






强化学习(Reinforcement Learning, RL)之父理查德·S·萨顿(Richard S. Sutton)是该领域的奠基人之一,他的最主要贡献体现在理论框架的建立、核心算法的提出以及对强化学习思想的系统化推广。以下是对他最主要贡献的详细分析:
一、主要贡献概述
Sutton 的核心贡献可以归纳为以下几个方面:
- 时序差分学习(Temporal-Difference Learning, TD Learning):提出了强化学习中最具影响力的学习方法之一。
- 《强化学习:导论》教科书:与 Andrew Barto 合著的这本书成为强化学习的经典教材,系统化了 RL 的理论与实践。
- 理论与算法的创新:包括 Q-learning 的奠基性工作和对策略梯度方法的贡献。
- 连接 RL 与神经科学:探索了强化学习与人类学习的生物学机制之间的关系。
二、时序差分学习(TD Learning)
背景与意义
在强化学习中,智能体通过与环境交互学习最优策略。传统的蒙特卡洛方法(Monte Carlo Methods)需要等到一个完整的回合结束后才能更新价值估计,而动态规划(Dynamic Programming)则需要完整的环境模型。Sutton 提出的时序差分学习结合了两者的优点,既不需要完整回合,也不需要环境模型,具有更高的灵活性和效率。
形式化定义
时序差分学习的核心思想是基于“预测误差”(prediction error)更新价值函数。例如,TD(0) 算法的更新规则为:
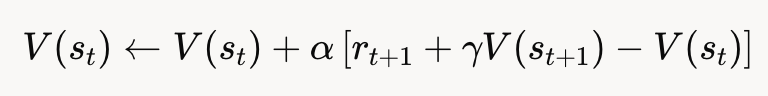
V(st)←V(st)+α[rt+1+γV(st+1)−V(st)]
V(s_t) \leftarrow V(s_t) + \alpha \left[ r_{t+1} + \gamma V(s_{t+1}) - V(s_t) \right]
V(st)←V(st)+α[rt+1+γV(st+1)−V(st)]
其中:
- V(st)V(s_t)V(st) 是状态 sts_tst 的价值估计,
- rt+1r_{t+1}rt+1 是即时奖励,
- γ\gammaγ 是折扣因子,
- α\alphaα 是学习率,
- rt+1+γV(st+1)−V(st) r_{t+1} + \gamma V(s_{t+1}) - V(s_t) rt+1+γV(st+1)−V(st)
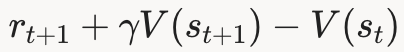 是时序差分误差(TD Error)。
是时序差分误差(TD Error)。
贡献
- 实时学习:TD 允许智能体在每一步交互后立即更新价值估计,而无需等待回合结束。
- 奠定 RL 基础:TD 成为许多后续算法(如 SARSA 和 Q-learning)的基础。
- 理论突破:Sutton 证明了 TD 方法的收敛性,为强化学习的数学基础提供了支持。
三、《强化学习:导论》
内容与影响
Sutton 与 Andrew Barto 合著的《Reinforcement Learning: An Introduction》(第一版 1998 年,第二版 2018 年)是强化学习领域的“圣经”。这本书:
- 系统化地介绍了 RL 的核心概念,如马尔可夫决策过程(MDP)、价值函数、策略评估和优化。
- 详细阐述了 TD 学习、Q-learning 和策略梯度等算法。
- 通过理论与实例结合,帮助研究者和实践者理解 RL 的本质。
贡献
- 教育意义:成为无数学生和研究者的入门教材,推动了 RL 的普及。
- 统一框架:将分散的研究整合成一个连贯的理论体系。
四、Q-learning 的奠基性工作
虽然 Q-learning 的具体算法由 Chris Watkins 在 1989 年提出,但 Sutton 在其发展中起到了关键作用。他通过 TD 学习的思想为 Q-learning 提供了理论支持,并推广了其应用。Q-learning 的更新规则为:
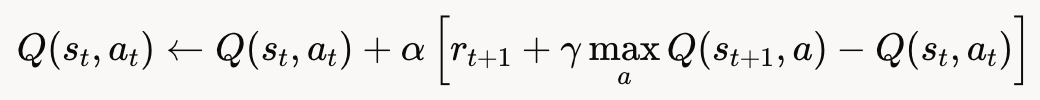
Q(st,at)←Q(st,at)+α[rt+1+γmaxaQ(st+1,a)−Q(st,at)]
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma \max_a Q(s_{t+1}, a) - Q(s_t, a_t) \right]Q(st,at)←Q(st,at)+α[rt+1+γamaxQ(st+1,a)−Q(st,at)]
贡献
- 无模型学习:Q-learning 不需要环境的转移概率模型,适合实际应用。
- 实践推广:Sutton 的研究和教学工作使 Q-learning 成为 RL 中最知名的算法之一。
五、连接 RL 与神经科学
Sutton 还探索了强化学习与人类学习机制的联系。他提出 TD 学习可能与大脑中的多巴胺奖励信号有关,这一假设后来得到了神经科学的实验支持。例如:
- TD 误差
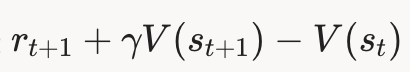 rt+1+γV(st+1)−V(st) r_{t+1} + \gamma V(s_{t+1}) - V(s_t) rt+1+γV(st+1)−V(st) 与多巴胺神经元发放模式高度相似。
rt+1+γV(st+1)−V(st) r_{t+1} + \gamma V(s_{t+1}) - V(s_t) rt+1+γV(st+1)−V(st) 与多巴胺神经元发放模式高度相似。
贡献
- 跨学科影响:将 RL 的数学框架与生物学机制结合,启发了计算神经科学的发展。
- 理论深化:为 RL 提供了更广泛的解释基础。
六、其他贡献
- 策略梯度方法:Sutton 在 1990 年代后期提出了策略梯度理论(如 REINFORCE 算法),为现代深度强化学习(如 PPO 和 A3C)奠定了基础。
- 预测与控制的统一:他强调 RL 不仅是优化控制问题,还涉及预测未来奖励,这推动了通用智能的研究。
七、总结:最主要贡献
如果要选出 Sutton 的“最主要贡献”,**时序差分学习(TD Learning)**无疑是最核心的:
- 理论意义:TD 学习连接了蒙特卡洛方法和动态规划,奠定了现代 RL 的基石。
- 实践影响:它直接启发了 Q-learning、SARSA 和深度 RL(如 DQN)的诞生。
- 广泛应用:从机器人控制到游戏 AI(如 AlphaGo),TD 学习无处不在。
此外,《强化学习:导论》作为知识传播的载体,将 Sutton 的思想推广到全世界,进一步巩固了他的“强化学习之父”地位。
Sutton 的工作不仅定义了强化学习这一领域,还为人工智能的理论和应用开辟了广阔道路。他的贡献是多维度的,但 TD 学习的提出和推广无疑是他最耀眼的成就。


















 3155
3155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











