







Qwen2-VL笔记
原创 韩松岭 AI-Study-Han 2024年09月27日 14:17 浙江
今天来分享一下最近大火的qwen2-vl模型,据说刷新各个榜单(感觉现在出个模型就是刷榜),看看有哪些特别的地方吧。
一、背景
目前的大型视觉语言模型(LVLM)的相关研究已经很多了,但是标准LVLM将输入图像编码为固定分辨率(例如224×224)进行处理,或者先缩放再填充的方法,但是这种方法会限制模型在不同尺度下捕捉信息的能力,导致高分辨率图像中细节信息的丢失。
目前的LVLM训练的时候通常会冻结类clip的视觉编码器,但是clip能否产生足够的视觉编码信息也值得怀疑,特别是在复杂推理任务和处理图像复杂细节方面。有研究尝试通过在LVLM训练中微调视觉编码器,并且已经取得了改善效果。为了进一步增强模型对不同分辨率的适应能力,我们在LVLM训练过程中引入了动态分辨率训练,在ViT中采用二维旋转位置嵌入(RoPE),使模型能够更好地捕捉不同空间尺度的信息。
视频本质上是一系列的图像帧,文本本质上是一维的,而现实环境则存在于三维空间中。当前模型中使用的一维位置嵌入显著限制了它们有效建模三维空间和时间动态的能力。所以我们开发了多模态旋转位置嵌入(MRoPE),采用独立组件表示时间和空间信息,提高模型理解和与世界互动的能力。
与LLM相比,LVLM在模型大小和数据量方面的scaling研究不足。
所以Qwen2-VL主要提升在:1、在各种分辨率和比例下的视觉理解效果最好;2、能够理解超过20分钟长度的视频;3、具备先进的推理和决策能力,可以与手机、机器人等硬件集成;4、支持多语言。
总的来说,Qwen2-VL的创新包括支持动态分辨率、ViT中采用二维旋转位置嵌入(RoPE)、设计了多模态旋转位置嵌入。
二、模型架构
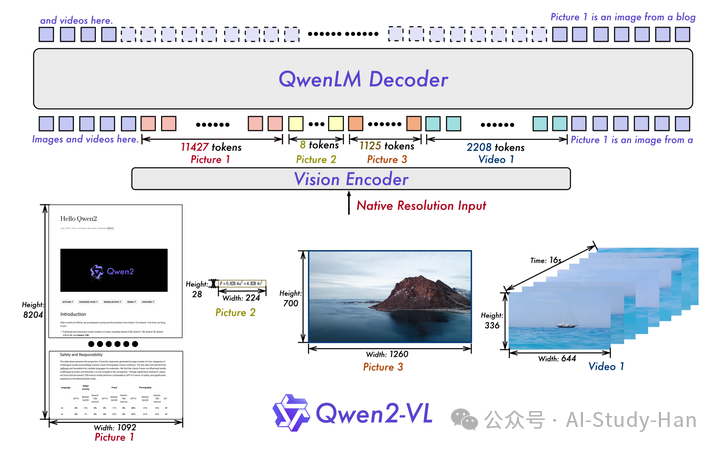
保留了Qwen-VL的模型框架,不同尺寸的模型中视觉编码器保持不变(6.7B的参数量,不理解既然研究scaling,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3629
3629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











