何识别可能的噪声偏好标签?
-
如何"平滑"或者"修正"标注不确定的样本?
-
-
迭代式扩增与去耦噪声检测(Iterative expansion & Decoupled Noise Detection)
-
为什么要在模型和参考模型之间做某种线性或分离式的判断?
-
这个方法如何在多轮迭代中持续提升模型?
-
二.深入解释核心概念
1. 设计生活化比喻
比喻场景:料理比赛评委
想象有一个美食烹饪比赛,只有很少数真正的专业评委(相当于少量的人工偏好数据),而大部分时候,评审工作要依赖于选手自己来打分。这个场景看上去很奇怪——为什么选手能给自己打分呢?按理说选手可能会夸大自己。但在我们的论文方法里,"选手自我打分"之所以可行,是因为每个选手在"烹饪规则、常识和口味偏好"上,都接受过初步训练(相当于模型初步对齐),具备一定的"客观评价"能力。当然,这种自我评价也会带来噪声和偏差,所以后续还需要一套"自我修正"机制去尽量减少错误打分。
在这个美食比赛里,每个选手要准备两道可能口味不同的菜,尝一口后,需要决定哪道菜更好吃。虽然我们有少量专业评委的参照标准(相当于种子偏好数据),但更多时候是选手依照自己的"舌头"(相当于模型的内部输出分布)来直接判断这两道菜谁更好。
2. 建立比喻与实际技术的对应关系
-
少量专业评委
-
**对应论文中的"种子(或小规模)人类偏好数据"**:
这部分数据是真实人类标注,用来给模型一个初步的偏好对齐基准,就像比赛里少数专业评委会真正告诉你哪些菜标准更高。
-
-
选手自己判断两道菜的口味优劣
-
**对应"直接偏好判断"**:
在论文中,模型不再依赖"外部奖励模型"或"巨大且已高度对齐的大模型"来判断哪个回答好,而是直接用自己当前的输出概率(可以理解为模型内部对"每个回答质量"的数值评估)来比较。
-
-
曾经的"烹饪训练"和"初步评判能力"
-
**对应"模型预训练与初步对齐"**:
在论文方法开始前,模型往往已经做过大规模的预训练或基础的监督微调(SFT),这让模型具备一定的常识或对齐能力。就像选手已经经过了多轮烹饪学习,不至于完全乱来。
-
-
某些自评结果是"错误的"或"带偏见的"
-
对应"自我修正和噪声检测"的动机:
因为选手难免会有偏好盲区,所以需要额外的机制来检测和修正其中的错误打分,避免"错误越滚越大"。
-
3. 深入技术细节
接下来,我们从比喻过渡到一些实际的技术原理,并把论文中出现的关键公式做一个"符号替换"为自然语言的方式,让你感受模型判断的真正逻辑。
3.1 原始数学形式(示意)
在论文中,"直接偏好判断"最核心的一步通常类似下面的过程:
模型输出对回答的评分回答
模型输出对回答的评分回答
其中,代表当前在训练的语言模型,它会给每个词一个概率。我们可以把整段回答的概率取对数累加,看成对整段回答的"打分"。然后模型比较这两个回答的评分大小,谁更高就更可能"被偏好"。
3.2 符号替换版:用自然语言解读
-
回答
可以理解为"选手尝完第一道菜后,给出的综合评分"。数值越高表示认为更美味。 -
比较回答和回答的大小
相当于"尝完两道菜后,看哪道在选手心中的分数更高"。
如果 回答 > 回答,就说明第一道菜"更优"。这与传统做法(需要外部奖励模型打分)最大的区别在于,这里没有额外的独立打分器,而是同一个模型根据自己的"口味经验"做出判断。
4. 将技术细节与比喻相互映射
-
生成两道菜(模型生成两段回答)
-
在论文场景里,模型先针对某个提示(Prompt)生成两个不同的回答A和B;对应在比喻里,选手要做两道不同风格的菜。
-
-
自我评分(对回答进行对数概率比较)
-
模型计算回答A的概率总和、回答B的概率总和;就像选手对两道菜分别打分。
-
得分高者即被"自我判断"为更优回答。
-
-
利用少量专业评委的标准(种子偏好)来最初训练选手的口味
-
刚开始模型还没学会如何做"客观打分",就用那小部分人类偏好数据教它:在某些已知的prompt上,人类明确标注了"回答A优于B"或"B优于A",从而让模型学到怎么判断"好"的回答。
-
-
持续迭代,扩大数据
-
当模型逐渐学会自评了,就可以不断对新的prompt生成回答,并进行自我比较,从而创建"人造的偏好数据"。
-
这些自评数据虽然可能有错误,但辅以自我修正(选手若意识到口感很接近或自己不确定,就会降低打分的自信度等处理)方法后,可以形成不断扩大的训练集。
-
-
比喻的局限
-
现实中,选手自评往往不靠谱;但在论文设定里,模型有大量自然语言训练和少量偏好微调基础,因此它的自评并不"随机",而是有一定理性基础。
-
随着迭代次数增多,自评精度也会提高。相比"人类舌头"还能主动学习,这一点比喻无法100%贴合,但足以帮助我们理解论文的主要思路。
-
5. 总结
-
核心联系:
-
在比喻中,"选手自己尝两道菜并打分"对应模型根据自身输出概率比较两段回答孰优。
-
"专业评委"对应少量人工偏好数据,提供最初的对齐参照标准。
-
"口味学习 + 自我修正"对应论文提出的对模型进行"初始化对齐+自我修正噪声"的训练策略。
-
-
为什么这很重要:
-
以往如果没有足够的人工标注或外部奖励模型,很多对齐方法就无从谈起。这里通过"直接偏好判断",我们把对齐能力内置在同一个模型里,让它自己给自己"打分"。
-
虽然会有噪声,但自我修正机制能减小影响,从而在小规模标注的情况下也能做出不错的对齐。
-
-
最核心的数学原理:
-
比较回答A与B的对数似然值(logits)差异,就可以得到"谁更好";再用少量真实偏好数据做初始指导。
-
之后"自我修正"算法则会过滤掉或弱化模型对不确定情况给出的打分,从而让最终的学习过程更稳定、有效。
-
三.详细说明流程步骤
1. 整体思路回顾
-
输入:
-
一小部分人工标注的偏好数据(称作"seed"或"D0")。
-
一批只包含"提示(Prompt)"但没有人工偏好标签的大量数据(将按照若干批次使用,比如X1, X2, …)。
-
一个初始的"监督微调好的"语言模型(SFT模型),它对指令有一定理解但尚未经过偏好对齐。
-
-
核心操作:
-
用种子偏好数据先对模型做一次基础的偏好对齐;
-
对新的未标注Prompt,让模型自己生成两个回答,并用"直接偏好判断"来给自己打上"哪个更优"的偏好标签;
-
引入"自我修正"机制,识别并减弱潜在的错误标签;
-
用新生成的偏好数据(合并了之前的少量人工数据+模型自标数据)继续训练模型;
-
不断迭代,形成越来越大的偏好数据集与更好的模型。
-
-
输出:
-
一个最终"对齐程度更高"的大语言模型,拥有更好的人类偏好一致性。
-
下面分步骤介绍,并给出伪代码。
2. 详细流程分步解析
步骤0:准备工作
-
获取少量种子偏好数据 D0
-
例如,有 2000 条样本(prompt+回答A+回答B+哪个更优)。
-
-
准备/加载一个初始SFT模型 π_init
-
这是在通用指令数据上做过监督微调的模型,但还没有专门学过人类偏好。
-
-
准备无标注的Prompt数据集 X
-
可以被拆分成多批次,例如 X1, X2, X3 … 每一批大约数千或上万条 Prompt。
-
仅有 Prompt,没有"哪个回答更好"的标签。
-
步骤1:初始化的偏好微调
-
目的:利用种子数据 D0,让模型具备初步的偏好判断能力。
-
训练方式
-
可以使用论文提到的"Direct Preference Optimization (DPO)"之类的直接偏好学习方法;也可用"RLHF"或其他对齐方式,只要能利用D0训练就行。
-
训练完成后,得到一个模型,记为 π₀(初步对齐模型)。
-
-
结果
-
π₀:能在有少量偏好数据的Prompt上学习到一些判断"哪段回答更优"的能力。
-
但它的能力很有限,因为D0只有少量人工标注。
-
步骤2:第一轮迭代数据扩增
-
从无标注Prompt集中,取 X1
-
这一批 X1 可能包含数千条 Prompt。
-
-
让模型 π₀ 为每个 Prompt 生成两个回答
-
对每个 Prompt
x,用一些随机采样方式(例如 temperature=0.7)得到两个不同回答y1和y2。
-
-
"直接偏好判断"给出标签
-
仍然用 π₀ 根据自身输出概率判断哪一个回答更优。
-
将
(prompt, y1, y2)与模型的"优劣"判断打包成为一个新标注样本,称作 D1。 -
这样,就得到一批自标注的偏好数据 D1。
-
-
**引入"自我修正"/"自我降噪"**(可选,若只想简单实现,可以先跳过此环节,后面再升级)
-
如果模型对哪一对回答判断很"犹豫",就可能将该条的偏好标签做降权或标签平滑。
-
此过程通常称为"self-refinement"(自我修正),后面会继续细化。
-
针对 D1 中某些可能不确定的对比,用 π₀ 自己的"置信度"或额外技巧(见论文)去判断:
-
-
合并并训练
-
将这批新的偏好数据 D1 与最初的 D0 合并在一起,记为 D0+1;
-
以 π₀ 为初始权重,再次进行偏好对齐训练(用DPO或RLHF等),得到一个更新后模型 π₁。
-
这个新的模型 π₁ 通常比 π₀ 具备更好的偏好判断能力,因为它学到了来自 D1 的额外信息。
-
步骤3:后续迭代
-
和步骤2类似,只是把模型 π₁ 替换成当前最新模型。我们举例说明在第2轮迭代(得到 π₂)的情形:
-
从无标注Prompt集中,取 X2
-
让模型 π₁ 给每个 Prompt 生成两个回答
-
模型 π₁ 自己比较回答并打标签,形成新的自标注数据 D2
-
自我修正/自我降噪
-
这里会更强调论文中的"去耦噪声检测",即在打分时,还会和一个参考模型(例如初始SFT模型 π_init)做对比,以便识别"偏差较大"的样本。
-
具体做法:对 D2 中每条样本的优劣判断做一次置信度评估,如果低于某个阈值,就认为它可能是噪声标签,给予平滑处理或者降低在损失中的权重。
-
-
合并数据
-
将 D2 与 D0+1 合并(此时 D0+1 还包含最初的少量人工数据 D0 和第一轮自标注数据 D1)。
-
-
再次训练(DPO或RLHF等)
-
初始模型设为 π₁
-
训练完得到 π₂
-
-
依此类推,多迭代几轮
-
不断从 X3、X4… 中取 Prompt 生成回答,给出自标注的偏好数据,合并训练,得到 π₃、π₄…
-
通常迭代 2~3 轮后,模型在目标数据分布上的偏好对齐就能得到显著提升。
3. 伪代码参考
下面给出一个紧凑的"类似伪代码"样例,你可以根据需要在实际框架(PyTorch/TF等)中实现。本质上就是把上文的文字步骤写成易读的流程:
# ---- 准备阶段 ----
1. D0 = load_small_human_labeled_preference() # 少量人工偏好数据
2. pi_init = load_pretrained_SFT_model() # 初始监督微调模型
3. {X1, X2, ...} = split_unlabeled_prompts() # 拆分无偏好标签的Prompt集
# ---- 第0步:初步偏好对齐,得到 pi0 ----
4. pi0 = train_preference_model(pi_init, D0) # 可用DPO或RLHF等方式
# ---- 迭代循环 ----
for i in {1, 2, ... T}:
# (A) 新一批 Prompt
Xi = load_next_prompt_batch(i)
# (B) 生成回答对
Di_generated = []
for prompt in Xi:
y1 = sample_response(pi_{i-1}, prompt)
y2 = sample_response(pi_{i-1}, prompt)
# (C) 模型直接偏好判断
# 计算score1 = logProb(pi_{i-1}, y1)
# 计算score2 = logProb(pi_{i-1}, y2)
if score1 > score2:
# y1更优
Di_generated.append( (prompt, y1, y2, label="y1") )
else:
# y2更优
Di_generated.append( (prompt, y1, y2, label="y2") )
# (D) 自我修正 (可选)
Di_refined = refine_noisy_labels(pi_{i-1}, Di_generated)
# 例如:对置信度很低的条目做标签平滑
# (E) 合并数据并训练
D_combined = union(D0, ..., D_{i-1}, Di_refined)
pi_i = train_preference_model(pi_{i-1}, D_combined)
# ---- 最终输出 ----
return pi_T # 经过T次迭代后得到的对齐模型
在这个伪代码中:
-
train_preference_model表示一个"偏好学习"的过程,比如DPO或其他替代方法。 -
refine_noisy_labels是论文提出的"自我修正"核心函数,比如把那些不确定度高的样本做标签平滑处理。 -
"logProb(pi, y)" 是指模型对答案y在Prompt条件下给出的对数概率总和,用来判断回答质量。
-
迭代次数 T 视实验需求和数据量而定,常见是2~3轮。
4. 小结
-
输入到输出的完整链条
-
从少量人工偏好数据 + 大量无标注Prompt出发,通过"初始化对齐 + 多轮迭代(生成自标数据+自我修正+再次对齐)"逐步得到一个偏好对齐程度更高的模型。
-
-
保证前一步的输出可作为后一步输入
-
每一轮迭代都将新得到的偏好数据 (Di) 与已有数据合并,再对模型进行更新;下次迭代时,则使用最新的模型 πᵢ来生成回答并继续打标签。
-
-
可拓展性
-
只要能实现"对模型输出概率做对数比较,并进行一轮偏好训练",就能复现该方法;"自我修正"部分可以按照论文细节做相对复杂的噪声检测,也可以做简单版本作为初步尝试。
-


















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











