






KAG来了,RAG慌了!
原创 热爱AI的 NLP前沿 2024年10月31日 11:55 湖北
上个周,OpenSPG 开源了KAG 框架,通过利用知识图谱和向量检索的优势,在四个方面双向增强LLM和知识图谱,以解决 RAG 存在的挑战(RAG 存在着向量相似度与知识推理相关性差距大、对知识逻辑(如数值、时间关系、专家规则等)不敏感等问题,这些都阻碍了专业知识服务的落地。)。
整个框架包括kg-builder和kg-solver两部分
-

kg-builder实现了对LLM友好的知识表示,支持无schema约束的信息提取和有schema约束的专业知识构建,并支持图结构与原始文本块之间的互索引表示。
-
kg-solver采用逻辑形式引导的混合求解和推理引擎,包括规划、推理和检索三种类型的运算符,将自然语言问题转化为结合语言和符号的问题求解过程。
知识表示:

KAG参考了DIKW(数据、信息、知识和智慧)的层次结构,将SPG升级为对LLM友好的版本,能够处理非结构化数据、结构化信息和业务专家经验。采用版面分析、知识抽取、属性标化、语义对齐等技术,将原始的业务数据&专家规则融合到统一的业务知识图谱中。
推理步骤:

-
将自然语言问题转换成可执行的逻辑表达式,此处依赖的是项目下的概念建模,可参考黑产挖掘文档。
-
将转换的逻辑表达式提交到 OpenSPG reasoner 执行,得到用户的分类结果。
-
将用户的分类结果进行答案生成。
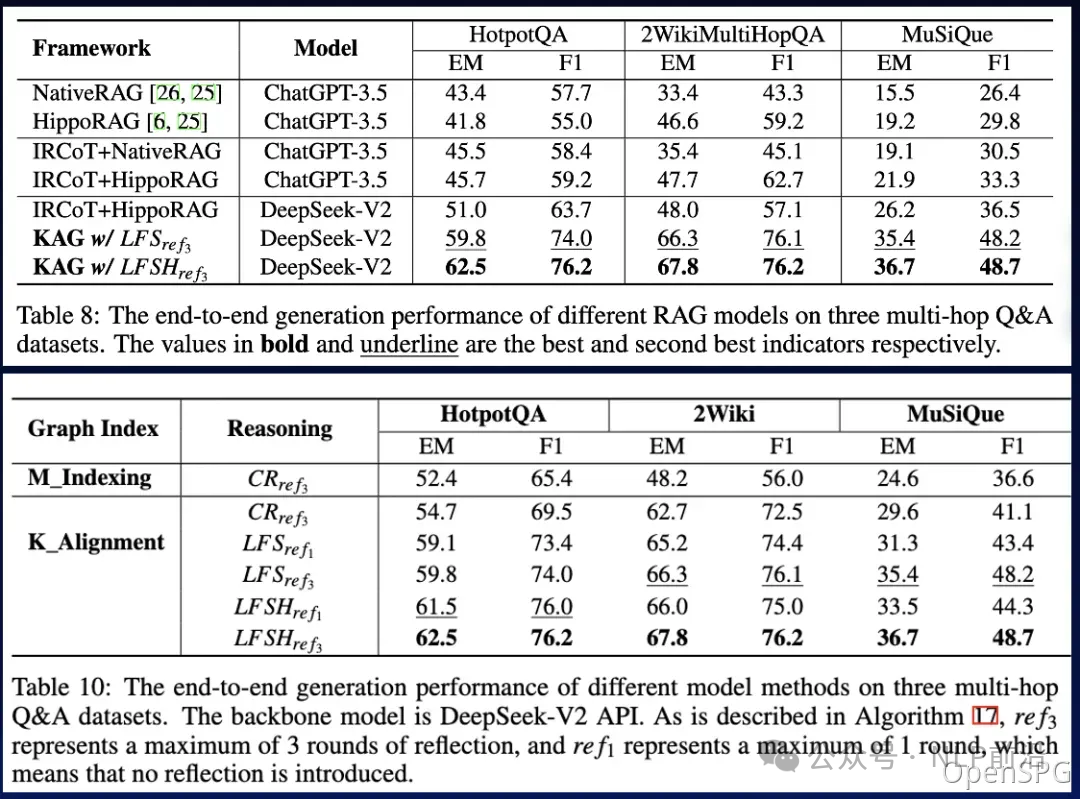
效果如何?
KAG在多跳问答任务中表现优异,相较于其他方法如NaiveRAG、HippoRAG等,在hotpotQA上的F1分数提高了19.6%,在2wiki上的F1分数提高了33.5%。

NLP前沿


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











