






国内“最强”具身智能创始团队,发布最强分层端到端VLA模型!
温馨提示:点击下方图片,查看运营团队2025年最新原创报告(共210页)

——
正文:
真正VLA模型来了!
2025年4月27日,拥有国内“最强、科学家密度最高”具身智能创始团队的初创公司【灵初智能】发布了分层端到端VLA+强化学习算法模型Psi-R1,率先攻克了开放场景下的长程复杂任务挑战,开启具身智能新时代。
R1能够让机器人基于Chain of Action Thought(CoAT)框架的自主推理系统,以麻将为场景,在视频中,R1让机器人具备了翻牌、碰杠、算牌、协作等核心能力,展现了机器人在开放环境中的长程灵巧操作能力,达成了30分钟+持续CoAT超长任务时长,同时验证了三重复合交互能力(人-机交互、机-机交互、机-环境交互),体现出VLA的超强推理能力和RL超越人类上限的思考、操作能力。
|
|
|


Psi R1模型同样采取了“快慢脑”的分层架构,其中快脑S1专注操作,慢脑S2专注推理规划;2025年以来,采用双系统架构的VLA模型已成为具身智能领域模型主流,国内外的头部具身智能机器人公司都推出双系统架构的VLA模型。
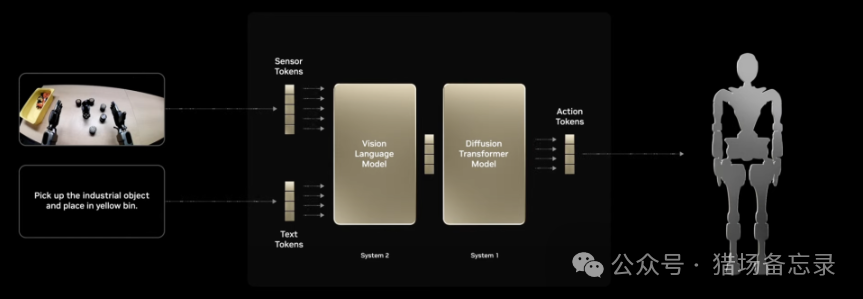
2025年2月20日,国外知名人形机器人独角兽公司【Figure AI】推出自研通用型视觉语言动作(VLA)模型—Helix,并开创性采用双系统架构( 负责“慢思考”,处理高层语义和目标规划S2和负责“快反应”,实时执行和调整动作S1 ),开启双系统架构VLA模型先河,专为高频率、灵巧控制整个人形机器人上半身而设计。
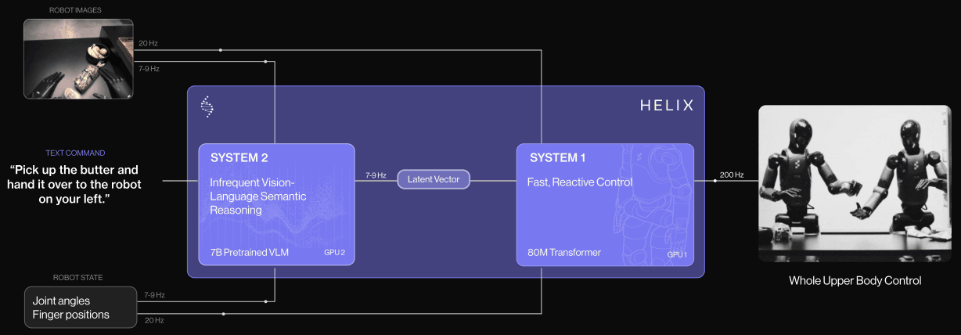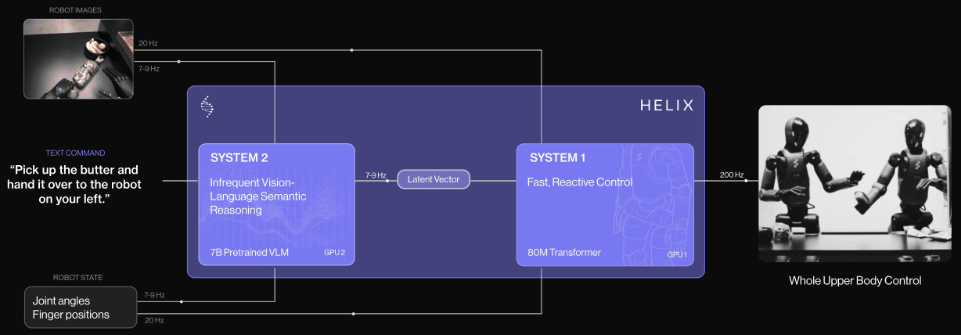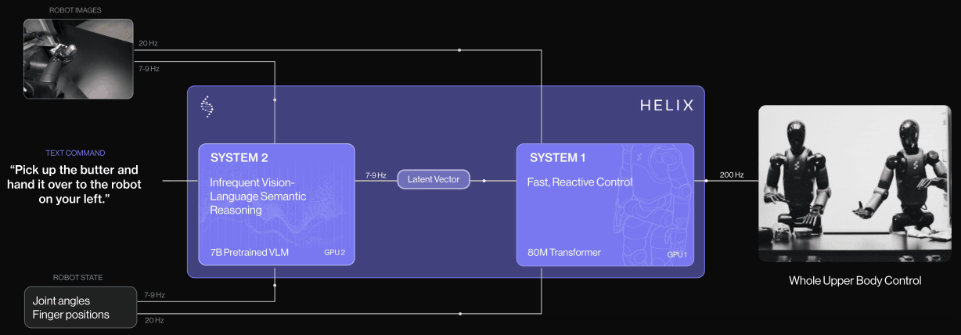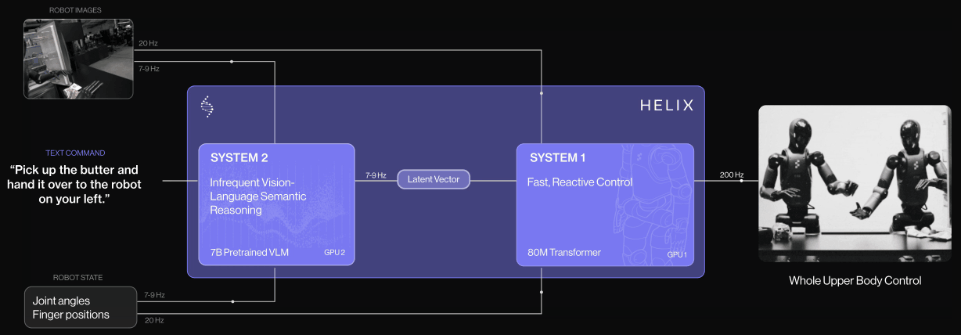
2025年2月26日,作为国外最早提出视觉语言动作(VLA)模型,拥有全球具身智能领域“最强创始团队的具身智能大模型初创公司[Physical Intelligence](简称 PI或 π )基于其公司端到端大模型π0( pi-zero)推出“分层交互式机器人”系统(全称:Hierarchical Interactive Robot ,简称Hi Robot)。
2025年3月18日,GTC2025大会上,英伟达推出全球首个开源、可定制的通用人形推理和技能基础模型GR00T N1,同样采用双系统架构,有快速反应、快思考的“系统1“和深度推理、慢思考的“系统2“。
据[灵初智能]官方介绍,Psi R1不同于Pi,Figure AI等「动作单向决策」机制的VLA模型(仅能完成视觉-语言层面的CoT),R1模型的慢脑输入包括行动Token(Action Tokenizer),通过将Action作为VLA的核心输入端,灵初智能突破了传统具身智能系统“单向决策”的局限性,构建了全球首个支持“动作感知-环境反馈-动态决策”全闭环的VLA模型,实现机器人操作的视觉-语言-动作多模态协同的的CoAT思维链,且已首度成功验证VLA Test-Time Scaling。
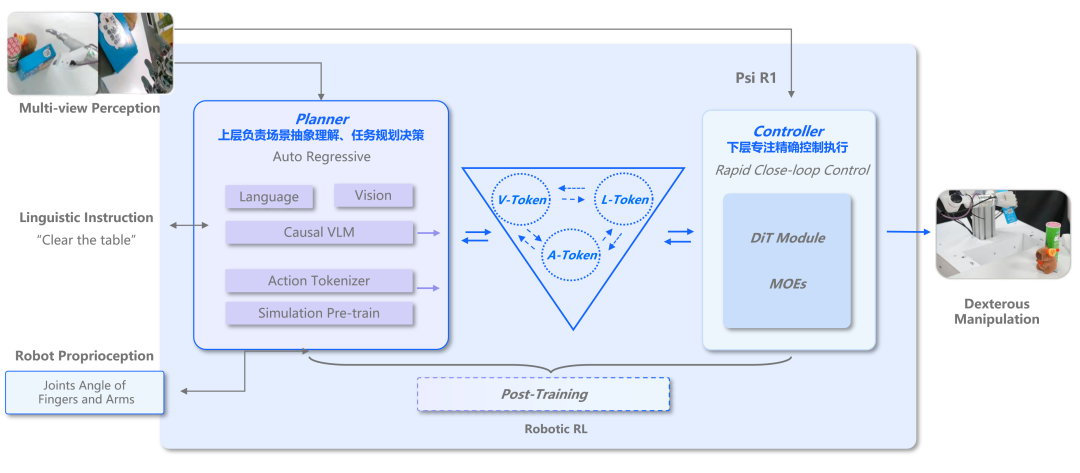
Psi R1模型架构
除了Psi R1模型,灵初智能此次同步发布的,还有拥有16个主动自由度、业内唯一自带深度耦合操作算法的灵巧手PsiBot H1和双臂轮式机器人PsiBot V1。

[灵初智能]是国内具身智能大模型领域初创公司典型代表;2024年12月30日,公司发布首个基于强化学习(RL)的端到端具身模型Psi R0,突破Pick&Place,实现长程任务泛化;2025年3月,发布了升级版的具身模型Psi R0.5,进一步优化了数据训练效率,仅需两小时数据即可实现物品和场景的全面泛化。
【灵初智能】(公司全称:北京灵初智能科技有限公司)于2024年9月北京成立,致力于打造业界领先的通用灵巧操作智能体,被业界称为拥有国内“最强、科学家密度最高”具身智能创始团队的初创公司;技术路线类似刚完成4亿美元融资,投后估值约24亿美元的具身大模型初创公司【Physical Intelligence】(PI)。
创始团队(兼具产业派和学术派,新晋国内具身智能领域最强创始团队):
-
(创始人兼CEO)王启斌博士:在手机(黑莓手机)、智能音箱(Sonos)、机器人领域(云迹科技、京东等)有近20年的成功操盘经验,多次实现产品从定义、开发、到上市、再到全球化0-1-N的产业闭环,是一名深谙机器人商业化落地的“老兵”;
-
(联合创始人)柴晓杰博士:在机器人及无人驾驶领域从业15年,擅长算法、仿真、工程、全栈技术,有L4产品落地的数据闭环经验,是量产经验丰富的研发专家;
-
(联合创始人)陈源培:00后,作为Stanford访问学者,师从Karen Liu和李飞飞教授,曾在全球首次实现利用强化学习在真实世界同时控制双臂、双手多技能操作;
-
(核心初创)温颖副教授:上海交大人工智能学院副教授,研究领域为强化学习,多智能体系统,于2020年在伦敦大学学院获得博士学位;其课题组曾推出多模态决策大模型DB1,实现了对DeepMind通才决策Gato模型的超越,并引入了与现实世界相关的百余个场景任务,为实际业务需求提供了有力工具。
公司与还北京大学成立北大-灵初智能具身灵巧操作联合实验室,由人工智能研究院杨耀东博士担任首席科学家开展横向课题合作;同时,实验室将和梁一韬博士就具身智能体长程任务规划开展课题合作。
由产品老兵带队,携手密度最高的科学家团队,灵初智能组成了7890六边形战队——团队跨越了70、80、90、00的年龄梯度,是一支有技术、懂产品、能落地的全能团队。
融资轮次:

2024年11月13日,公司宣布完成天使轮融资,本轮融资由高瓴创投(GL Ventures)和蓝驰创投(Lanchi Ventures)领投;2024年10月14日,公司完成首次工商变更,新增股东为国内知名人形机器人创企【上海智元新创技术有限公司】。
核心技术:
公司早期一直深耕基于强化学习的全栈能力,从灵巧操作入手在具身智能领域积累技术壁垒,后将扩展至通用泛化操作,其开发的分层端到端模型领先业界,包含Psi-P0规划模型(陈源培与斯坦福大学共同提出)和Psi-C0 控制模型(梁一韬博士);以及首个基于强化学习的端到端具身模型PsiR0。
| Psi - P0模型 | Psi - C0模型 | Psi R0模型 |
|
|
|
|



公司联合创始人陈源培向媒体解释,灵初智能采用强化学习的复合路线,是实现接近或者是超越人类灵巧操作的必经之路,也是攻克“不可达三角”(高泛化性、高鲁棒性和高泛化性)的关键。“
值的注意的是,[灵初智能]是国内最先吃到DeepSeek开源红利的公司,详细解读查看往期文章DeepSeek正重构人形机器人和具身大模型赛道!
未来规划:
目前,灵初智能已初步构建起一套较为完整的产品体系:在硬件维度,打造双手双臂轮式机器人,部分核心硬件系自主研发成果;在软件层面,持续迭代机器人的技能级(指通过机器人能做多少种任务、完成任务的复杂程度和完成任务的质量来划分的一种技能等级),使其具备对上千种物体进行泛化长程操作的能力,能广泛适配于柔性生产等多元场景。
小编视角:公司创始团队兼具产业派和学术派大佬,技术功底雄厚,又懂产业懂场景,还兼备强大的工程化能力以及深厚的商业化实战经验,绝对是具身智能领域一批黑马。
延伸:
小编往期文章:人形机器人发展路线之争:“大脑”优先,还是“运动”优先?有提到随着众多科技大厂入局人形机器人本体赛道,人形机器人初创公司若不具备基础大模型自研能力,结局只能是被收购或者倒闭;因此对于人形机器人初创而言,强大的AI能力将是必需项,自研是唯一出路;因此,资本层面也开始纠偏,具备强大AI能力且同时涉及本体的初创公司已成为资本市场香饽饽,而[灵初智能]就是典型代表企业之一,其他还有[它石智航]、[星海图]、[跨维智能]、[千寻智能]、[智平方]等,此类公司在取得商业化突破的同时也在2025年接连完成大额融资。
具身智能机器人是一个复杂的AI+机器人+自动驾驶的系统性学术+工程问题,小编往期文章:【原创】人形机器人商业化卡点(人形机器人创企九死一生)有从算力、软件算法、数据、硬件、工程化等多层面,详细梳理人形机器人商业化卡点;并提到,大模型的通识理解能力、多级推理能力赋予人形机器人具身智能的核心;嵌入在大模型中的庞大先验知识库&强大的通识理解能力让机器人更好理解泛化任务,且基于思维链的多级推理能力,让人形机器人实现了具身智能;因此,相较于上游机器人核心零部件基本成熟,软件算法进步将是推动人形机器人功能提升和应用场景拓展的关键。
... ... ...
本文仅展示极少部分,接下来,小编将详细盘点具身智能大模型领域,全球初创公司(PI、Skild AI、Covariant、穹彻智能、若愚科技、X Square等)


















 2564
2564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











