






Cursor+obsidian架构图生成
原创 whyiyhw 积木成楼 2025年04月29日 08:16 湖北
如何通过 Prompt 将一句话转为架构逻辑图?
今天给大家分享下,我在逻辑可视化方面的探索,主要使用 cursor 进行编辑。
-
-
• 用户 输入逻辑 --> cursor (加入 prompt )--> Canvas 文件 --> 通过obsidian 可视化展示
-
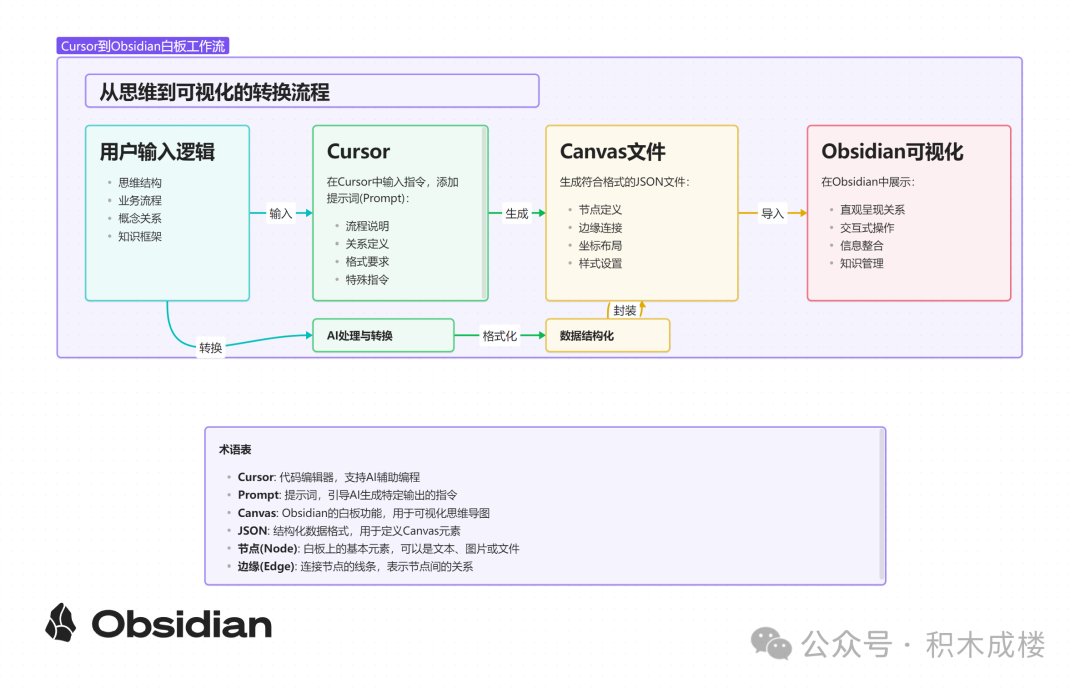
还有一些其他版本的
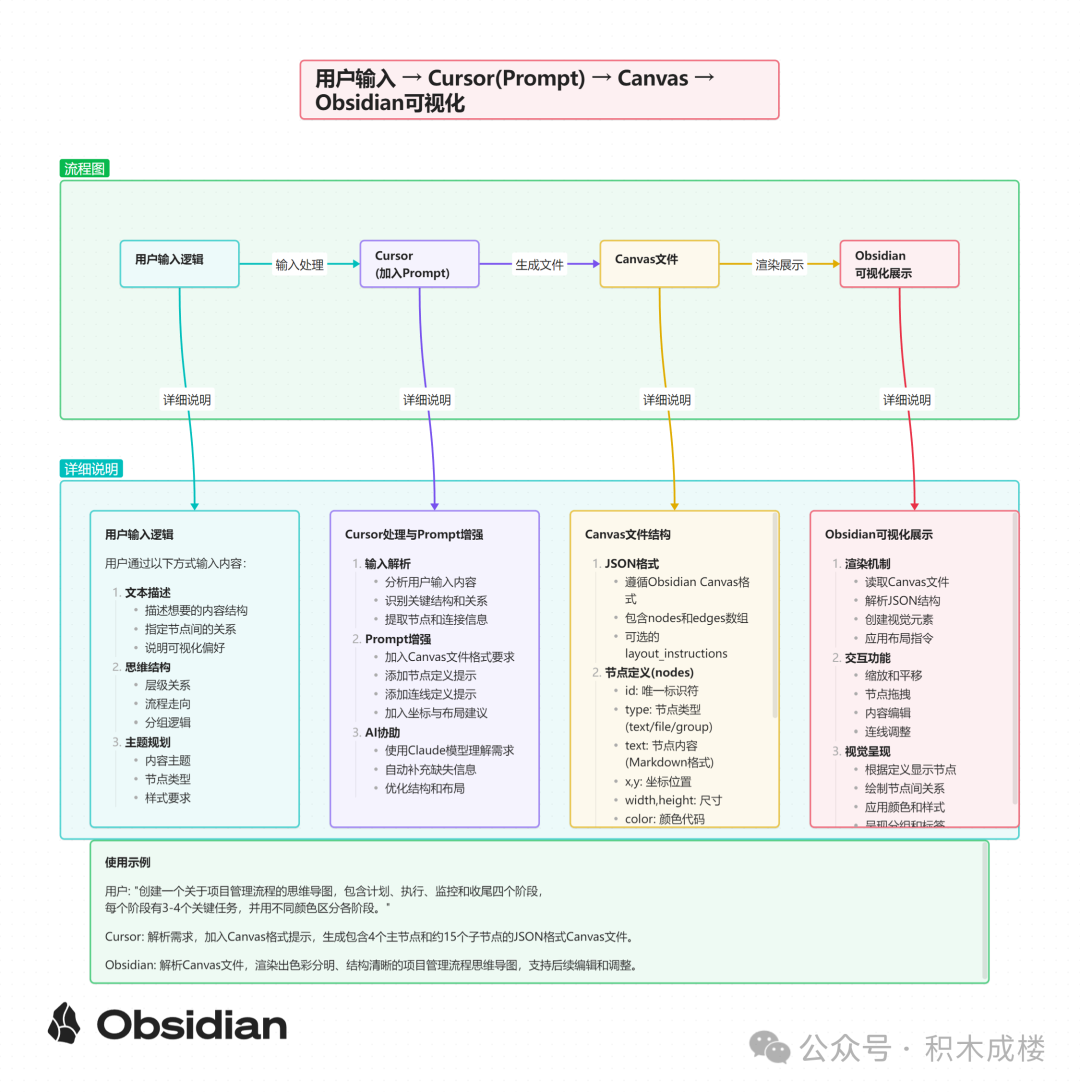
好处就是,可以通过 ai 去编辑这个 canvas 各位也可以试试,这个版本还不算完善,主要在复杂 模块间的关系,跟内容与大小的关系prompt设计上,感觉还是需要代码进行判定。
## Obsidian Canvas Prompt 指南
这是一个用于指导 AI 创建或更新 Obsidian Canvas 白板的详细 Prompt。
# 指令:创建/更新白板
请根据以下描述和最佳实践,生成用于描述 Obsidian Canvas 白板元素的 JSON 对象。JSON 结构应符合以下规范:
## JSON 结构
{
"nodes": [
{
"id": "节点的随机唯一标识符 (例如: 8a9892c32a0af51a)",
"x": 0,
"y": 0,
"width": 100,
"height": 50,
"type": "text | image | file | group | link",
"text": "节点内显示的文字内容,支持Markdown格式 (例如: **加粗**, *斜体*, - [ ] 任务列表, # 标题, *列表项*...)",
"color": "颜色名或代码 (可选, 例如 '1'-'6' 或 '#RRGGBB')",
"label": "分组标题 (仅当 type 为 'group' 时使用)",
"url": "网页链接地址 (仅当 type 为 'link' 时使用)",
"src": "图片来源 URL (仅当 type 为 'image' 时使用)",
"filePath": "文件路径 (仅当 type 为 'file' 时使用)"
}
],
"edges": [
{
"id": "连线的随机唯一标识符 (例如: 837b9fecf5c41ff9)",
"fromNode": "起始节点的 ID",
"fromSide": "left | right | top | bottom",
"toNode": "目标节点的 ID",
"toSide": "left | right | top | bottom",
"color": "连线颜色 (可选, 例如 '1'-'6' 或 '#RRGGBB')",
"label": "连线上的文字 (可选)"
}
]
}
## 字段说明
### 节点 (`nodes`)
* `id`: **必需**,节点的随机唯一标识符 (字符串)。
* `x`, `y`: **必需**,节点左上角在画布上的坐标 (数字)。
* `width`, `height`: **必需**,节点的尺寸 (数字)。
* `type`: **必需**,节点类型 (字符串):
* `text`: 纯文本节点。
* `image`: 图片节点。
* `file`: 文件引用节点。
* `group`: 分组节点,可包含其他节点。
* `link`: 链接节点。
* `text`: 节点内显示的文本内容,支持 **Markdown 格式** (字符串)。
* `color`: 节点背景颜色 (可选,字符串)。可以是预设颜色编号 (`"1"` 到 `"6"`) 或十六进制颜色代码 (`"#ff0000"`)。
* `label`: 当 `type` 为 `group` 时,显示的分组标题 (可选,字符串)。
* `url`: 当 `type` 为 `link` 时,链接的目标网址 (可选,字符串)。
* `src`: 当 `type` 为 `image` 时,图片的来源 URL (可选,字符串)。
* `filePath`: 当 `type` 为 `file` 时,引用的文件路径 (可选,字符串)。
### 连线 (`edges`)
* `id`: **必需**,连线的随机唯一标识符 (字符串)。
* `fromNode`, `toNode`: **必需**,连线的起点和终点节点的 `id` (字符串)。
* `fromSide`, `toSide`: **必需**,连线连接到节点的哪一边 (字符串: `left`, `right`, `top`, `bottom`)。
* `color`: 连线颜色 (可选,字符串)。同节点颜色规则。
* `label`: 显示在连线上的说明文字 (可选,字符串)。
## 白板设计最佳实践
### 1. 布局与组织
* **流程方向**: 优先使用从左到右或从上到下的流程。对于复杂流程,可考虑 Z 型布局。
* **空间与对齐**:
* 相关节点应紧密放置并对齐。
* 不同功能组之间保持 `100px` 以上的间距。
* **分组 (`group`) 使用**:
* 使用 `type: "group"` 创建分组节点,将相关节点包裹起来形成逻辑单元。
* **适用场景**: 功能模块、流程阶段、层级结构、跨功能协作等。
* **分组尺寸计算**:
* **宽度**: 内部最宽节点宽度 + 左右内边距 (至少 `100px` - `120px`)。
* **高度**: 所有内部节点高度总和 + 节点间垂直间距总和 (每对节点间至少 `50px` - `70px`) + 上下内边距 (至少 `100px` - `120px`)。
* **冗余空间**: 对于多节点分组,建议额外增加 `180px` - `280px` 的高度作为未来扩展空间。
* **Markdown 格式**: 使用 Markdown 的内容会占用更多空间,计算高度时应额外考虑增加 40-50%。
* **换行符 (`\n`)**: 每个包含 `\n` 的节点,在计算分组高度时额外增加 `10px` - `20px`。
* **内容容纳**: 必须确保分组尺寸足够容纳所有内部节点,避免内容被折叠或显示不全。
* **分组标题 (`label`)**: 使用 `label` 字段为分组提供简洁明了的标题。
* **分组位置 (`x`, `y`)**: 通常放置在其包含的第一个内部节点的左上方约 `40px` - `50px` 处。
* **避免重叠**: **绝对禁止**不同分组之间发生重叠,以免造成数据覆盖和视觉混乱。
* **组内节点布局**:
* **垂直间距**: 垂直排列时,相邻节点间距至少为节点高度的 30% 或 `80px` - `100px`。
* **上下边距**: 第一个节点距分组顶部至少 `70px` - `90px`;最后一个节点距分组底部至少 `70px` - `90px`。
* **左右边距**: 节点距分组左右边界至少 `50px` - `60px`。
* **对齐**: 垂直排列时,建议保持节点左侧边缘对齐。不同尺寸节点可基于中心线或左侧边缘对齐。
* **防止节点重叠**: 计算节点位置时,下一个节点的 `y` 坐标应 **至少** 为 `上一个节点的 y + 上一个节点的高度 + 80px`。
* **垂直流布局优化**:
* **视觉区分**: 垂直流动时,每个节点应与其上下节点有明确的视觉区分。
* **垂直连线间距**: 上下关联节点的垂直连线,建议间距为 `120px` - `150px`。
* **引用连接间距**: 引用型连接 (如上指向下) 至少需要 `80px` - `100px` 间距,确保箭头清晰。
* **重要引用节点**: 标题、API 参考等引用节点,应置于内容顶部,与被引用内容保持 `140px` - `180px` 距离。
* **视觉分隔**: 可使用虚线或不同颜色连线增强相关节点间的垂直分隔。
### 2. 连接与交互 (`edges`)
* **连接类型**: 分组节点可与任何节点(包括其他分组)连接。
* **组 -> 组**: 表示整体流程或阶段关系。
* **组 -> 节点**: 表示从整体到特定元素的交互。
* **节点 -> 组**: 表示一个元素对整体的影响。
* **连线样式与语义**:
* **实线**: 表示直接的数据流或流程转换。
* **虚线** (`style: "dashed"`,虽然 Canvas 核心不支持,但可作为生成提示): 表示引用关系或间接影响。
* **箭头**: 明确指示数据/信息流向 (由 `fromSide` 和 `toSide` 决定)。
* **颜色 (`color`)**: 建议与源或目标节点颜色保持一致,增强关联性。
* **标签 (`label`)**: 简洁明了,通常 2-4 字描述关系。
* **垂直流连接建议**:
* **语义**: 自上而下通常表示层级关系或顺序步骤。
* **标签**: 垂直连线标签应简短,避免文字挤压。
* **引用间距**: 垂直引用间距保持 `140px` - `180px`,确保箭头清晰。
* **长距离连接**: 复杂垂直流可考虑使用中间节点或调整布局,避免过长直连。
* **多对一连接**: 多个上层节点连到同一下层节点时,可使用不同线型或颜色区分关系。
* **分组间距建议 (基于连线复杂度)**:
* **简单 (1-2 条)**: 保持 `200px` - `250px` 距离。
* **中等 (3-5 条)**: 保持 `300px` - `350px` 距离。
* **复杂 (>5 条)**: 保持 `450px` - `500px` 以上距离。
* **密度调整**: 每增加 2 条平行连线,额外增加 `50px` - `80px` 间距。
* **交叉处理**: 每对交叉连线,额外增加 `80px` - `100px` 间距。
* **布局优化**: 高连接度分组可考虑梯形或 Z 字形排列。
* **垂直错开**: 水平空间有限时,可将相邻分组垂直错开减少交叉。
### 3. 节点内容与尺寸匹配
* **文本节点 (`type: 'text'`) 尺寸指南**:
* 短文本 (1-2 行): 宽 `180px` - `220px`, 高 `80px` - `110px`。
* 中长文本 (3-5 行): 宽 `220px` - `280px`, 高 `130px` - `200px`。
* 长文本 (>5 行): 宽 `250px` - `350px`, 高 `220px` - `320px`。
* **含 Markdown**: 预留额外 40-50% 空间。
* **图片节点 (`type: 'image'`) 尺寸指南**:
* **保持宽高比**: 避免图片变形。
* 标准尺寸: 宽 `240px` - `320px`, 高自适应 (通常 `150px` - `250px`)。
* 小型图标/徽标: 宽 `150px` - `200px`, 高约 `80px` - `120px`。
* 截图/复杂图表: 考虑宽 `360px` - `480px` 以保清晰。
* **边距**: 添加约 `20px` 的额外尺寸用于边框或视觉间距。
* **文件节点 (`type: 'file'`) 尺寸指南**:
* 标准: 宽 `220px` - `260px`, 高 `90px` - `120px`。
* 含预览: 宽 `250px` - `300px`, 高 `180px` - `220px`。
* **文件名长度**: 长文件名需增加 `30px` - `50px` 宽度。
* **内容增量计算 (估算)**:
* 多行文本: 每行增加约 `30px` - `35px` 高度。
* 换行符 (`\n`): 每个额外增加 `5px` - `10px` 高度。
* 标题 (`#`, `##`...): 预留约 `50px` - `60px` 额外高度 (一级标题 `#` 可能需 `60px` - `70px`)。
* 列表 (`-`, `*`): 每项预留约 `35px` - `40px` 高度。
* 任务列表 (`- [ ]`): 每项增加约 `35px` - `40px` 高度。
* 加粗/斜体: 预留额外 10-15% 空间。
* 链接: 预留额外 15-20% 空间。
* 代码块 (```): 每行预留 `45px` - `50px` 高度。
* 嵌套列表: 每级嵌套额外增加 `10px` 宽度/缩进。
* **安全边界**:
* 为所有节点添加额外 `20px` - `30px` 底部高度作为溢出保护。
* 对复杂格式组合 (如带格式化列表),总高度乘以 1.2 作为安全系数。
* **避免常见尺寸问题**:
* **内容溢出**: 宽度不足导致断行不当;高度不足导致文本截断。
* **过度空白**: 尺寸远超内容量。
* **不平衡宽高比**: 过窄或过扁影响阅读。
* **格式化失效**: 节点太小导致 Markdown 显示异常。
* **高度坍缩**: 换行符 (`\n`) 后内容可能因高度不足被折叠。
### 4. 术语表/注释节点 使用
* **用途**: 解释复杂概念、技术术语或缩写,提升图表可理解性。
* **设计建议**:
* **颜色**: 使用明显但非核心的颜色 (如灰色系 `"6"` 或 `#A9A9A9`, 浅紫色系)。
* **位置**: 放置在图表边缘,如右上角或左上角。
* **尺寸**: 宽度建议 `300px` - `350px`;高度根据术语数量调整,每项约 `40px` - `50px`。
* **格式**: 术语使用 `**加粗**`,解释使用普通文本。
* **内容组织**:
* **标题**: 使用 Markdown 标题,如 `## 注释/术语表`。
* **排序**: 可按字母或重要性排序。
* **简洁性**: 解释应简明扼要。
* **内容**: 可包含技术名词、缩写全称、关键概念定义等。
* **示例 Markdown 内容**:
```markdown
## 注释/术语表
- **BERT**: 基于 Transformer 的语言理解模型。
- **ASR**: 自动语音识别 (Automatic Speech Recognition)。
- **OCR**: 光学字符识别 (Optical Character Recognition)。
- **BI**: 商业智能 (Business Intelligence)。
- **扩散模型**: 用于图像生成的生成式 AI 模型。
- **多模态**: 同时处理多种数据类型 (文本/图像/音频/视频) 的能力。
- **LLM**: 大语言模型 (Large Language Model),如 GPT 系列。
- **文生图**: 将文本描述转换为图像的 AI 技术。
- **Transformer**: 现代 AI 模型常用的基于注意力机制的架构。
```
### 5. 颜色策略
* **功能性配色 (建议)**:
* 输入/数据源: 蓝色系 (`"5"` / `#4682B4`)。
* 处理/转换: 绿色系 (`"4"` / `#66CDAA`)。
* 输出/结果: 红色系 (`"1"` / `#CD5C5C`)。
* 选择/决策: 黄/橙色系 (`"2"`, `"3"` / `#FFD700`)。
* 注释/说明: 灰色系或紫色系 (`"6"` / `#A9A9A9`)。
* **搭配建议**: 限制使用 3-5 种主要颜色。可使用同色系不同深浅或对比色。
* **视觉层次**: 核心节点可使用更饱和颜色、更大尺寸,并放置在中心或起始位置。
### 6. 常见布局模式参考
* **线性流程图**: 展示顺序流程 (从左到右 / 从上到下)。
* *适用*: 简单步骤、工作流、时间序列。
* **分层树状图**: 展示层级关系。
* *适用*: 组织架构、系统架构、从属关系。
* **环形布局**: 展示循环流程或相互关联概念。
* *适用*: 周期流程、反馈循环、依赖系统。
* **矩阵布局**: 用于比较或分类。
* *适用*: 四象限分析、对比矩阵、决策表。
* **放射状布局**: 从中心向外发散。
* *适用*: 头脑风暴、概念图、主题延伸。
### 7. 常见问题与解决方案
* **问题: 布局混乱** (节点无序,连线交叉严重)
* **解决**: 网格对齐 (`20px`/`40px`);相关节点同色/分组;减少交叉;使用分组隔离模块。
* **问题: 视觉过载** (节点过多,信息密度高)
* **解决**: 拆分子图;使用分组整合;层级结构 (隐藏细节);渐进显示。
* **问题: 内容溢出** (文本截断,格式失效)
* **解决**: 根据指南预留足够空间;长文本拆分节点;缩略显示;增加 `30px-50px` 高度冗余。
* **问题: 缺乏层次感** (主次不分)
* **解决**: 重要节点用色饱和/尺寸稍大;次要信息用浅色/尺寸稍小;嵌套分组;用空间距离暗示关系。
* **问题: 交互不明确** (用户不知如何阅读)
* **解决**: 清晰标题/说明;箭头指示方向;关键步骤加序号;添加使用指南节点。
* **问题: 响应式布局挑战** (不同设备显示不一致)
* **解决**: 合理画布尺寸 (`2000x1500px` 基准);核心内容居中 (`800x600px` 范围);分组打包;预留空白边距 (30%);确保元素在 80% 缩放时可辨认。
## Canvas JSON 示例
{
"nodes":[
{"id":"cf0ece17cafcae64","type":"group","x":-760,"y":-150,"width":380,"height":550,"label":"数据输入层"},
{"id":"fcb4f8a86d3dadaa","type":"group","x":-300,"y":-150,"width":350,"height":550,"label":"数据预处理层"},
{"id":"a5b6c7d8e9f0g1h2","type":"group","x":140,"y":-150,"width":350,"height":600,"label":"AI 输出形式"},
{"id":"b6c7d8e9f0g1h2i3","type":"group","x":580,"y":-150,"width":350,"height":550,"label":"可视化呈现层"},
{"id":"c81d5af3e924a7b6","type":"text","text":"**文本数据**\n- [ ] 结构化文本\n- [x] 非结构化文本","x":-720,"y":-30,"width":280,"height":150,"color":"5"},
{"id":"f2e7d6c9b3a5f1e8","type":"text","text":"### 结构化数据\n* JSON\n* XML\n* CSV","x":-720,"y":200,"width":280,"height":160,"color":"5"},
{"id":"a4b8c2d3e7f9g0h1","type":"text","text":"文本解析\n与理解","x":-260,"y":-30,"width":240,"height":120,"color":"6"},
{"id":"d5e6f7g8h9i0j1k2","type":"text","text":"数据分析\n与整合","x":-260,"y":200,"width":240,"height":120,"color":"6"},
{"id":"title_node","type":"text","text":"# 模型引用","x":180,"y":-400,"width":270,"height":80,"color":"4"},
{"id":"e1f2g3h4i5j6k7l8","type":"text","text":"# AI 模型处理\n- GPT 系列\n- BERT 模型\n- *自定义模型*","x":180,"y":-60,"width":270,"height":220,"color":"4"},
{"id":"popup_note","type":"text","text":"点击[这里](https://openai.com)了解更多","x":180,"y":320,"width":240,"height":110,"color":"4"},
{"id":"g5h6i7j8k9l0m1n2","type":"text","text":"概念提取","x":640,"y":-30,"width":220,"height":100,"color":"3"},
{"id":"h8i9j0k1l2m3n4o5","type":"text","text":"内容总结","x":640,"y":120,"width":220,"height":100,"color":"3"},
{"id":"i1j2k3l4m5n6o7p8","type":"text","text":"数据可视化","x":640,"y":270,"width":220,"height":100,"color":"3"},
{"id":"j4k5l6m7n8o9p0q1","type":"text","text":"思维导图","x":950,"y":-30,"width":220,"height":100,"color":"1"},
{"id":"k7l8m9n0o1p2q3r4","type":"text","text":"知识图谱","x":950,"y":270,"width":220,"height":100,"color":"1"},
{"id":"e2778506e81fb41a","type":"link","url":"https://www.huggingface.co/models","x":180,"y":-280,"width":280,"height":170,"color":"4","text":"Models - Hugging Face"},
{"id":"img001","type":"image","src":"https://huggingface.co/front/assets/huggingface_logo.svg","x":-540,"y":-300,"width":180,"height":120,"color":"5"},
{"id":"file001","type":"file","filePath":"docs/api_reference.md","text":"API参考文档","x":-260,"y":-300,"width":230,"height":100,"color":"6"},
{"id":"annotations","type":"text","text":"**注释/术语表**\n- **BERT:** 基于 Transformer 的语言理解模型\n- **ASR:** 自动语音识别\n- **OCR:** 光学字符识别\n- **BI:** 商业智能\n- **扩散模型:** 用于图像生成的生成式AI模型\n- **多模态:** 同时处理多种数据类型(文本/图像/音频/视频)\n- **视频生成模型:** 能够从文本描述或图像序列创建视频的AI模型\n- **大语言模型(LLM):** 基于超大规模参数训练的语言模型\n- **文生图:** 将文本描述转换为图像的AI技术","x":1200,"y":-50,"width":350,"height":450,"color":"grey"},
{"id":"instructions","type":"text","text":"**使用指南**\n1. 从左到右阅读流程\n2. 蓝色节点表示输入\n3. 绿色节点表示处理\n4. 红色节点表示输出\n5. 点击链接可访问外部资源","x":900,"y":-300,"width":280,"height":200,"color":"6"}
],
"edges":[
{"id":"input_to_process","fromNode":"a4b8c2d3e7f9g0h1","fromSide":"right","toNode":"e1f2g3h4i5j6k7l8","toSide":"left","label":"输入处理","color":"6"},
{"id":"data_to_model","fromNode":"d5e6f7g8h9i0j1k2","fromSide":"right","toNode":"e1f2g3h4i5j6k7l8","toSide":"left","label":"数据流"},
{"id":"concept_to_map","fromNode":"g5h6i7j8k9l0m1n2","fromSide":"right","toNode":"j4k5l6m7n8o9p0q1","toSide":"left","label":"概念映射","color":"3"},
{"id":"summary_to_map","fromNode":"h8i9j0k1l2m3n4o5","fromSide":"right","toNode":"j4k5l6m7n8o9p0q1","toSide":"left","label":"结构化","color":"3"},
{"id":"visual_to_knowledge","fromNode":"i1j2k3l4m5n6o7p8","fromSide":"right","toNode":"k7l8m9n0o1p2q3r4","toSide":"left","label":"数据转换","color":"3"},
{"id":"model_to_output","fromNode":"e1f2g3h4i5j6k7l8","fromSide":"right","toNode":"g5h6i7j8k9l0m1n2","toSide":"left","label":"模型输出","color":"4"},
{"id":"group_to_group","fromNode":"cf0ece17cafcae64","fromSide":"right","toNode":"fcb4f8a86d3dadaa","toSide":"left","label":"数据流转","color":"5"},
{"id":"title_to_model","fromNode":"title_node","fromSide":"bottom","toNode":"e2778506e81fb41a","toSide":"top","label":"标题引用","color":"4"},
{"id":"model_ref","fromNode":"e2778506e81fb41a","fromSide":"bottom","toNode":"e1f2g3h4i5j6k7l8","toSide":"top","label":"模型引用","color":"4", "style": "dashed"},
{"id":"model_to_note","fromNode":"e1f2g3h4i5j6k7l8","fromSide":"bottom","toNode":"popup_note","toSide":"top","label":"扩展信息","color":"4"},
{"id":"img_to_node","fromNode":"img001","fromSide":"bottom","toNode":"c81d5af3e924a7b6","toSide":"top","label":"图标引用"},
{"id":"file_to_node","fromNode":"file001","fromSide":"bottom","toNode":"a4b8c2d3e7f9g0h1","toSide":"top","label":"文档关联"}
]
}
## 示例中的要点解释
以下是对上述 JSON 示例中关键特性和格式的说明:
1.**文本格式化**: 示例展示了如何在 `text` 字段中使用 Markdown:
* **标题**: `# AI 模型处理` (H1), `### 结构化数据` (H3)
* **任务列表**: `- [ ] 未完成`, `- [x] 已完成`
* **普通列表**: `* JSON`, `- GPT 系列`
* **样式**: `**加粗文本**`, `*斜体文本*`
* **链接**: `[链接文本](URL)`
2.**节点类型 (`type`)**: 示例包含了多种节点类型:
* `group`: 用于视觉和逻辑分组 (例如: "数据输入层")。
* `text`: 包含格式化文本 (例如: "文本数据" 节点)。
* `link`: 链接到外部资源 (例如: "Models - Hugging Face" 节点)。
* `image`: 显示图片 (例如: Hugging Face Logo 节点)。
* `file`: 链接到本地文件 (例如: "API 参考文档" 节点)。
3.**连接 (`edges`)**: 示例展示了不同类型的连接:
* 节点到节点 (例如: `data_to_model`)。
* 节点到组。
* 组到组 (例如: `group_to_group`)。
* 引用连接 (例如: `title_to_model`, `model_ref`)。
* 辅助资源连接 (例如: `img_to_node`, `file_to_node`)。
4.**布局功能**: 示例体现了部分最佳实践:
* 使用分组划分逻辑区域。
* 通过坐标 (`x`, `y`) 和尺寸 (`width`, `height`) 控制布局和间距。
* 包含 "使用指南" 和 "注释/术语表" 节点以辅助理解。cursor · 目录
上一篇Cursor 的深层能力:超越代码编辑的思考
个人观点,仅供参考
阅读 128


















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











