







从零预训练LLAMA3的完整指南:一个文件,探索Scaling Law
作者:Mantavers,AGI独角兽
声明:本文只做分享,版权归原作者,来源 青稞AI
原文:https://zhuanlan.zhihu.com/p/706097271
引言
最近,Andrew大神发布了一个全新的视频教程,讲解了从零开始预训练GPT-2的全过程。这个四小时的视频详细介绍了模型的构建、训练数据的加载、评估方法以及在分布式框架下的DDP训练。受到此视频的启发,我决定使用LLaMA3架构,从零开始预训练一个大型语言模型,并对比不同模型参数下模型能力的提升。本文将开源所有相关代码在:
https://github.com/hengjiUSTC/learn-llm/tree/main/pretrain
接下来让我们进入正题。
模型构建和评估
为了能够有一个对照效果,同时保证我们之后自己从零实现的LLaMA模型的正确性,我们首先通过加载Huggingface的官方LLaMA3模型,对模型进行HellaSwag评估。
代码开源在:
https://github.com/hengjiUSTC/learn-llm/blob/main/pretrain/play_with_llama.ipynb
模型加载

hellaswag 评估
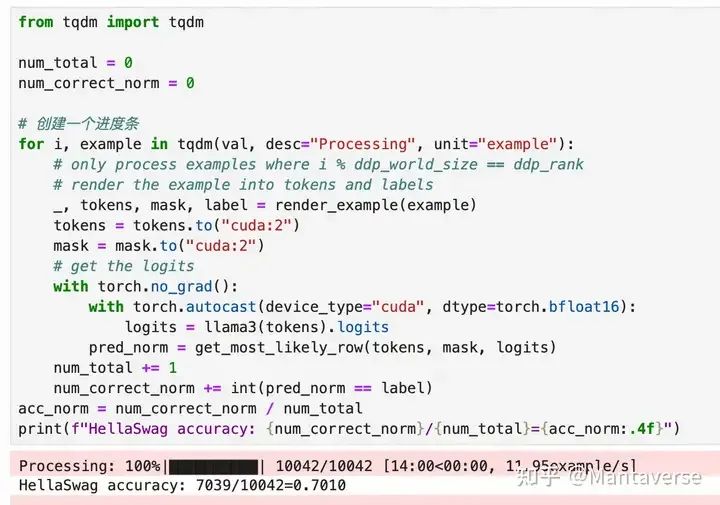
我们可以看到,原始LLaMA3-8B模型的得分是70分。这一结果与官方公开的模型结果基本一致:
https://paperswithcode.com/sota/sentence-completion-on-hellaswag
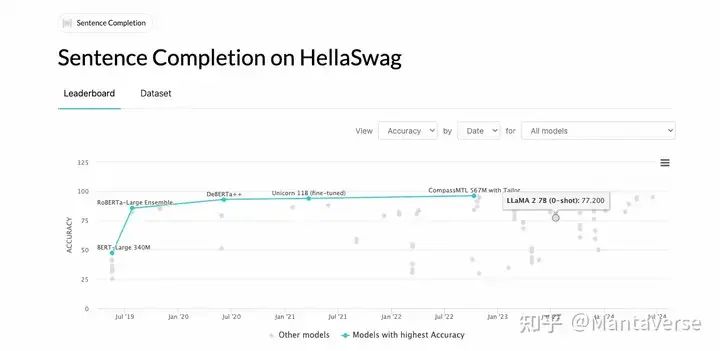
有了这一基准,我们就可以开始从零实现自己的LLaMA模型了。
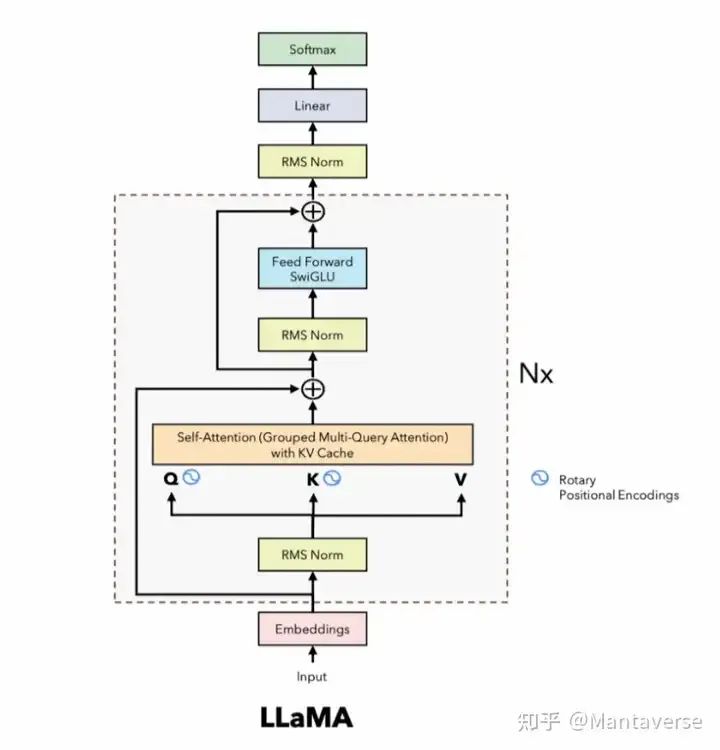
RMSNorm层
RMSNorm(Root Mean Square Normalization)是一种归一化方法,用于稳定和加速训练过程。
-
• 输入:
一个形状为(batch_size, sequence_length, hidden_dim)的张量,表示输入的隐藏状态。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











